CNN - Capsule Neural Networks
Capsule
Preface
Geoffrey Hinton (他的团队 ? 挂名论文 ? ) 在2017年提出了一种有别与传统深度网络结构的网络。相对于Convolution层纯参数卷积核表示,Capsule网络的基本结构是胶囊,每个胶囊都有表征一定的空间结构的能力。与其说是胶囊网络,个人对这种网络结构的理解是:向量神经网络。本文是对论文 Dynamic Routing Between Capsules 【arxiv链接🔗】 的总结,也包含了复现论文中遇到过的问题的分析。
问题理解
Capsule网络与普通网络的区别在哪里?普通卷积网络(Convolution)最突出的特点就是,自动特征的提取。但是由于卷积操作的空间对称性,并且在多层卷积后,特征的空间位置信息发生损失,对于需要明确位置信息的特征无法很好地提取。比如说:给定一张人脸照片,如果人脸照片被PS了,五官的空间位置十分奇怪:

对于第二张图像,网络有可能将其分类为“人”,但是实际上这是怪物。而第三章图像,只不过经过了一个旋转,最后的分类结果也可能并不是“人”。我们希望在卷积的处理过程中,仍然保留相对位置信息,但又不想让整个网络变成R-CNN一样的复杂object detection结构。
Capsule结构就是为了解决空间位置信息问题提出的。其基本思想是:Capsule结构可以将图像中的一个物体分解,分解成不同的子结构,而子结构又可以由更加低级的子特征通过空间变换组合得到。
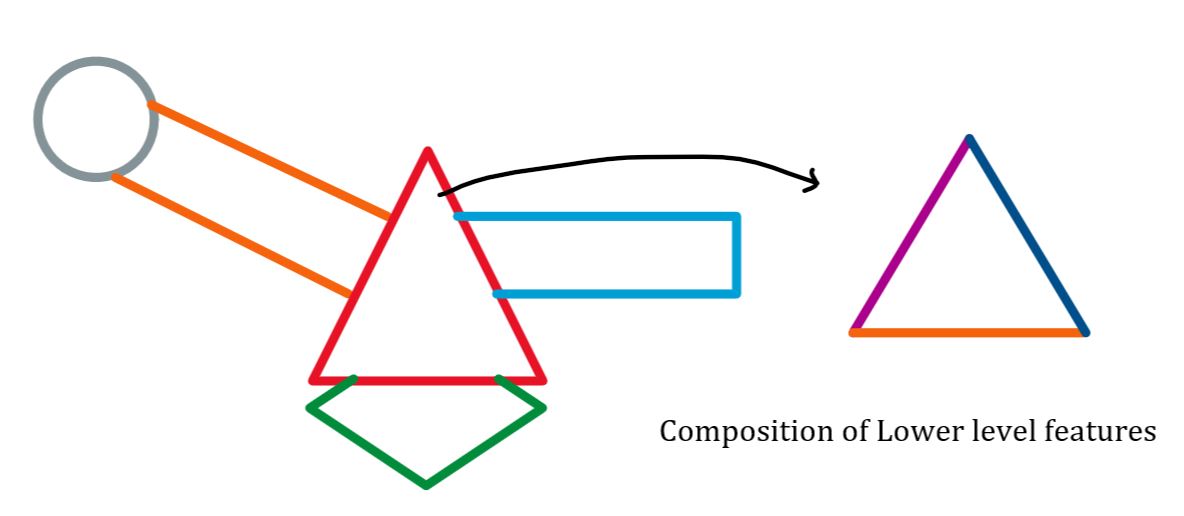
乍一看,和卷积网络貌似很类似,卷积也是低级特征融合到高级特征图中。但Capsule 特征组合依靠的并不是activation函数进行特征融合,其依靠的是“动态路由”方法。
为什么要使用Capsule
Capsule解决的问题
作者在文章中提到:基于HMM-GMM的语音识别方法在神经网络普适之前一直是SOTA方法,但是其致命缺陷是需要的内存空间太大(内存开销是平方级别的复杂度)。RNN网络对于内存的开销则是线性增长级别的,结果会好很多。
CNN相对于全连接层也存在这样的内存开销优势:不同位置的参数是共享的。但是在处理存在有特征的空间变换(平移旋转)时,CNN需要有参数的平移副本,才能实现对不同位置的同一特征进行识别。这让我想起了KCF的平移样本生成。KCF在训练时,会将选中目标的部分进行大量平移,以获得足够的多的训练样本。也就是用内存换取训练结果了,也许这在训练样本极其多时不利于训练,并且随着问题规模的变大,这种方法也并不好。并且CNN这种采用参数平移副本识别不同位置的特征的方式,非常不符合生物视觉原理。作者在文中开始就提到:
Human vision ignores irrelevant details by using a carefully determined sequence of fifixation points to ensure that only a tiny fraction of the optic array is ever processed at the highest resolution.
处理视觉特征的时候,应该使用一定的Attention机制,使用非复制的参数,获得图上的特征,并使用简单的位置表示,应该是获取特征的移动位置而非移动(式)获取特征的位置。这种复制方法,必然导致参数占用内存的增加。CNN能够很好地处理平移特征(因为卷积的滑动窗口特性),但是对于其他的Affine Transformation(仿射变换),处理能力较差。Capsule本身就是带有空间位姿表征的,这样可以防止指数性的参数内存消耗。
Capsule的处理原理
在Preface种说到,Capsule网络实际上是向量神经网络。与一般的标量网络不同,Capsule网络每个输出都是向量,并且向量存在其特定的意义:
- 向量的方向代表了其属性。可以将属性空间每个单独的维度理解为一个坐标轴,在某个方向的分量大小代表了此属性的强度(比如反射率 / intensity / 斜度等等)。也即此向量代表了其在参数空间中的位置。
- 向量的模长代表了概率。反映的是沿着某一方向的特征向量存在的概率。一个Capsule层上的所有胶囊可能对某个特征产生不同的意见,组合特征时希望能让意见一致的概率最大(Routing by agreement)。
每个Capsule表示的向量都是一个个的“instantiated parameter”,表征了一个个小组件(也许这样的小组件没有CNN抽取出来的特征那么抽象)。由于特征是不断融合的,底层特征抽取将会抽取出极其多的小型特征。每一层Capsule网络都是对上一层capsule的融合,第k层的capsule输出需要经过一个投票机制,才能被融合到1第k+1层的网络中去。当第k+1层网络存在输出后,从第k层网络选取出与第k+1层某个capsule输出最类似的一个低层capsule,增大其对应权重。
网络结构与计算细节
向量处理 - 路由原理
激活函数并没有被大量使用在Capsule网络中,由于向量网络并不方便使用activation,而且一般激活函数并不能满足上一节提到的:模长的概率表征特性。在此处,作者设计了一个这样的归一化函数,被称作 “squash”: \[ \begin{equation}\label{equ:squash} \mathbf{v}_{j} = \frac{\Vert \mathbf{s}_j\Vert^2}{1 +\Vert \mathbf{s}_j\Vert^2}\frac{\mathbf{s}_j}{\Vert \mathbf{s}_j\Vert} \end{equation} \] 使用此归一化方法,不仅可以进行长度归一,实际对模长很短的向量存在更大的非线性惩罚。假设第k层网络存在n个capsule filter,第k+1层存在m个capsule filter。那么\(\mathbb{u_{i}}\)就是第k层中第i个filter的输出向量,从第k层第i个结构到第k+1层第j个结构的输出可以使用weight matrix映射: \[ \mathbf{\hat{u}}_{j|i}=\mathbf{W}_{ij}\mathbf{u}_i \] \(\mathbf{W}_{ij}\)用于维数变换,并且需要综合不同的输入得到下一层某个capsule的输入。比如本文中,\(\mathbf{W}_{ij}\)就是8 * 16的矩阵。\(\mathbf{\hat{u}}_{j|i}\)相当于计算出的先验(上层i送到本层j的一个特征向量)。那么: \[ \begin{equation}\label{equ:possi} \mathbf{s}_{j}=\sum_{i=1}^{n}c_{ij}\mathbf{\hat{u}}_{j|i} \end{equation} \] 就是综合所有上一层的输出,得到本层第j个capsule的输入,使用\(\eqref{equ:squash}\)进行非线性归一化得到\(\mathbf{v}_{j}\)。\(c_{ij}\)是概率加权因子,是由\(b_{ij}\)(一个logit值)经过softmax得到的概率。
动态路由过程
内积 - 投票(Agreement)
动态路由部分包含了激活函数的作用,并且在此处取代了normalization的作用。动态路由主要是为了计算\(\mathbf{v}_{j}\),通过迭代的方式求出概率加权因子,本质上是一个数学性的投票过程。开始生成的\(b_{ij}\)都是0,softmax后,所有的输出路径概率都是相同的(均匀分布)。每一个胶囊的输出都相当于是一个带概率(模长)的特征向量prediction。所有的(weight matrix映射的)的组合(概率加权)就是某个高层capsule的输入,高层输出一个归一化后的向量。这个向量只需要与低层的输出向量进行内积即可,内积结果大,表示低层的输出与高层的输出较为符合(两个输出向量的方向较为一致),将会响应增强对应的路由路径。
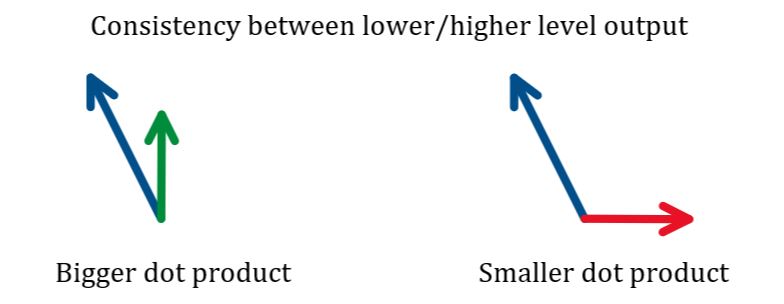
根据几次迭代就可以确定低层/高层的输出一致性关系。
算法流程理解
整个动态路由算法流程如下:

翻译与理解:
- 初始化logit值 为0,使得初始的routing路径概率分布为均匀分布。默认已经获得了经过weight matrix变换的先验输出向量。
- 开始迭代(迭代次数为r,论文中r = 3)
- softmax 将logit变换为:\(c_{i}\),转换成符合概率定义的值。
- 计算本层的加权输入:也就是公式\(\eqref{equ:possi}\)。计算所有低层prediction对应的高层prediction。
- squash操作,非线性归一化。由于内积需要转换成概率,需要squash让模长小于1。
- 根据两层的输出计算内积,得到logits更新值。
注意,只有两个连续的capsule层才会存在动态路由。由于动态路由是对低层 / 高层capsule连接特性的建模,低层prediction与高层prediction相符时,低层capsule更有可能与相应高层capsule相连。
loss设计
Capsule网络在设计时,设计者为了让其拥有同时区分图上多个数字的能力,数字label使用一个长度为10的向量表示(类似one-hot),prediction中,每个位置存分类为对应值的概率。使用的是margin loss(SVM多分类问题使用的就是margin loss),由于鼓励图像多分类输出,margin loss 鼓励输出在0.9(正类)以及0.1(负类)附近,分类使用的margin loss objective为: \[ \begin{equation}\label{equ:margin} L_k=T_k\;max(0, m^{+} - \Vert\mathbf{v}_k\Vert)^2+\lambda(1-T_k)min(0, m^{-} - \Vert\mathbf{v}_k\Vert)^2 \end{equation} \] 提供label时,如果图像中的数字是对应class k,那么\(T_k = 1\),否则为0。可以看出,\(T_k\)不同情况下:
- \(T_k\)为1时,\(L_k=T_k\;max(0, m^{+} - \Vert\mathbf{v}_k\Vert)^2\),需要让输出的概率大概为0.9(\(m^+\)=0.9)
- 反之,\(L_k=\lambda(1-T_k)min(0, m^{-} - \Vert\mathbf{v}_k\Vert)^2\),负类并不要求概率完全为0。为了多数字判定。(\(m^{-}\)=0.1),λ=0.5(影响削弱)
由于这是一个特殊的分类问题,输出会用一个向量表征(长度为16)。那么作者希望,通过16维的特征向量可以重建出原来的数字。作者使用了全连接网络作为decoder:
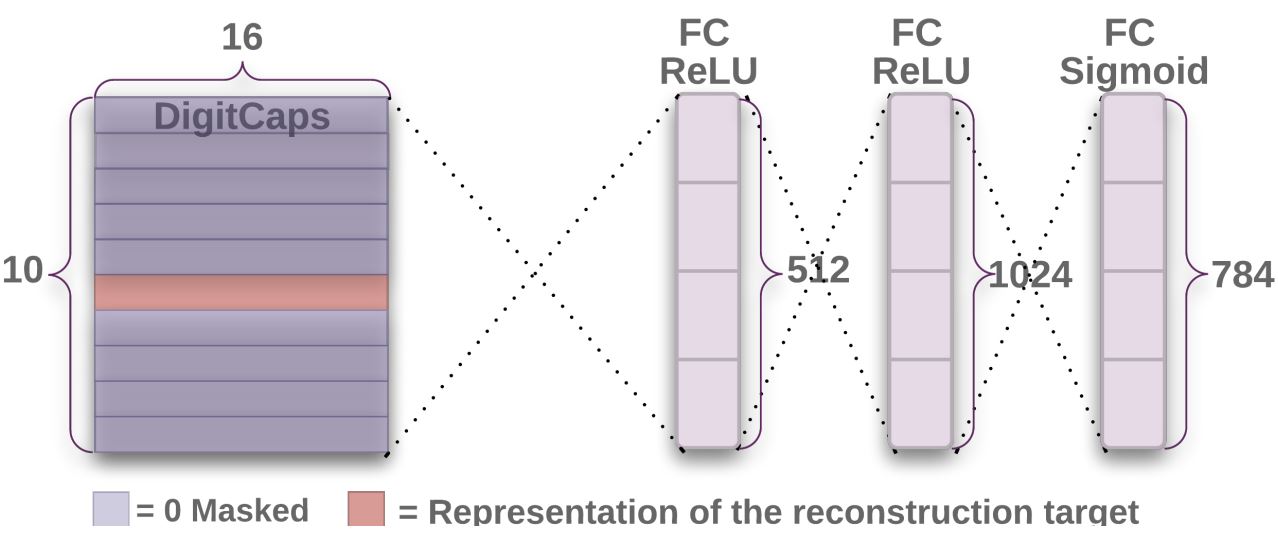
输入层是160维的,但我对这个的理解是:digitCaps存在mask,非预测值的数字将会被乘以0。那么160维的输入意义在哪?为什么不使用16维作为输入呢?
不讨论这个设计问题的情况下,reconstruction会引入loss(需要让),相当于capsuleNN提取了图像的主要特征(PCA类似,只用几个主要特征值恢复图像),但结果与原图应该尽量接近。(这在CycleGAN中也有类似的操作,不过对应的是Cycle Consistency Loss)。Full objective: \[ L_{full}=\sum L_k+0.0005 \times L_{reconstruct} \] 为了不让reconstruction loss造成的优化影响过大,需要将其scale到一个较小的值上。
复现 & 问题
实现CapsNet遇到了比较大的困难,发现自己之前实现的那些网络都比较简单,不需要用到太多的Pytorch tensor特性或是torch的API。于是在本次复现论文时,发现在minibatch情形(高维矩阵计算)下,自己明白逻辑,但是不知如何使用Pytorch完成矩阵计算。显然,将sample一个个计算 / 一维一维计算是可以完成算法的逻辑的,但是这样存在问题:
- slice / index操作 / 分维度计算(小块矩阵运算)容易导致低下的效率以及内存的消耗
- 代码变得臃肿,不符合多维矩阵的API设计初衷
复现尝试了实现网络结构,但是比较失败(我太菜了)。最后我学习了一下别人的实现,对代码进行了细致的注释:[Github Repository🔗:gram-ai/ capsule-networks]
实现上的一些点
在实现过程中,主要是Capsule Layer的实现比较困难:
- nn.ModuleList保存胶囊层的结构,比如保存8个相同的Conv2d Filter。对同一输入处理8次,再使用cat方法连接,产生向量输出。
- nn.Parameter 用于 weight matrix的实现。但我对这个环节产生了一些看法。
- 以上这两种方法都可以自动将参数加入继承了nn.Module的类的
.parameter()中
- 以上这两种方法都可以自动将参数加入继承了nn.Module的类的
- 高维矩阵运算 不知如何进行(开始练运算规则都不知道)
- 输入卷积层的输出结果为:(n, 256, 20, 20),n为batch size
- PrimaryCaps每个胶囊输出的结果应该是:(n, 32, 6, 6, 1)。每个输出需要进行ravel(不同的通道,每个通道内的6 * 6输出),得到(n, 1152, 1) cat之后得到(n, 1152, 8)
- PrimaryCaps 经过weight matrix之后,输出的prior应该是(shape):(10,
n, 1152, 1, 16):
x[None, :, :, None, :] @ self.route_weights[:, None, :, :, :]- x由(n, 1152, 8) 变为(10, n, 1152, 1, 8),weights(10, 1152, 8, 16)变为:(10, n, 1152, 1, 16)
- 剩下的主要问题就是:
- 一些基本API的使用不够熟练,不知道如何进行sum / transpose / max等等。
- 矩阵维度应该如何进行变换,才能让一个batch不被index / slice操作分割处理。何时加入一个维度,何时squeeze?应该是经验不足,API使用不熟练的问题。
个人看法
关于CapsuleNet,个人有以下看法:
- MNIST数据集未免太简单了,这样的实验(虽然作者说,关于Capsule网络只进行浅层的分析):
The aim of this paper is not to explore this whole space but simply to show that one fairly straightforward implementation works well and that dynamic routing helps.
- 我感觉好像Capsule没有太过跳脱出Convolution以及BP结构,算是一种网络结构 / 思想方法上的大(great)创新,但是不能算作(radical)的创新
- CNN baseline是否太菜了一点?太浅了吧才三层?(可能是MNIST数据集不需要太花的结构)
Appendix A - Pytorch
记录一下实现过程中的一些基础但是没有重视的点。希望不要做调库侠。
torch矩阵处理
torch矩阵乘法的规则
- 如果只有2D(size长度为2),需要符合矩阵乘法的尺寸对应要求((m,n) (n, k) -> (m, k))
- 高维矩阵,除了最后两个维度之外,矩阵乘法需要满足:其他维度完全对应 条件。
1 | a = torch.ones((1, 2, 3, 4)) |
也即,高维为矩阵乘法不变,最后两维满足矩阵乘法条件。在Pytorch矩阵运算的时候,可能出现矩阵维度不对应的情况,可能需要通过添加维度的方式来进行维度对应。比如本论文中,两层capsule层中,weight matrix的乘法操作:
在本实现中,训练集batch \(x\)卷积 / PrimaryCaps输出为(n, 32 * 36, 8) (进行了一个ravel操作),\(W\) weight matrix是 8 * 16(右乘)的。那么\(xW\)导致维度不对应(输出需要到(n, 10, 16)),那么需要增加维度。如果将\(x\) 变为(10, n, 32 * 36, 1, 8),\(W\)变为(10, n, 32 * 36, 8, 16) (下划线加粗的是增加的对应维度),就可以让输出为(10, n, 32 * 36, 1, 16)。这恰好符合论文中\(\hat u_{i|j}=W_{ij}u_{ij}\)的定义。在Pytorch中,维度增加使用:
1 | result = x[None, :, :, None, :] @ W[:, None, :, :, :] |
None用于增加维度。
torch.sum
sum其实是带有两个参数的:
dim指定对矩阵第dim维进行sum操作keepdim=Falsekeepdim将会使矩阵尽可能使用原来的维度进行表示。很显然,sum操作会降维(比如一个二维数组求sum之后,就成了一个一维数组)
实例:对于torch.FloatTensor(range(16)).view((1, 1, 4, 4))的四个维求sum,输出:
1 | Only sum: tensor(120.) |
关于sum,使用时需要搞清楚其作用维度。得到作用维度之后可以进行一系列操作,如:
- 平方后sum,求最后一维的和得到模的平方
- 对应元素相乘后sum,求对应维度的和得到点积结果
torch.transpose
参数很好理解:直接transpose针对一般的二维矩阵,只需要a.transpose()即可。但是高维矩阵,transpose提供了两个可选参数:
dim0anddim1表示,这两个dim进行互换(实际上可以不理解为transpose,理解为swap)
torch.cat
简单的concatenate函数。存在两个参数:
- 需要concat的矩阵,不可变时使用tuple,可变可以使用list。
- dim(进行concat的维度),要么dim是指定的维度,-1显然表示的是最后一维。比如二维矩阵时,dim = 0表示按行方向进行cat,为1时按列方向进行cat。
torch.norm
求范数。对于向量而言,设a为一个tensor。那么a.norm()直接调用输出2-范数。可以带参数:
- p = order,其实就是p-范数。1就是绝对值,2就是欧几里得。
- dim(可以是int或者tuple)。torch的维度操作确实容易让人困惑。个人的理解是:传入的dim用于组织元素,对需要组织的维度进行范数计算。比如:
1 | a = torch.arange(16).view(2, 2, 2, 2) |
可以看出,torch将tensor a的2 / 3维度进行合并,相当于[[a, b], [c, d]],其中a为元素[[0, 1], [2, 3]]。求1-范数即求绝对值之和。需要组织(整合成一个元素)的维度为(2, 3)。二维的例子会更加容易明白。
- keepdim 和sum一样,norm操作也是降维的。
torch.max / min
max/min是存在参数的:dim以及keepdim。dim参数会指定:max/min操作进行的维度。比如一个二维矩阵:
\[
A=
\begin{pmatrix}
1 & 2 & 3 \\
4 & 5 & 6 \\
7 & 8 & 9
\end{pmatrix}
\] 如果指定A.max(dim =
0),指定在0维度(行)方向上求最大值,也就是每一列(沿着行变化方向)求最大。输出是:
1 | torch.return_types.max(values=tensor([7, 8, 9]), indices=tensor([2, 2, 2])) |
可以使用解包的方式,左值使用逗号分割。默认情况下会求全局最大值。
torch.argmax / argmin
其实max已经可以输出最大值最小值对应的位置了。arg系列可能稍微快一些,因为不用返回值。dim / keepdim用法与max/min是一致的。
torch.index_select
相当于切片的集成。help中说得很清楚,index_select就是用于取出矩阵中某些元素 / 行列 / 维度的。
1 | x = torch.randn(3, 4) |
dim 用于视角选择。dim = 0时,说明当前index是基于行的,一次取出n行。dim = 1则相对于列进行讨论。
torch.squeeze / unsqueeze
squeeze去除所有维度为1的多于维度。dim用于指定哪些维度可以被操作。- squeeze返回一个与原矩阵共享内存的矩阵(相当于一个ref)
- squeeze可能会在batch训练中,将batch_size = 1造成的第四维将为三维。
unsqueeze就是增加一个维度(为1)。参数与squeeze一致。
“-1”的作用
与矩阵乘法中使用None做索引类似,-1在torch中也有很多作用。比如最常用的:
- a.view(1, -1)与a.view(-1, 1)。此处-1表示,由系统自主确定此处的值,-1称为推测。但是只有一维可以被推测,高于1维没办法确定性推测。但-1还是有一些奇怪的使用:
- sum(dim = -1) 此处是什么意思?这与-1作为索引一致。-1为最后一个,则选择最后一维进行sum操作。通常为列操作。