优雅线代与美妙优化
矩阵分析 & 优化
最近接触了一些有趣的 机器学习 / 控制算法,其中的数学原理非常有意思,大多数都涉及到了矩阵分解以及线性代数解析解的求取。推导这些理论可以帮助深入理解矩阵分解(以及分解后子矩阵的数学意义)以及 矩阵分析和优化理论的数学联系,这些理论都非常优雅而且美妙。

本文将包括以下四个部分:
- 卡尔曼滤波的最小二乘解释
- 最小二乘的几何解释
- 谱聚类的矩阵分析
- PCA的矩阵分析
KF最小二乘解释
Kalman Filter,作为一种“最小二乘”滤波器,其应用极其广泛。个人使用KF设计过:
- 目标跟踪算法(Adaptive Robust KF)[Github🔗:Algorithm_Plus/KF]
- 语音信号处理(白噪声滤波):[Github🔗: AudioDSP]
虽然说,KF是“最小二乘”的迭代式滤波器,但自己从来没有里结果其中的数学原理,也即:(1) 最小二乘最优性是如何得到的?(2)为什么KF是迭代式的?而关于KF的深入分析(包括参数整定,自适应化,收敛性谈,将会在另一篇博文中细讲【卡尔曼进阶与粒子滤波实现】)。
KF最小二乘性
我们将最为一般的KF迭代公式重写如下(实际上个人认为实现KF最难的地方就是记公式): \[ \begin{align} & \breve{x}(k)=A\hat{x}(k-1)+Bu(k)+w(k) \label{transit}\\ & \breve{P}(k)=A\hat{P}(k-1)A^T+Q \label{covup}\\ & z(k)=H\breve{x}(k)+v(k) \label{obs}\\ & K=\breve{P}(k)H^T(H\breve{P}(k)H^T+R)^{-1}\label{gain}\\ & \hat{x}(k)=\breve{x}(k)+K(z(k)-H\breve{x}(k)) \label{xcor}\\ & \hat{P}(k)=\breve{P}(k)-KH\breve{P}(k)\label{covcor} \end{align} \] 其中,“\(\breve{ }\)”表示先验,“\(\hat{ }\)”表示后验。也就是说:
| 先验(前两行) | 后验(前两行) | |
|---|---|---|
| \(\breve{x}(k)\) 迭代k的状态(先验均值) | \(\hat{x}\)(k) 后验均值 | |
| \(\breve{P}\)(k) 状态k的协方差(先验协方差) | \(\hat{P}\)(k) 后验协方差 | |
| Q 状态转移噪声协方差 | R 观测噪声协方差 | |
| A 状态转移矩阵,H观测矩阵 | B 控制矩阵 \(u(k)\)系统控制量(外界输入) | |
| \(w(k),v(k)\) 噪声(一般讨论白噪声) | K 卡尔曼增益 |
光看这个迭代式根本不知道为什么KF会得出最小二乘最优来,在《概率机器人》一书上,作者使用的是概率分布的转移以及推导来看待KF的迭代优化过程,并没有从最小二乘的角度看待这个问题。下面我们尝试从最小二乘角度来分析KF。
考虑一个拟合问题,拟合曲线时,数据点都是给定的(而且一般有噪声)。个人认为这是个平滑问题(因为使用者有unlimited access to all the data【随便写段英文】),根据Smoothing, Filtering and Prediction所说,平滑 / 滤波 / 预测是针对三个不同的时间点:处理过去的数据(已经接收并且存储),处理当下的数据(比如确定更准确的测量值),处理未来的可能数据(预测)。而KF的一种常用领域-控制,是有实时性要求的,要求至少需要达到【滤波】的标准,最好能进行【预测】。而一般的拟合,基本都是一次性计算所有的点,所以着导致了一般的拟合问题 不是增量性的(也即有新的数据点,需要全部重新计算,比如loss与梯度)。
KF显然并不是这样的,KF需要实时更新,并且不能依赖太久远的历史信息(低阶的马尔可夫性)。KF的预测输出期望能与观测贴合(但这也不完全一定,由于观测是存在一定的噪声的)。根据论文"Robust Estimation with Unknown Noise Statistics",我们可以把KF问题重写成如下形式: \[ \begin{equation}\label{optim} \begin{pmatrix} I\\ H \end{pmatrix}\breve{x}(k)= \begin{pmatrix} A\hat{x}(k-1)\\ z(k) \end{pmatrix} + \begin{pmatrix} w(k)\\ v(k) \end{pmatrix}= \begin{pmatrix} A\hat{x}(k-1)\\ z(k) \end{pmatrix} + E(k) \end{equation} \]
假设我们求解噪声矩阵\(E(k)\)的协方差,那么它应该是这样的: \[ \begin{equation}\label{ecov} \mathbb{E}(E(k)E(k)^T)=\begin{pmatrix} \breve{P}(k) & \mathbf{0} \\ \mathbf{0} & R(k) \end{pmatrix} \end{equation} \]
协方差为什么长成这样呢?很显然:\(w(x)\)自己的协方差就是状态转移协方差(注意不是噪声协方差Q,因为Q需要进行状态转移),而\(v(x)\)的协方差是噪声协方差。而\(w(x),v(x)\)默认是相互独立的,故非对角线矩阵块为0。接下来,对这个协方差进行矩阵分解: \[ \begin{equation} Cholesky(\mathbb{E}(E(k)E(k)^T))=SS^T \end{equation} \]
此后所做的事情有点奇怪,矩阵\(S\)被单独使用了(协方差矩阵的矩阵LU分解代表了什么意义?)。实际上,这里是要使linear transform之后的噪声协方差为单位阵(也就是说,此处做了一个白化变换)。我们看公式\(\eqref{optim}\),\(E(k)\)是系统的噪声,而系统高斯噪声并不为单位阵,问题并非标准问题,也可以说是:输入没有进行标准化。那么对于\(\eqref{optim}\)而言,等号左右乘以\(S^{-1}\)实际上就是在做白化变换: \[ \begin{align} &S^{-1}\begin{pmatrix} I\\ H \end{pmatrix}\breve{x}(k)= S^{-1}\begin{pmatrix} A\hat{x}(k-1)\\ z(k) \end{pmatrix} + S^{-1}\begin{pmatrix} w(k)\\ v(k) \end{pmatrix}= S^{-1}\begin{pmatrix} A\hat{x}(k-1)\\ z(k) \end{pmatrix} + S^{-1}E(k)\label{optim2} \end{align} \]
\[ \begin{equation}\label{lsp} X(k){x}(k)+\xi(k)=Y(k) \end{equation} \]
这就是个标准的最小二乘问题,由于此处\(\mathbb{E}\{\xi(k)\xi(k)^T\}\)是单位阵。有没有发现此处我们已经不写\(\breve{x}\)了?虽然从推导式\(\eqref{optim}\)来说,此处确实应该是先验\(\breve{x}\),但是此问题的解(由于涉及到本次观测\(z(k)\)进行的后验修正)已经是后验了,那么可以根据pseudo逆理论求得\(x(k)\)的解: \[ \begin{align} &\hat{x}(k)=\mathop{\text{arg min}}_{x}\Vert Y(k)-X(k)x(k)\Vert^2 \\ &x^*(k)=(X^T(k)X(k))^{-1}X^T(k)Y(k)\label{optim3} \end{align} \] 从而得到了后验估计。这就是KF的优化表达式,而我们能从中推出KF的迭代性质吗?
KF迭代性质
分析不难得到如下关系: \[ \begin{equation} X^T(k)X(k)= (I\quad H^T)(S^{-1})^T(S^{-1}) \begin{pmatrix} I\\ H \end{pmatrix}=(I\quad H^T)(SS^T)^{-1} \begin{pmatrix} I\\ H \end{pmatrix} \end{equation} \]
而\(SS^T\)是公式\(\eqref{ecov}\)中的协方差矩阵,那么可以进一步得到: \[ \begin{equation} X^T(k)X(k)= (I\quad H) \begin{pmatrix} P^{-1}(k) & \mathbf{0} \\ \mathbf{0} & R^{-1}(k) \end{pmatrix} \begin{pmatrix} I\\ H \end{pmatrix} \end{equation} \]
展开以上式子可以得到: \[ \begin{equation} (X^T(k)X(k))^{-1}=(P^{-1}+H^TR^{-1}H)^{-1}=P+H^{-1}R(H^{-1})^{T} \end{equation} \]
诶,只需要顺着这样的分解下去,不难发现(真的不难,所以费篇幅在这推公式了),优化结果\(\eqref{optim3}\)与之前的后验更新式\(\eqref{xcor}\)是完全一致的。而协方差的先验后验更新实际上是类似的,这里就不再详细推导了。妙啊兄弟们,这样我们就推出了最小二乘与KF的关系。
最小二乘的几何解释
上DIP(数字图像处理)的时候,老师突然抛出一个问题来:
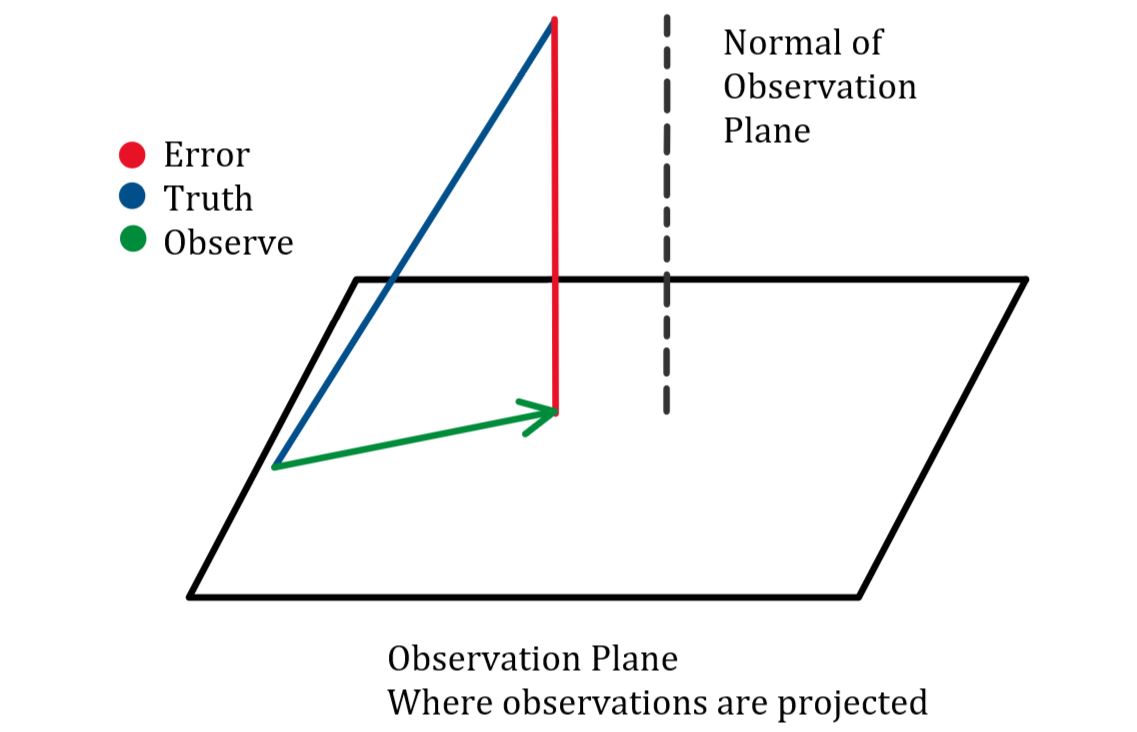
为什么说,观测平面需要和误差正交?(也就是说观测平面的法向量和误差的方向是重合的?)
惊讶,竟然没有人说上来为什么(可能大家都比较谦虚吧)。
从几何直观上非常好理解为什么。显然,观测\(\hat{x}\)是由真值的投影\(\breve{x}\)与误差\(e\)投影的结合,而如果投影平面(观测面)正好与误差是正交的,那么误差的投影将会是0。而在最小二乘意义下,误差的平均投影长度是最小的。
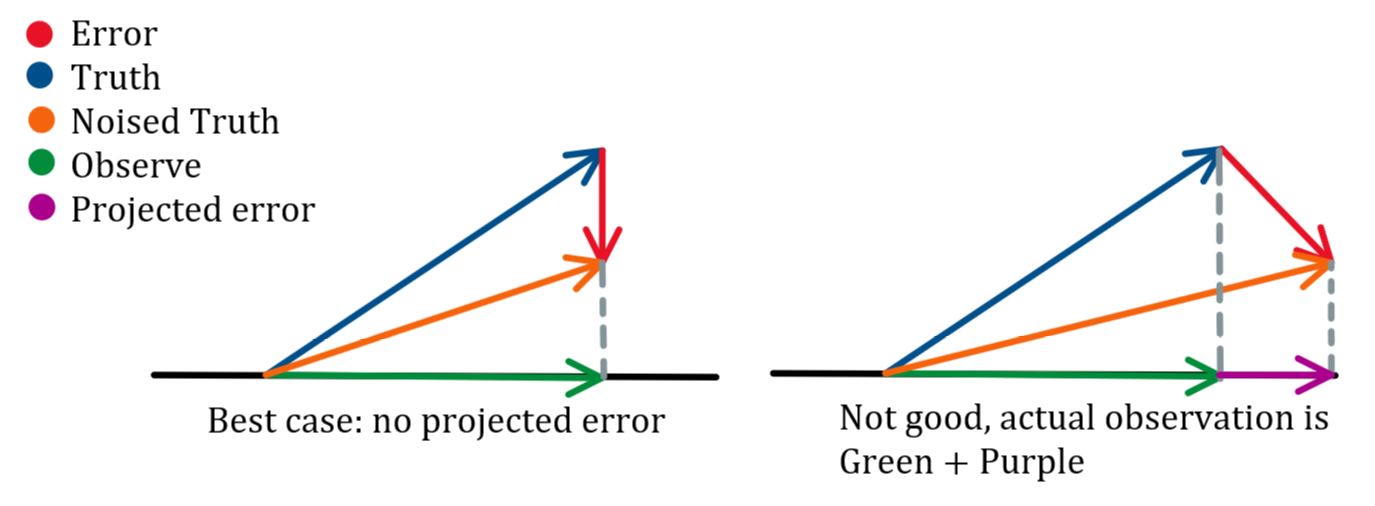
那么要求最优的投影面,实际上是要优化这个问题: \[ \begin{equation}\label{f17} \left\{ \begin{array}{ll} \text{min }\Vert \pmb{e}-(\pmb{a}^T\pmb{e})\pmb{a}\Vert^2\\ \text{s.t. }\pmb{a}^T\pmb{a}=1 \end{array} \right. \end{equation} \]
什么意思?意思就是,假设\(\pmb{a}\)是投影平面的单位法向量,那么\(\pmb{a}^T\pmb{e}\)就是误差在单位法向量上的投影,而\(\pmb{e}-(\pmb{a}^T\pmb{e})\pmb{a}\)就是误差在观测平面上的投影。需要使得这个投影最短。
那么解这个问题,实际上最后会求出:需要对误差的协方差\(\pmb{e}\pmb{e}^T=\Sigma\)进行矩阵分解,求最大特征值对应的特征向量,就是\(\pmb{a}\)。而这个特征向量实际上对应了误差的主方向(PCA部分中会提到这个思想),如果只有一个观测的话,则就是误差的方向。至于为什么,很简单,公式\(\eqref{f17}\)留给读者作为练习。
谱聚类矩阵分析
谱聚类(spectrum clustering)是一种很美妙的聚类理论,它包含了图论, 矩阵分析,优化理论以及机器学习理论,综合性的一个算法,理解这个算法可以帮助对以上四个方面的理论都有进一步的认识。
Laplace算子
这是我DIP课程中刚讲的空域滤波器kernel,虽然之前就知道Laplace长什么样,但是从来没有从DSP的角度去思考,也没有思考其数学原理。Laplace算子用 求二阶导,这是为什么呢?小编也不知道,小编也觉得很有趣。一个典型的Laplace kernel长这样: \[ \begin{equation} \begin{pmatrix} 0 & -1 & 0 \\ -1 & 4 & -1 \\ 0 & -1 & 0 \end{pmatrix} \end{equation} \]
从DSP的角度考虑Laplace算子的设计,这也就是一个高通滤波器嘛(求边缘使用),而对于直流分量这种显然是低频的信号成分来说,它是要被高通滤波器滤除的。于是高通滤波器不能保留任何直流的能量,需要保证对于平滑区域(比如ones),卷积结果为0。而图分析(graph)中,对于离散的图而言也有Laplace算子,并且其物理意义非常明确:求图上的最小割。首先推一下离散的二阶导,使用一个简单的一阶导表达式: \[ \begin{equation}\label{de_1} \frac{df}{dx}=f'(x)=f(x)-f(x-1) \end{equation} \]
而需要求二阶导,也就需要在本函数的基础上再求一阶导: \[ \begin{equation}\label{de_2} \frac{d^2f}{dx^2}=f''(x)=f'(x)-f'(x-1)=f(x)-2f(x-1)+f(x-2) \end{equation} \]
接下来分析无向带权图上的Laplace矩阵。
首先定义\(W\)为权重矩阵(无向带权图的邻接矩阵,注意\(w_{i,i}=0\)),\(W\)就刻画了节点之间的联系程度(或者cost)。在聚类问题中,我们设定,假设两个样本点之间的关系越紧密,特征越类似,对应节点之间的边权也就越大。那么聚类实际上就是在这样的图上寻找一个最小割(最小权的边集合),使得经过这个cut之后可以分为k个指定类。
此外,定义\(D\)为度矩阵,与普通的度定义不同(这个度是有权的),\(D\)为对角矩阵,元素\(d_{i,j}\)的意义是: \[ \begin{equation} d_{i,j}=\left\{ \begin{array}{l} \sum_{j=1}^nw(i,j),\text{ if }i=j \\ 0,\text{ otherwise} \end{array} \right.{} \end{equation} \]
D衡量的实际是一个节点与其他所有节点的联系紧密程度。则有了这两个矩阵,我们接下来定义\(L=D-W\)
也就是度矩阵减去邻接矩阵,看起来非常抽象?直接看L是难以得到其物理意义的,需要有其他向量的帮助
性质1 向量“差异”
\[ \begin{equation} \text{Given vector }x,\text{ }Lx= \begin{pmatrix} \sum_{j\neq1}w_{1j} & -w_{12} & ... & -w_{1n}\\ -w_{21} & \sum_{j\neq2}w_{2j} & ... & -w_{2n}\\ \vdots & \vdots & \ddots & \vdots \\ -w_{n1} & -w_{n,2} & ... & \sum_{j\neq n}w_{nj} \end{pmatrix} \begin{pmatrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{pmatrix} \end{equation} \]
将上式展开可以得到: \[ \begin{equation}\label{diff1} \begin{pmatrix} \sum_{j\neq1}w_{1j} & -w_{12} & ... & -w_{1n}\\ -w_{21} & \sum_{j\neq2}w_{2j} & ... & -w_{2n}\\ \vdots & \vdots & \ddots & \vdots \\ -w_{n1} & -w_{n,2} & ... & \sum_{j\neq n}w_{nj} \end{pmatrix} \begin{pmatrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{pmatrix}= \begin{pmatrix} \sum_{j\neq 1}w_{1j}(x_1-x_j)\\ \sum_{j\neq 1}w_{2j}(x_1-x_j)\\ \vdots\\ \sum_{j\neq 1}w_{nj}(x_n-x_j)\\ \end{pmatrix} \end{equation} \]
证明就是暴力展开。可以发现一个x时,对x做线性变换实际上求了x各个元素之间的差异。
性质2 标量输出
\[ \begin{equation}\label{diff2} x^TLx=\sum_{i=1}^n\sum_{j=1}^nw_{ij}(x_i-x_j)^2 \end{equation} \]
根据矩阵乘法,对公式\(\eqref{diff1}\)进行左乘x操作再展开很容易就能得到。此处,\(x^TLx\)的意义实际上就是:根据每个节点的关联关系 加权 的向量内部差异。但是这个向量\(x\)到底是什么?
向量x意义的讨论
我们讨论问题的背景是聚类,聚类中除了每对节点之间的特征差异之外,最显著的差异就是 聚类对应的类别差异了。那么x恰好可以作为一个指示向量,给定一个k=2簇的聚类问题,设: \[ \begin{equation}\label{indicate} x_i=\left\{ \begin{array}{ll} 1, \text{ if }\pmb{x}\in\mathbb{C}_1\\ -1,\text{ if }\pmb{x}\in\mathbb{C}_2 \end{array} \right. \end{equation} \]
那么\(Lx\)实际上就是不同节点之间label的差异,比如两个点为同一个簇,则\(Lx\)对应分量为0,否则为一个非0的值(正数)。现在要找一种方式割开这个点集(也就是找一个x),使得两个类之间的联系是最小的。那么实际上,切开两类的割对应的值就是两类之间被丢弃的(割开)类间联系,实际可以对应于\(x^TLx\)。在不同的formulation下,\(x\)可以有不同形式,但是其意义基本一致:割。
k=2时,完全可以使用一个向量进行运算(\(\pm1\)),而涉及到多类时,可能\(x\)就会是一个矩阵了(因为不存在一种赋值方式使得任意两类不同的结点的cost相减是相同的,举个例子:0为A,1为B,2为C,虽然AB,BC之间相差1,但是AC之间差2)。
二类Cut
k=2聚类直接使用如\(\eqref{indicate}\)所定义的向量x即可。
说了这么久矩阵分析,还没正经地开始分析呢。
可以看一下\(x^TLx\)的取值范围应该是什么?与矩阵L的特征值有什么关系?
由于矩阵的特征向量是相互正交的,它们实际上张成了一个与x所在线性空间等价的一个空间。从而可以知道,由于x存在于特征向量张成的线性空间中,x可在以特征向量为基时被特征向量的线性组合表示: \[ \begin{equation} x^TLx=(\sum_{i=1}^na_i\pmb{v}_i)^TL(\sum_{i=1}^na_i\pmb{v}_i),\text{ where }\pmb{v}_i\text{ is the eigen vec of }L \end{equation} \]
由于特征向量的定义,那么上式实际上就等于: \[ \begin{equation} x^TLx=\sum_{i=1}^na_i^2\lambda_i,\text{ where }\lambda_i\text{ is the eigen value of }L \end{equation} \]
\(x^TLx\)中的x并非是没有约束的,在二分类问题中,x是正负1的向量,而\(\pmb{v}_i\)为归一化之后的特征向量,故\(a_i\)的最大值不可能小于\(1/\sqrt{n}\),既然如此,设\(\max(a_i)=a_m\),\(a_m\)必然会作用到其中一个特征值上。那么可以发现,如果要求最小的话,显然让\(a_m\)作用到最小特征值上就可以让\(x^TLx\)等价地最小。那么求第j小也就相当于使用第j小特征值,那么对应的解向量也就是\(v_{\text{min jth}}\)。其实特征值最大最小性在之前就已经提过:
最大化类间方差时,就需要使用到协方差矩阵最大特征值对应的特征向量。而求平面 / 线段的normal时,就需要使用到最小特征值,不过这里的最小特征值可以有两种方法解释,以求线段的法线为例:
- 最小二乘得到线段的最优估计过程也就等价得到了法线的最优估计,那么最小二乘问题本身对应着最小特征值 以及其对应的特征向量
- 以矩阵特征向量的方向性来说,线段对应的方向向量就是最大特征值对应的特征向量(元素主方向),而与之正交的(次要方向,特征向量也是相互正交的,就跟方向向量与法线向量正交一样)法向量就是最小特征值对应的特征向量。
那么此处需要选择最小的几个特征向量作为“割”。取多少个(k)特征向量,相当于割出多少个簇,相当于割上k-1次,每一次可以得到新的簇。比如,举个例子: \[ \begin{equation} \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & \sqrt{\frac{1}{2}} & \sqrt{\frac{1}{2}} & 0 \\ 0 & -\sqrt{\frac{1}{2}} & \sqrt{\frac{1}{2}} & 0 \\ 0 & 0 & 0 & 1 \end{pmatrix} \end{equation} \]
这是四个特征向量,已经按照从左到右特征值逐渐减小的顺序排列了。假设我们最终需要得到簇k = 3,那么可以知道需要选择两个最小特征值对应的特征向量进行cut。
- 首先自然选取的是最后一个,这说的意义是:需要把最后一个结点单独割开,其他的结点暂时不管。
- 倒数第二个特征向量,两个正数,说明第二,第三个点是同一类的,割为一类。那么最后得到:\(\{1,\{2,3\},4\}\)
PCA矩阵分析
直观理解
仿佛在之前从来没有认真想过,PCA为什么要选取k个最大特征值对应的特征向量进行降维?之前对于PCA的理解只是停留在:
矩阵分解可以得到其主方向,主方向的保留可以保留矩阵的更多信息。
但是这只是直观上的理解,“信息”保留的多少并没有得到数学上的推导,只能算作对PCA理论的通俗理解。所以PCA为什么要选取最大k个特征值对应的特征向量?
首先,PCA分解的是什么?经过【去中心化】【标准差归一化的】数据,数据在经过如上的白化处理之后,需要进行\(\pmb{x}\pmb{x}^T\)操作,得到其协方差矩阵,维度 d * d,d为特征空间的维数,降维实际上就是要组合特征。那么协方差矩阵\(\Sigma\)有什么特殊之处? \[ \begin{equation}\label{svd} \text{SVD}(\Sigma)=USU^T \end{equation} \]
直接进行SVD分解,由于\(\Sigma\)的对称性,可以得到如公式\(\eqref{svd}\)所示的分解式,其中S是对角矩阵。如果说其他矩阵的分解结果没有那么直观的物理意义的话,PCA则完全不一样。对协方差的矩阵分解有非常清晰的物理意义:\(S\)是“标准”的协方差,也就是在没有经过旋转的方差。可以给一个简单的高斯函数的例子。
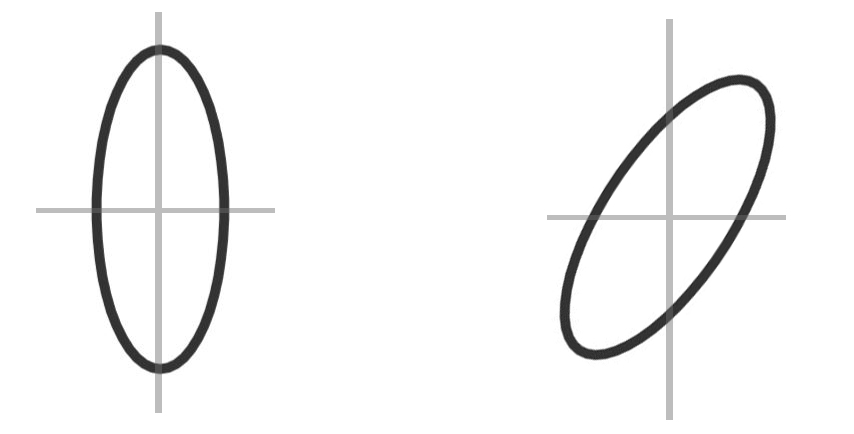
而\(U\)的意义则是:对方差进行旋转。那么也就是说,分解得到了:独立时的协方差矩阵\(S\)以及协方差矩阵\(S\)如何旋转得到当前的\(\Sigma\)。而恰好,\(S\)对角元素对应了特征值。特征值大等价于独立时的方差大,而\(U\)特征向量则是:对于d个特征的线性组合向量(比如\((1\;\;3\;-2)^T\),其意义就是新的组合特征:一份特征一 加 三份特征二再减去两份的特征三),在对应特征向量也就是独立情况下,按照特征向量组合的特征在这个空间下的方差就是特征值。
特征分量差异期望最大
那么我们希望投影之后,数据之间还能有比较好的区分度(如果全部投影到一个点上了,那么就说明投影后的大部分信息都损失了),于是要选择方差大的方向投影。可以这样具体地看:对于一个特征(特征空间的一个分量),假设有两个样本\(\pmb{x}_1\)与\(\pmb{x}_2\),样本(1 * d)在经过一个一维的线性变换之后变成了一个标量(也就是求新特征的一个维度,综合(线性组合)原来所有维度的信息),设为\(z_1,z_2\),那么为了使得任意两个样本产生的新特征差异期望尽可能大 \[ \begin{align} &z_1=F^T\pmb{x}_1\\ &z_2=F^T\pmb{x}_2\\ &\text{max } \mathbb E((z_1-z_2)^2)=\mathbb E(F^T(\pmb{x}_1-\pmb{x}_2)(\pmb{x}_1-\pmb{x}_2)^TF)\label{obj}\\ &\text{s.t. }\Vert F\Vert=1 \end{align} \]
由于F是确定性的变换,所以实际只需要对内部的\((\pmb{x}_1-\pmb{x}_2)((\pmb{x}_1-\pmb{x}_2))^T\)进行期望求取即可,可知这个实际上就是协方差矩阵\(\Sigma\)。那么公式\(\eqref{obj}\)实际上变成了下式(注意F有约束) \[ \begin{equation} \text{max } \mathbb{E}(F^T\Sigma F) \end{equation} \]
也就是求这个二次型(标量结果)的最大。由特征向量构成等价线性空间基的性质以及特征值存在一定取值范围,可知差异最大就是要选取最大的特征值。也就是说,选取前k个最大的特征值是完全能够保证新特征在特征空间下,样本间两两差异的期望最大。
啊,其实这个解释多么接近正确答案啊。我在4.17晚上复习LDA的时候,突然想到了如何正确地从数学角度而非直观角度解释为什么需要选择最大特征值对应的特征向量。LDA中(可见于博文[线性/树型分类器的纯理论分析]),LDA巧妙变换了类间方差和类内方差的表示形式。而PCA中,实际上也是相求方差最大!并且还是类内方差,因为我们希望降维后的数据能够有最好的区分度,保留的信息量最大,也就对应着方差最大,个体差异大代表了丰富性。假设降维到1维,也即需要寻找一个线性组合向量\(w_{k\times 1}\),使得投影后(线性组合后)的特征向量\(y=w^T\pmb{x}_{k\times 1}\)方差最大,也即: \[ \begin{equation}\label{max2} \text{max }\sum^{n}(y_i-\overline y)^2\rightarrow \text{max }\sum^{n}(w^T\pmb{x}_i-w^T\overline {\pmb{x}})^2 \end{equation} \]
那么把非随机变量\(w\)提出来有: \[ \begin{align} \label{max3} &\text{max }\sum^{n}(y_i-\overline y)^2\rightarrow \text{max }\sum^{n}w^T(\pmb{x}_i-\overline {\pmb{x}})(\pmb{x}_i-\overline {\pmb{x}})^Tw\rightarrow \\ &\text{max }w^T\sum^{n}(\pmb{x}_i-\overline {\pmb{x}})(\pmb{x}_i-\overline {\pmb{x}})^Tw \end{align} \]
像LDA一样,把\(\sum^{n}(\pmb{x}_i-\overline {\pmb{x}})(\pmb{x}_i-\overline {\pmb{x}})^T\)设为类内散度矩阵\(S_w\),其意义就是对原空间下方差的一种度量。这样我们可以求\(\eqref{max3}\)定义的最大化问题了,但是还有个小小的问题:\(w\)的模长可以无限大,导致\(\eqref{max3}\)无限大。那么我们只需要限定\(w\)是单位向量,模长为1即可(实际上,这恰好符合之后矩阵分解\(w\)为特征向量的特性): \[ \begin{equation}\label{max4} \text{max }w^TS_bw\\ \text{s.t. } \Vert w\Vert=1 \end{equation} \]
则根据Lagrange乘子,可以写为: \[ \begin{equation}\label{lag} \text{max }w^TS_bw - \lambda (w^Tw-1)\\ \end{equation} \]
KKT条件,对\(w\)求导,使用分子布局(结果转置,那分子布局和分母布局没有什么不同): \[ \begin{equation}\label{res} S_bw=\lambda w \end{equation} \]
也就是说,\(w\)为一个特征向量(我们的线性组合是个特征向量,\(S_b\)的特征向量,\(S_b\)恰好是原来样本的协方差矩阵)。而根据\(\eqref{res}\),等式左右左乘以\(w^T\),得到:\(w^TS_bw=\lambda w^Tw\),根据\(w^Tw=1\),可知,\(w^TS_bw=\lambda\)。又由于需要让\(w^TS_bw\)最大,那么\(\lambda\)作为特征值需要选择最大的。在多维的情况下,最大的被选走了,就按照特征值大小排序,依次选取次大的特征值对应的特征向量即可。
这样就可以明白,为什么PCA要选择最大的特征值对应的特征向量作为降维组合方式了。很可惜的是,在\(\eqref{obj}\)式分析时,并没有这样去思考,但是原来的想法已经非常接近这个我认为最有解释力的答案了。