线性/树型分类器的纯理论分析
纯理论分析
Preface
周志华老师的《机器学习》看到了第五章,可总感觉看得太快了(可惜起步太晚了,大三下才系统地学ML)。个人认为走马观花地看完全没有用处,最好是能自己将所有碰到的轮子都写一遍(理想情况),但人的精力毕竟有限,开学了时间也比较紧张,实现这一步就先跳过吧,而细致的理论分析与理解是完全必要的。LDA之前实现过Github Algorithm-Plus🔗,决策树倒是连理论都没怎么细看,只调过库。为了不当调库侠,有写轮子的能力,个人将对这两章进行一下梳理,写一下自己的理解。

LDA(消歧义:Linear Discriminant Analysis,不是Latent Dirichlet Allocation)和决策树都是两个非常简单但是又很优雅的分类器。
LDA的数学推导
同类样本的类内方差最小,而不同类样本的类间方差最大
LDA是给定标签下的有监督降维方式,希望找到更低维度上的投影,可以满足上述属性。而对于高维而言,协方差是描述样本关系的指标。协方差的定义如下(大二下学的,回忆一下):描述n维随机变量\(X=(X_1,X_2,...X_n)\)每个分量之间存在的关系,协方差可以定义为: \[ \begin{equation} C = \begin{pmatrix} c_{11} & c_{12} & ... & c_{1n} \\ c_{11} & c_{12} & ... & c_{1n} \\ \vdots & \vdots & \ddots & \vdots \\ c_{n1} & c_{n2} & ... & c_{nn} \\ \end{pmatrix} \end{equation} \] 其中,\(c_{ij}\)是两个分量\(X_i,X_j\)的协方差\(Cov(X_i, X_j) = E[(X_i-E_i)(X_j-E_j)]\)。协方差存在一些性质,比如说: \[ \text{let }Cov(X)=\Sigma\\ Cov(AX+b)=A\Sigma A^T \] 证明就省略了,根据期望的性质,推导还是比较简单的。
二分类
假设有两类样本,\(D_1\)以及\(D_2\),\(D_1\)的样本中心(根据矩法可以求出来)为\(\mu_1\),对应地\(D_2\)有\(\mu_2\),那么假设存在一个低维过原点的超平面(由于是平行投影,是否过原点不影响结果,但原点较好讨论),这个超平面方程为:\(w^Tx=0\),那么投影在这个超平面上的数据点应该有什么形式?中心点应该有什么形式?协方差是否改变?\(w^Tx=0\)确实是降了1维(因为有一个约束方程),但如何使用\(w\)进行投影?
实际上,每个样本点\(x_i\)都在:\(w^Tx+b_i=0\) 这个超平面上,去掉这个相对原点的偏移,就可以得到每一个样本点在低维上的投影。实际是这样操作的:设\(x_i\)是超平面\(w^Tx = 0\)外一点,那么显然,\(x_i\)可以表示为超平面上的投影点\(x_i'\)与法向量\(w\)的加权组合(因为已经构成基了),比如: \[ \begin{equation} x_i=x_i'+\lambda_iw \end{equation} \] 那么\(\lambda_i\)显然就是\(x_i\)在单位法向量\(w_e\)上的投影,那么可以知道: \[ x_i'=x_i-\frac{w^Tx_iw}{\Vert w\Vert^2} \] 但这是个什么呢?样本中心间的距离又是什么?可以求出样本中心应该在: \[ \begin{equation}\label{proj} x_c'=\frac 1N\sum_{i=1}^N\left(x_i-\frac{w^Tx_iw}{\Vert w\Vert^2}\right) \end{equation} \] 显然公式\(\eqref{proj}\)是可以进行化简的,对于内积部分(后半部分),需要将内积展开为累加,进行累加次序交换: \[ \begin{array}{l} \frac 1N\sum_{i=1}^N\frac{w^Tx_iw}{\Vert w\Vert^2}= \frac 1{N{\Vert w\Vert^2}}\sum_{i=1}^N \left(\sum_{j=1}^nw_jx_{ij} \right)w\\ =\frac 1{\Vert w\Vert^2}\sum_{j=1}^n\frac 1n\sum_{i=1}^N w_jx_{ij}w\\ =\frac w{\Vert w\Vert^2}\sum_{j=1}^nw_j\mu_i =\frac{w^T\mu w}{\Vert w\Vert^2} \end{array} \] 前半部分的化简十分简单。那么投影后的两个集合中心的差向量应该是: \[ \begin{equation}\label{diff} \pmb{d}=\mu_1-\mu_2-\frac{w^T(\mu_1-\mu_2)w}{\Vert w\Vert^2} \end{equation} \] 实际上,Fisher的处理方法与我的处理方法完全不同,我是真的求了一个这样的投影,但不管是Fisher还是西瓜书上的推导,均值全部都是:\(w^T\mu\),这让我觉得很奇怪,如果是这样的话,均值的维度不就是1了吗?但实际上维度只应该减1啊?以上都是我看了第一部分产生的想法,但实际上二分类LDA并不是投影到n-1维空间中(特征分量数为n),二分类的LDA直接投影到一维空间上。二分类只需要在一条直线上找到数据的投影即可,在这条直线上判定投影后的新数据离哪一类数据中心最近。
由于这是一下从n维降到1维,所以几何直观上并不好理解。个人觉得这样的降维跨度太大了。
为什么要投影到一条直线上?
由于二分类输出的指示结果为 \(p_1,p_2,\text{ where } p_1+p_2=1\),也就是说分为两个类,落在两个类内的概率满足一个归一约束,那么输出就相当是在一条直线上。也就是说,LDA认为:输出在不同类上的概率实际上是所有输入特征经过\(w\)映射的线性组合,二分类问题只需要得到直线上的一个值,就能根据归一约束求出分属于两个类的概率。那么:
- 三分类问题只需要求得在二维空间上的一个点,就能求出一个样本分属于三个类的概率。也即线性组合输出了一个二维的点
- 四分类问题只需求出三维空间中的一个点,就能求出一个样本分属于四个类的概率...
- M分类问题只需要求出M-1为空间中的一个点,就能求出一个样本分属于M个类的概率。
要注意特征空间(n维)和概率空间(M维)的不同。LDA实际上就是在正态分布以及同方差的假设下,认为只要线性组合n个特征,就能求出M维空间中的一个概率解。这也就解释了,为什么我一开始的理解是有问题的。问题的关键就在于:输出分类的概率是输入特征的线性组合。不能简单地想着投影,而要想为什么要这样投影,这样投影如何帮助求得分类概率。
那么数学上就比较好理解了:给定一条直线\(y=w^Tx\),说是要投影到直线上,实际上要做的是根据\(w\)对样本的不同属性进行线性组合:\(w^Tx\)。那么也就有: \[ \begin{align}\label{class2} & \mu_1'=w^T\mu_1 \tag{center of projected class 1} \\ & \mu_2'=w^T\mu_2 \tag{center of projected class 2} \\ & \sigma_1=w^T\Sigma_1 w \tag{projected within-class cov 1}\\ & \sigma_2=w^T\Sigma_2 w \tag{projected within-class cov 2} \end{align} \] 那么根据类内方差最小,类间方差最大的思想: \[ \begin{equation}\label{obj1} \text{max } \frac{\Vert {w^T\mu_1 - w^T\mu_2} \Vert^2}{w^T(\Sigma_1+\Sigma_2)w} \end{equation} \] 分子展开维转置乘积之后,可以定义两个散度矩阵: \[ \begin{align} & S_b=(\mu_1-\mu_2)(\mu_1-\mu_2)^T & \tag{within-class scatter matrix} \\ & S_w=\Sigma_1+\Sigma_2 & \tag{between scatter matrix} \end{align} \] 使用这两个散度矩阵,定义问题\(\eqref{obj1}\)带有广义瑞利商的形式。解问题\(\eqref{obj1}\)就可以得到最优的\(w\)。由于\(w\)的长度是不影响结果的(看的就是方向),不妨令分母为1,最大化分子,进一步化简为: \[ \begin{equation}\label{obj2} \begin{array}{ll} \text{min } -w^TS_bw \\ \text{s.t. } w^TS_ww=1 \end{array} \end{equation} \] 请Lagrange坐到主席台上来。根据增加了一项乘子项的优化问题\(\eqref{obj2}\),KKT条件梯度为0,得到: \[ \begin{equation}\label{kkt1} S_bw=\lambda S_ww \rightarrow(\mu_1-\mu_2)=S_ww \end{equation} \] 等式\(\eqref{kkt1}\)可以化简得原因是:\(S_b=(\mu_1-\mu_2)(\mu_1-\mu_2)^T\),也就是说,\(S_bw\)实际方向就是\(\mu_1-\mu_2\),根据\(w\)尺度任意性,直接令\(S_bw=\lambda(\mu_1-\mu_2)\)省事。根据\(\eqref{kkt1}\),进行SVD分解(数值上会比较稳定)就可以得到\(w\)
多分类
从上述理解中已经可以知道LDA的“降维分类”方式,实际上是通过原特征的线性组合,将特征空间直接变换到“概率空间”(或者是可以被变换为概率的空间)。当分类数量为M时,只需要知道M-1个类上的概率或者等价概率值就可以求出所有类上的“概率输出”值。
也就是说:LDA的降维过程实际上是由n维特征空间变换为M-1维分类空间的过程。回顾二分类的情况,M = 2,也就是将所有样本投影到一维(直线)上:\(y=w^Tx\),直线上的值显然是一维的。这是由于参与线性组合的函数实际上是一个标量值函数(\(w^Tx\)映射),要想输出高维的向量,只需要更改\(w\)为一个矩阵\(W\)即可。对于需要优化得到的结果,推导有些不同: \[ \begin{equation}\label{div1} S_t=\sum_{i=1}^m(x_i-\mu_t)(x_i-\mu_t)^T \end{equation} \] 定义公式\(\eqref{div1}\)为全局散度,也就是每个样本点到所有样本的平均点的散度和。个人认为,由于类间差异在大多数情况下都会大于类内差异,所以\(S_t\)相当于就是一个类间方差的表征(不同类的均值点到整体均值点的散度)。由于不同于二分类问题,类内散度需要重新定义了。显然类内的散度可以用类内样本与本类均值的差异来衡量: \[ \begin{equation}\label{div2} S_w=\sum_{j=1}^N(x_{ij}-\mu_i)(x_{ij}-\mu_i)^T \end{equation} \] 但是至于为什么西瓜书上要使用\(\eqref{div2}-\eqref{div1}\)作为最后的类间散度矩阵,我不是很清楚。甚至我觉得,\(\eqref{div2}\)的定义是多余的。类间散度实际上可以根据:
类内散度通常小于类间散度,在最优投影取得的情况下就更是这样了。所以每个样本,在类间散度很大的情况下,可以看作一个十分接近类内均值的点(如下图所示)。那么每个样本点都可以近似地被类内均值取代。
那么很自然,类间散度可以定义为(每个样本(近似)与全局均值的散度和) \[ \begin{equation}\label{div3} S_b=\sum_{i=1}^Mm_i(\mu_i-\mu)(\mu_i-\mu)^T \end{equation} \] 优化目标也需要更改,因为实际的输出式已经变成了如下式所示的多维线性组合矩阵\(W\),输出是多维的,那么可以简单地使用迹进行实现。 \[ \begin{equation}\label{obj3} \frac{W^TS_bW}{W^TS_bW}\rightarrow\text{ max }\frac{tr(W^TS_bW)}{tr(W^TS_bW)} \end{equation} \] 对于上式,继续根据拉格朗日乘子法可以得到: \[ \begin{equation}\label{solve} S_bW=\lambda S_wW\rightarrow {S_w}^{-1}S_bW=\lambda W \end{equation} \] 可知,\(W\)是一个(n * M-1)维矩阵,而显然\(\eqref{solve}\)中\(W\)的每个列向量分量都是矩阵\({S_w}^{-1}S_b\)的一个特征向量(符合特征向量定义,当然可能是广义特征向量),那么\(\begin{pmatrix}N-1\\n\end{pmatrix}\)种不同的情况,究竟是哪N-1个特征向量组合成了最终的解\(W\)?从公式\(\eqref{solve}\)种可以看出,\(\lambda\)越大越好(对应最大化\(\eqref{obj3}\))。那么只需要选择\({S_w}^{-1}S_b\)最大的N-1个特征值(或者广义特征值)的特征向量组成解即可。
树型 - 决策树
树越是向往高处的光亮,它的根就越要向下,向泥土,向黑暗的深处。—尼采
emmm。这句话只因为有个“树”字就被我拿出来镇一镇文章了。决策树,利用一个个不相互影响的特征(或者我们认为影响不太大的特征,实际上有影响也是可以通过某些操作进行转化的)进行层层分类。正如猜物游戏,每次只能问一个答案只有“是”和“否”的问题,通过答案产生的分支进行推测。通过对待分类样本的层层分解可以获得最终的分类推测。本节只讨论其相关的数学原理,对于具体的生成 / 剪枝算法将不会涉及(因为这没有吸引到我)。
信息论相关
回顾一下信息熵的两个定义: \[ \begin{equation}\label{ent} Ent(x)=-\sum_{i=1}^np_ilog(p_i)\text{ or }Ent(x)=-\int p(x)log(p(x))dx \end{equation} \] 左边为常见的离散型随机变量熵的定义,而右边则为连续变量在其PDF意义下的熵。在讲KL散度的时候已经说过了,熵是用于衡量信息编码的一个概念。一个随机事件的不确定性越大,代表信息量越大,编码这个事件所需要的二进制位数也相应越大。
在决策树一章中,《西瓜书》提到:
"信息熵" (information entropy) 是度量样本集合纯度最常用的一种指标。
为什么这么说呢?集合样本纯度又是指什么?纯度在此处指:同一个划分中,由于划分集合内的元素都存在相应的label,如果集合内的label越趋于一致,那么这个集合的纯度也就越高。如果用比例\(p_k\)表示划分集合中,第k类样本所占的比例,那么这个集合的信息熵(纯度)表示如下: \[ \begin{equation}\label{purity} Ent(D) = -\sum_{i=1}^np_ilog(p_i) \end{equation} \] 可以看出,公式\(\eqref{purity}\)定义的纯度,当某一类完全占据整个集合时熵取得最小值0。为什么要讨论信息熵或者是纯度?处于决策树的生成考虑,我们使用很多特征生成一棵决策树,但在决策树中,不同的特征地位也是不相同的,naive的情况下,每次分支只选择其中一个特征,那么要选哪一个特征作为本结点向下分支的特征?需要进行优选,优选的指标就是纯度。
显然,如果一种划分模式可以划分出纯度较高的子结点(样本子集合),那么:
- 全纯结点(只有一类)可以避免进一步分支,减小树结构复杂度
- 子集合越纯,说明分类效果越好(因为原集合是无序的,熵大,分类可以看作熵减过程)
由此我们定义信息增益:对于公式\(\eqref{purity}\)定义的“纯度”,个人认为应该叫做“杂度”更好,实际上我看Wikipedia称这个为“impurity”,很显然嘛,值越大杂度越高。那么原集合的杂度为\(Ent(D)\),如何选取划分才能使得系统的杂度下降最大呢?假设我们选取的属性\(a\)存在\(v\)个不同的值(也就是\(v\)分支),那么每个分支(a属性的每种可能取值)都会有一定样本(可以为0),记为\(D^v\)。对应地,\(Ent(D^v)\)指的是总体为\(D^v\)时,分类的杂度。那么根据\(\vert D^v\vert / \vert D\vert\) 也即每个属性样本的占比对杂度进行加权,划分后的系统杂度为: \[ \begin{equation}\label{impurity} G(D,a)=Ent(D)-\sum_{j = 1}^v\frac{|D^j|}{|D|}Ent(D^j) \end{equation} \] 公式\(\eqref{impurity}\)是原系统的杂度 减去 划分后的系统杂度。这也就是分类,这个熵减过程到底让系统的熵减了多少。这被称为信息增益(information gain),实际上衡量的就是分类使系统熵减少的量。显然我们希望,熵减越大越好。那么每次从属性集合中计算 / 选择信息增益最大的属性进行分支即可。
互信息
信息论中,如果需要衡量两个随机变量之间的关系,可以计算 一个随机变量携带的信息包含另一个随机变量信息的量大小,这被定义为互信息(mutual information)。可以这样认为:两个有关联的变量,给定其中一个变量的信息,另一个变量的不确定性随之减小: \[ \begin{equation}\label{mut} I(X;Y)=D_{KL}(P_{XY}||P_X \otimes P_Y),\text{ where } x\in\mathcal{X},y\in\mathcal{Y} \end{equation} \] 上式说的是:x是空间\(\mathcal{X}\)中的随机变量,y是空间\(\mathcal{Y}\)中的随机变量,那么互信息是联合分布\(P_{XY}\)与边缘分布\(P_X\text{ and }P_Y\)的外积的KL散度。多维空间不好理解的话,讨论一维变量: \[ \begin{equation}\label{mut1} I(X;Y)=\int_y\int_xp(x, y)log\left(\frac{p(x, y)}{p(x)p(y)}\right)dxdy \end{equation} \] 为什么这样可以描述相关程度呢?因为显然,X与Y独立时的联合分布为\(p(x)p(y)\),此处衡量的即是真实联合分布\(p(x, y)\)与独立时的联合分布的差别。
互信息和信息增益是存在关系的[1]。在划分时,如果对属性集合A(也就是\(a\)所在的集合)取上一个期望,那么会有什么发现?也即对公式\(\eqref{impurity}\)定义的信息增益取A的期望,为了方便数学变换,我们将\(\eqref{impurity}\)展开: \[ \begin{equation}\label{expand} G(D,a)=-\sum_{k=1}^Jp_klog_2p_k-\sum_{v=1}^V\frac{|D^v|}{|D|}\left(-\sum_{k=1}^Jp_{D^v,k}log_2p_{D^v,k}\right) \end{equation} \] 显然公式\(\eqref{expand}\)可以被表示为(原系统熵 - 给定划分下的新集合熵) \[ \begin{equation}\label{ent1} G(D,a)=Ent(D)-Ent(D|a) \end{equation} \] 进行期望的求取可以得到: \[ E_A(G(D,a))=Ent(D)-Ent(D|A) \] 下面证明一个有关互信息的简单结论: \[ \begin{equation}\label{lemma} I(X;Y)=Ent(X)-Ent(X|Y) \end{equation} \] 怎么说呢。推了好长时间没有推出来的原因就是:没有学过信息论,概念不清楚。比如\(\eqref{lemma}\)右边的第二项,条件信息熵,定义为: \[ \begin{equation}\label{cond} Ent(X|Y)=\sum_{x\in\mathcal{X},y\in\mathcal{Y}}p(x,y)log(p(x|y)),\text{ but not }\sum_{x\in\mathcal{X}}p(x|y)log(p(x|y)) \end{equation} \] 那么\(\eqref{lemma}\)可以展开为: \[ I(X;Y)=-\sum_{y\in\mathcal{Y}}\sum_{x\in\mathcal{X}}p(x,y)log(p(x))+\sum_{y\in\mathcal{Y}}\sum_{x\in\mathcal{X}}p(x,y)log\left( \frac{p(x,y)}{p(y)}\right) \] 化简可以得到公式\(\eqref{lemma}\)成立。那么可以知道,增益率对于A的期望(也就是对于属性集的概率平均)就是决策树结点与属性集的互信息。
增益率
实际上,纯使用信息增益并不太好。假设某个分支结点只有一个样本,那么显然分支纯度最大(杂度最小),那么假如有一个属性分支极多,可能一下就将所有的样本分到不同结点上了(比如《西瓜书》上提到的,样本序号),这样容易产生过拟合的分支属性是没有意义的,但是只用信息增益的话实际就会选择这个分支方法。所以使用一个因子来限定分支数的影响: \[ \begin{equation}\label{int} IV(a)=-\sum_{v=1}^V\frac{|D^v|}{|D|}log\left( \frac{|D^v|}{|D|}\right) \end{equation} \] 可以发现,当分支数越多,这个值越大(不会出现单分支)。这个值称为:固有值(intrinsic value),只需要使用这个值对增益进行惩罚即可(除以此值)。
基尼指数
针对CART决策树的,而以上所说的决策树使用信息增益作为划分属性选择的度量。基尼指数(Gini impurity)指的是:
Gini impurity is a measure of how often a randomly chosen element from the set would be incorrectly labeled if it was randomly labeled according to the distribution of labels in the subset.[1]
翻译很简单:从集合中随机选择一个元素,再根据这个集合中的类别概率分布随机给这个元素进行分类,分类的错误概率就是基尼指数。 \[ \begin{equation}\label{gini} Gini(D)=\sum_{i=1}^{|\mathcal Y|}p_i\sum_{k\neq i}p_k=1-\sum_{k=1}^{|\mathcal Y|}p_k^2 \end{equation} \] 显然,纯度越高的集合,内部随机取元素随机分类错误的概率(期望)越小。
变量缺失处理的理解
在贝叶斯决策论中提到:
- 某一属性组合的变量可能根本不在样本中出现,但是不能直接认为这样的样本不存在。
而在决策树中,我们更多针对的问题是:当某一个样本某个属性值是未知的,如何处理这样的样本?丢弃是显然不可取的,这样可能损失太多的有效信息。而直接使用确实也不是办法,少掉一个属性要如何继续分支?《西瓜书》上将问题总结地很不错:
我们需解决两个问题: (1) 如何在属性值缺失的情况进行划分属性选择 ? (2) 给定划分属性,若样本在该属性上的值缺失,如何对样本进行划分 ?
第一个问题我开始并没有什么很好的想法。而对于第二个问题,个人开始认为,假设已经知道了划分属性,可以根据其他完好样本来估计本样本在这个缺失属性上的分布,进行分布加权(事实上,这个想法类似《西瓜书》上提供的方法)。
问题一实际上比较容易,我想得太复杂了。由于划分属性只考虑一个属性与分类结果的关系,那么完全用不着考虑多属性关系,只需要取出这个属性下对应没有缺失的样本,利用这些样本估计【属性】对【分类结果】的影响即可。以信息增益法为例,考虑\(\eqref{impurity}\)定义的信息增益。假设我们讨论属性\(a\),由于有些样本属性是缺失的,在计算时将这些样本剔除再计算新集合\(\tilde{D}\)的信息增益\(\tilde{G}(\tilde{D},a)\)。注意,此信息增益计算出来后需要加权: \[ \begin{equation}\label{weigh} \tilde{G}(\tilde{D},a)\times\rho,\text{ what is ρ?} \end{equation} \] 其中的\(\rho\)是加权因子,是什么权重呢?假设属性a在集合中有\(|\tilde{D}|\)个未缺失样本,那么\(\rho=|\tilde D|/|D|\),也就是说,样本缺失越少,信息增益计算越可信。
问题2实际上是将“让同一个样本以不同的概率划入到不同的子结点中去”(《西瓜书》言)。也可以使用没有缺失属性a的样本信息,假设某一分支分到属性a的v取值\(a^v\)上: \[ \tilde{r_v}=\frac{\sum_{x\in\tilde{D}_v}w_x}{\sum_{x\in {\tilde{D}}}w_x} \] 也就是没有缺失属性a的样本中,有\(\tilde{r_v}\)比例样本在本属性上取值为v,那么当每个样本权重为\(w_x\)时,可以按照比例将缺失样本分配给不同分支(相当于按照概率(比例)割裂一个缺失样本)。
Kernelization
普通决策树的分类边界都是垂直于某个轴的(因为决策树是一种“非黑即白”的分类方法)。在某个属性(某个维度)上,只有固定的几种分法:
Figure 3. 决策树在单一维度上的分类边界总是垂直于轴的
啊这?太过于“一维”了,甚至连简单的线性可分分类都需要经过如下的艰难操作:
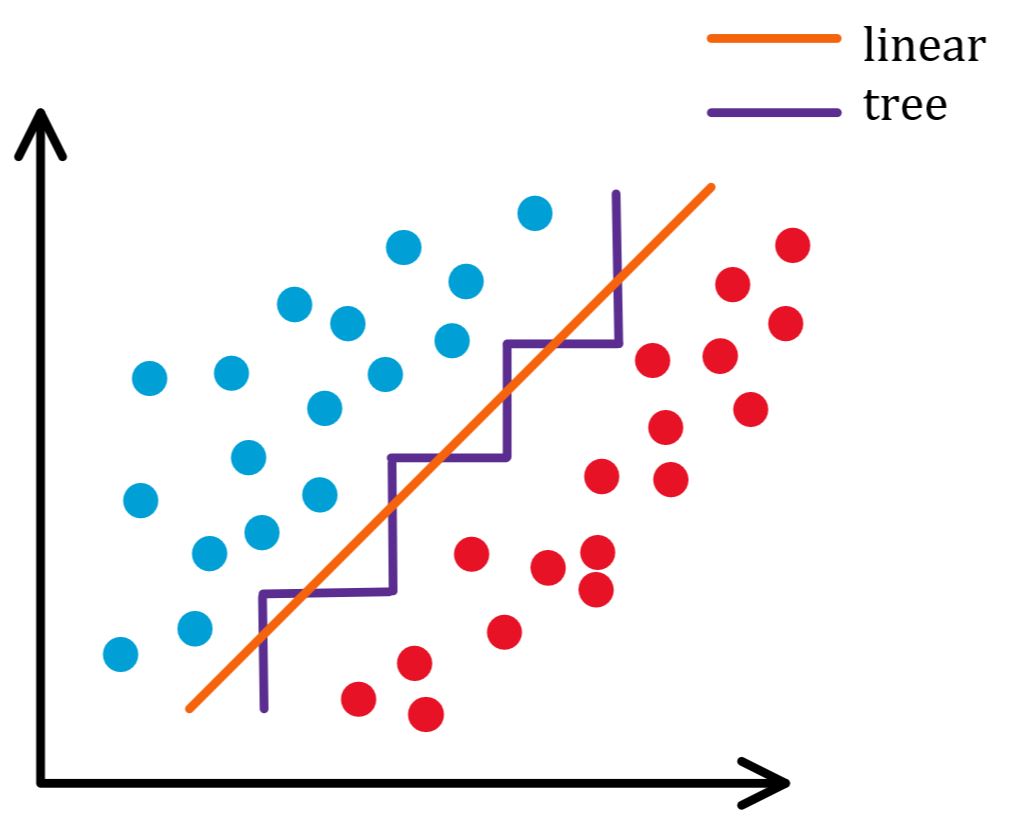
Figure 4. 决策树扭来扭去
一个简单的想法就是:不适用原属性进行分类,我们可以像PCA那样,使用属性的线性组合形成抽象属性,在这个抽象属性对应的新空间中,虽然分类边界仍然垂直于新的空间轴,但在原空间看起来,就成为一般线性分类器了。而进一步地,如果使用其他的非线性特征组合方法,也就是引入某些 kernel,甚至可以通过决策树达到任意分类边界生成的效果。
Reference
[1] Wikipedia, Decision tree learning