被SCAE折磨的一天
SCAE
I. Intros
在复现完CapsNet第一版之后,想复现这篇论文(第三版CapsNet:Stacked Capsule Autoencoders, Adam R. Kosiorek, et al.)。复现的基础是看懂,理解其意义。本篇博客为我读这篇论文时的一些思考,其中当然还有些(很多)不够透彻的地方。要是完全透彻了我估计就可以直接动手复现了。
II. CCAE
2.1 CCAE结构
很顶啊,CCAE上来就使用Set Transformer进行了特征学习,变形金刚牛逼:
- 输入一堆n维向量,输出是一堆object
capsules(k个)。这个capsules包含:
- object—viewer 3 * 3图像仿射变换(9)
- feature向量(未知)
- 此capsule表示的物体是否存在的概率(1)
- 此部分为Transformer输入输出,n输入->k胶囊输出
- 每个胶囊都会进行内部的MLP,这个MLP将利用自己的特征向量(比如自己是\(\pmb{c}_k\))去推测,N个候选的part(这个part就是物体部件)的相关信息:
- 此后的MLP学习的是:部件 / 物体的变换,而已经学到的有:物体 / 观测者(也就是部件在图像上的pose),那么部件 / 观测者的位姿变换也就有了。
- 学习条件概率(这个涉及到CCAE高斯混合体的理解),\(a_{k, n}\)
\[ \begin{equation} a_{k, n}=P(p_n|cap_k) \end{equation} \]
也即,一个object capsule k存在时,部件n存在的概率。而之前在Set transformer实际上学习了,cap k存在的概率,那么实际上结合起来就可以得到联合概率。
我感觉这里做了一个很妙的最大后验估计操作,理解一下:
- 使用高斯混合模型,那么其中的高斯分布参数:均值是原有高斯分布均值经过OV,OP位姿变换得到的,而协方差已经经过MLP学习到了。我们可以通过均值和协方差写出:
\[ \begin{equation} p(\pmb{x}_m|k,n)=N(\pmb{x}_m|\mu_{k,n},\lambda_{k,n}) \end{equation} \]
结合这个高斯混合 + 极大似然的意义,我们再来理解一下均值和方差以及其对应下标的意义。
2.2 CCAE & MLE
对于论文中的公式(5): \[ \begin{equation} p(\mathbf{x}_{1:M})=\prod_{m=1}^M\sum_{k=1}^K \sum_{n=1}^{N} \frac{a_ka_{k,n}} {\sum_i\left(a_i\sum_ja_{i,j}\right)} p(\mathbf{x}_m|k,n) \end{equation} \] 个人的理解是,对于给定的一张图像:
- 一方面,我们可以通过Set Transformer 求出k个object capsules,再由这学习到的k个capsule组成n个物体部件,也就是学习一些隐含信息
- 另一方面,我们可以根据隐含信息重构物体,我们认为物体是由抽象的几个部件组成的,部件的生成与object capsules也有一定关系。那么部件以及object capsules产生的贡献可以被写为 \(p(\pmb{x}_m|k,n)\),换句话说,就是:我从图像(训练集)上学习出object capsule给定为k且存在部件为n的情况下,为目标\(\pmb{x}_m\)的概率。
训练集可以看作是样本总体分布的抽样,那么在根据样本进行学习时,可以使用极大似然估计的方法:使得抽样(训练集)出现的概率最大,也就是: \[ \begin{equation} \max P(X)=\max\prod_{i=1}^nP(\pmb{x}_i) \end{equation} \] 在这里\(p(\pmb{x}_m|k,n)\)只是条件概率,我们需要去掉条件部分,所以需要根据之前Set Transformer以及MLP的输出,可以得到: \[ \begin{equation} \frac{a_ka_{k,n}}{\sum_i\left(a_i\sum_ja_{i,j}\right)}=\frac{p(k,n)}{\sum_i\sum_jp(i,j)}=p(k,n) \end{equation} \] 那么公式5很容易从左边转化为右边。而左边和右边相等的意义是?
- 左式是我们的目标函数(极大似然估计需要最大化的联合概率分布,由于训练集是独立同分布的)
- 右式是由特征提取 / 训练 的输出构成的:
- \(p(\pmb{x}_m|k,n)\)是高斯混合体,高斯分布的参数一方面由Set Transformer的OV / MLP的OP对原均值进行线性变换组成,另一方面则是MLP直接输出的方差值。GM模型可以是多个高斯混合在一起形成的,所以其参数很多。
- \(a_k,a_{k,n}\)是由Set Transformer / MLP分别输出的。
- 那么右式由于是网络输出的结果,是存在网络参数的,可以对输出进行一定的loss变换之后,对其求导以调整网络参数。
part capsules是什么?输入的原始数据向量就是part capsule,但是为什么叫part capsule?可能在后续的论文中会提到,下面第一次提到 part capsules,但是貌似是由别的东西来“替代”真正的 part capsules 来进行说明:
All input points (which take the role of part capsules).
III PCAE
PCAE用于获得part templates,也就是学习模板。比如说:
- 我们先通过encoder(结构是CNN特征提取 + Attention
Pooling,所以Attention思想你还是得王权搞明白啊)从图像中学习一些表征(part
capsule)出来:
- pose,比如旋转 / 缩放 / 斜切 / 平移,出现的概率,特征向量(独特属性)
- 特征向量可以用于推测模板的颜色等等抽象信息(MLP),比如从特征向量中,直接获得模板输出的三通道强度(也就是模板图像本身的值)
- 得到模板之后,通过pose进行仿射变换
- 注意模板本身会携带一个alpha通道,相当于我们搞PS的时候,为了使图抹更加真实,调整画笔透明度,允许不同的templates叠在一起。
- 图像上每一点的输出,实际上都是不同的part按照概率 + alpha通道结合得到的(相当于一个decoder操作),使之与原图接近,或者可以说成是:对原图的极大似然估计。
那么一套流程下来,实际上我们要得到是一个可以生成part capsule的auto encoder,之后的decoder层个人认为:只是用于计算loss或者产生一个part capsule生成好坏的evaluation方法。以上的文字叙述部分已经把PCAE的思想概括了一下,这是个人开始的理解,其中存在一些偏差:
此论文中的Template不是学出来的?使用的是Fixed templates?(4通道)
就是说我对现有的part templates,学习变换(pose),独有特征(比如MLP输出颜色),出现概率。虽然我感觉论文的这三句话有点冲突:
I. while the decoder learns an image template \(T_m\) for each part
SCAE under-performs on CIFAR10, which could be because of using fixed templates, which are not expressive enough to model real data
Training the PCAE results in learning templates for object parts
所以开始时晕了,到底是学出来的还是给定的?个人感觉学出来的templates肯定是更加不错的(只要学得好就行,作者自己也承认)。
IV. OCAE
4.1 OCAE作用
OCAE:通过已经学习到的part capsule去组成object(这个和PCAE的decoder区别在哪?)。OCAE与之前的CCAE很类似,但是它受到了来自part capsule的概率影响:
OCAE与CCAE结构类似,也存在Set Transformer的encoder,那么part capsules输出的概率会影响encoder,使得Transformer忽略一些没有出现的输入(或者说part)。part capsules输出的概率会使得log likelihood(在MLE过程中)进行幂加权,使得概率小者造成的影响小
个人感觉,由于OCAE结构上很类似CCAE,CCAE的输入是简单的星星点,那么OCAE应该是CCAE的一般化:
We first encode all input points (which take the role of part capsules)
所以这里说的就是这个意思,CCAE是:
- 输入是简单点而非part capsules的OCAE
- 一些part capsule 概率加权不存在的OCAE
CCAE最后求出了part capsule的似然(作为MLE的优化目标),而PCAE自己也有关于自己生成的part capsule的似然。
4.2 OCAE / CCAE 联系谈
CCAE部分,作者已经说了,CCAE的输入是简单的星座点。而一般化的OCAE,输入是上层PCAE的part capsule输出:
In the first stage, the model predicts presences and poses of part templates directly from the image and tries to reconstruct the image by appropriately arranging the templates. In the second stage, SCAE predicts parameters of a few object capsules, which are then used to reconstruct part poses. ---From Abstract
个人的理解就是:PCAE为first stage,其目的是得到templates,学习templates的目标函数通过"reconstruct the image"来完成。OCAE就是接收stage I输出的second stage,通过学习object又来反推part pose?
所以明确目的是多么重要!PCAE并没有得到用于MLE的log likelihood,论文中的公式(9),(10)都是为了构建PCAE的loss(重构图像的重构loss),可以这么说:
- 一个普通的CNN分类网络,其输出结构可以用于直接计算loss,我们使用的也就是其输出结果
- 而PCAE,输出结果需要经过一定变换(reconstructed image),才能用于构建loss,而用于构建loss的部分,并不是我们使用的那部分。PCAE的目的是获得一个好的image template。
- 之前的部分已经说过了,CCAE(特殊化的OCAE):
- 首先经过Set Transformer学习K个object capsules。
- 每个object capsule都会使用MLP(M个MLP),学出组成这个object的M个part,但这个学习过程不涉及到具体的part capsule输出,输出的是:OP,条件概率以及协方差,用于获得GMM的分布
4.3 OCAE的作用
为什么OCAE又要重构part?它具体重构了part的什么部分?达到了什么效果?这是本篇论文的一个重点问题,作者在一行脚注里这么说:
Discovered objects are not used top-down to refine the presences or poses of the parts during inference. However, the derivatives backpropagated via OCAE refine the lower-level encoder network that infers the parts.
可能可以这么理解:
- PCAE学出来的part capsules,需要经过检验。这样的part组成object到底合不合适?这种合适度通过likelihood来衡量。
- 如果说,part capsules直接重建图像,是一种直接的具体的metrics,OCAE对应的likelihood就是抽象的metrics。如果要用极大似然的思想来解释:
It learns to discover further structure in previously identified parts.
此处的衡量metrics是part likelihood,是通过:
- 与object capsules有关的一个条件概率分布(比如CCAE中的高斯混合分布),与object学习过程中的其他概率组成,相当于是:MLE在优化的过程中,只优化\(p(x|\theta)\)的参数\(\theta\)部分,而此处由BP,会将MLE的“抽样”\(x\)一起进行优化,使得\(p(x|\theta)\)最大。
- 虽然我感觉这样就不是MLE了,但可能可以这么理解吧:我学习的分布,参数是\(\theta\),已经能很好地表示真实情况(总体分布)了,考虑到我如此强而输入有一定噪声,那输入也进行一定的修改吧,因为学到的分布觉得你的输入有些问题。这MLE可以说是很另类的了。
- 所以总结起来就是:通过一层抽象的学习,MLE同时优化object capsule生成网络参数(\(\theta\))也反过来优化输入(输入就是part capsules)
V. Sparse Regularization
论文中说,直接使用Capsules结构,容易导致:
- object capsules滥用,导致难以训练 +
模型描述力下降(显然,有些object不存在于一些图片中,但是还要用对应object强行解释,这是不行的)
- 与之相对的,我们希望每个图像能有特定的少量object capsules(以及相应的part capsules)来描述
- mode collapse,只使用特定的一些object,发生过拟合。
- 与之相对的,我们希望对于整个训练集,object capsules尽量都能用上(否则相当于是出现了训练集label分布不均的情况)
那么,作者设计了两个正则化项,用期望的思想很好理解了:
- \(\bar{u}_k\)是第k个object capsule的出现概率总和(对不同的样本):
\[ \begin{align} & \bar{u}_k=\sum_{b=1}^M a_{b,k}^{\text{prior}} \label{uni_b}\\ & \bar{u}_b=\sum_{k=1}^K a_{b,k}^{\text{prior}} \label{uni_k}\\ \end{align} \]
则我们希望,不同的类别能用上尽可能一样数量的object capsules,假设有C类,K个object capsules,那么每一类可以用:\(K/C\)个capsules来描述。而由于对于K个capsules,每个出现的概率是\(a_k^{\text{prior}}\),每一个capsule出现的期望(因为是两点分布)就是概率本身,那么根据期望的运算,一个minibatch内B个训练用例,期望capsule数量应该是公式\(\eqref{uni_b}\)。则我们令\(\bar{u}_k\leftrightarrow K/C\)两者足够接近即可。
另一方面,我们希望:每个用例能仅用部分object capsules来描述。假设总体不同class均匀分布,那么一个minibatch内部,每个类别有\(B/C\)类,那么每个用例object capsules的期望实际上就是公式\(\eqref{uni_k}\)定义的概率和,那么可以得到论文中的第一个稀疏性先验。
后验稀疏性很好理解,可以认为是LDA思想:类内熵最小化,类间熵最大化(也即类内的后验分布趋于一致,类间趋于不同)。
TODOs
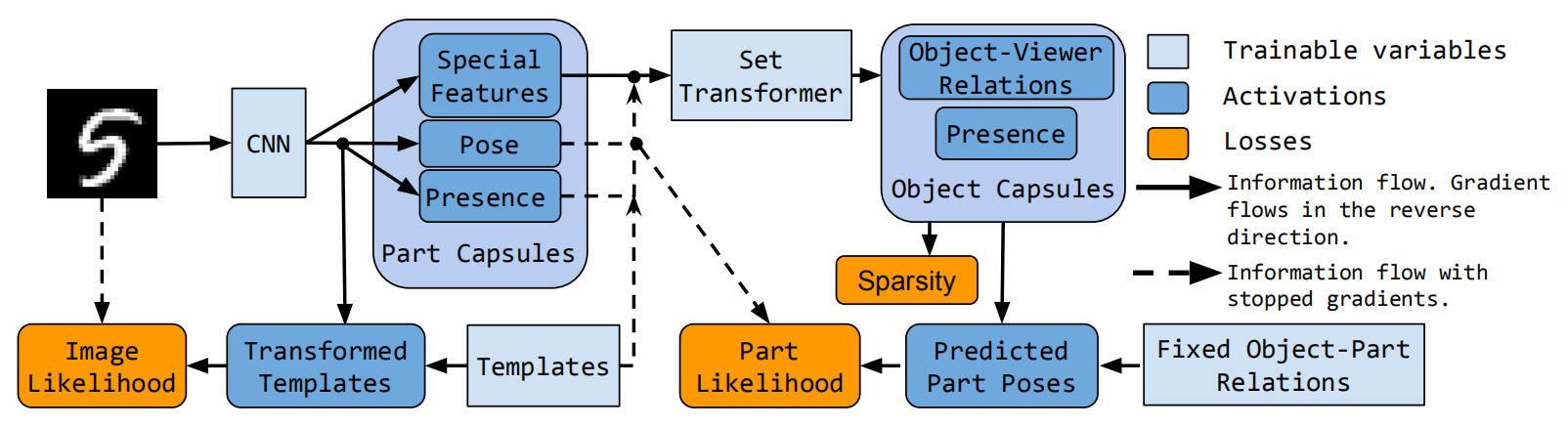
本论文看第一遍之后,感觉实现部分很模糊,论文图6感觉好像也非常粗略,前面的Attention机制也没有特别体现(只在Part Capsules到Object Capsule时有),但是前面所说的 Part Capsules特征提取部分应该也包括了Attention-based pooling。梯度阻断机制也让我觉得有点奇怪,templates方面也有相关问题没理解。那么在过段时间重读这篇论文时,希望能够在这几个问题上得到更好的理解:
需要进一步理解的问题们:
Attention都在什么地方使用到了?为什么schematic图中看起来只有一处?
- 个人认为只是没写出来罢了,只要是capsule autoencoders就逃不开attention机制,内部会有一个类似CCAE的(attention + MLP)实现,当然对于part capsules来说,可能更加复杂。
Capsule在schematic图里面是输出还是网络层?个人的感觉应该是网络层,Part Capsule之上还stack了很多个Object Capsules,但是具体结构为何?
Templates为什么没有来自CNN或者Part Capsules的梯度流?
- 个人感觉:Transformed templates可以组成图像,而由于capsules携带transformation信息,templates应该可以直接去transform得到,但是为何templates到 tf templates也有梯度?
- 既然Templates被标注为Trainable variables,为什么说templates是fixed的?
- Template的color是学出来的,而color可以被认为是三通道的图像,那么templates在图像上的值不也就是学出来的了吗?
Fixed Object-Part Relations是什么?在哪里起作用?
PCAE / OCAE的作用,虽然现在感觉自己懂了,但是总有种说不上来的“不透彻感”。