【笔记】两篇双目相关论文
Stereo!
最开始的时候,我在人机所的工作是搞双目开发,但是当时还完全不懂深度学习,觉得这就是个玄学玩意(事实上我现在还是这么觉得,只不过有些简单的网络,具有很好的理论解释,我觉得还挺妙的)。但是当年(也就是2020)的KITTI榜就已经被深度学习刷爆了啊,前100目测98个非传统方法。现在我对深度学习有了一定了解,也有了很多实践的经验,所以想着挑战一些更难的问题领域,一些不一样的应用场景(毕竟老研究奇奇怪怪的网络结构,复现不同的CV基础网络结构就跟调参一点区别没有)。
本文没有任何附带的实现,我只把这两篇CVPR2021论文只作为回归双目研究的起始“研读性”文章,不尝试复现,或者咱们不找借口,我之后理解得更透彻再来复现😝。
II. A Decomposition Model for Stereo Matching[1]
加速了。作者能加速10-100倍,并且把复杂度降得很低,使用的思想我之前思考过,但是我之前并不知道怎么做,只是有个类似的想法:
如果我只需要在一个较小的图像上进行双目匹配(下采样图像),在上采样的过程中使用另一个网络进行refine,只需要对部分像素进行refine,是不是能提速?
产生这个想法的原因很简单,之前在尝试孙剑老师的“上古”论文(BP)时,对于无纹理区域的匹配效果不太好。大面积无纹理区域在下采样图像中就应该被解决。
2.1 主要思想
首先把网络总结构放一下:
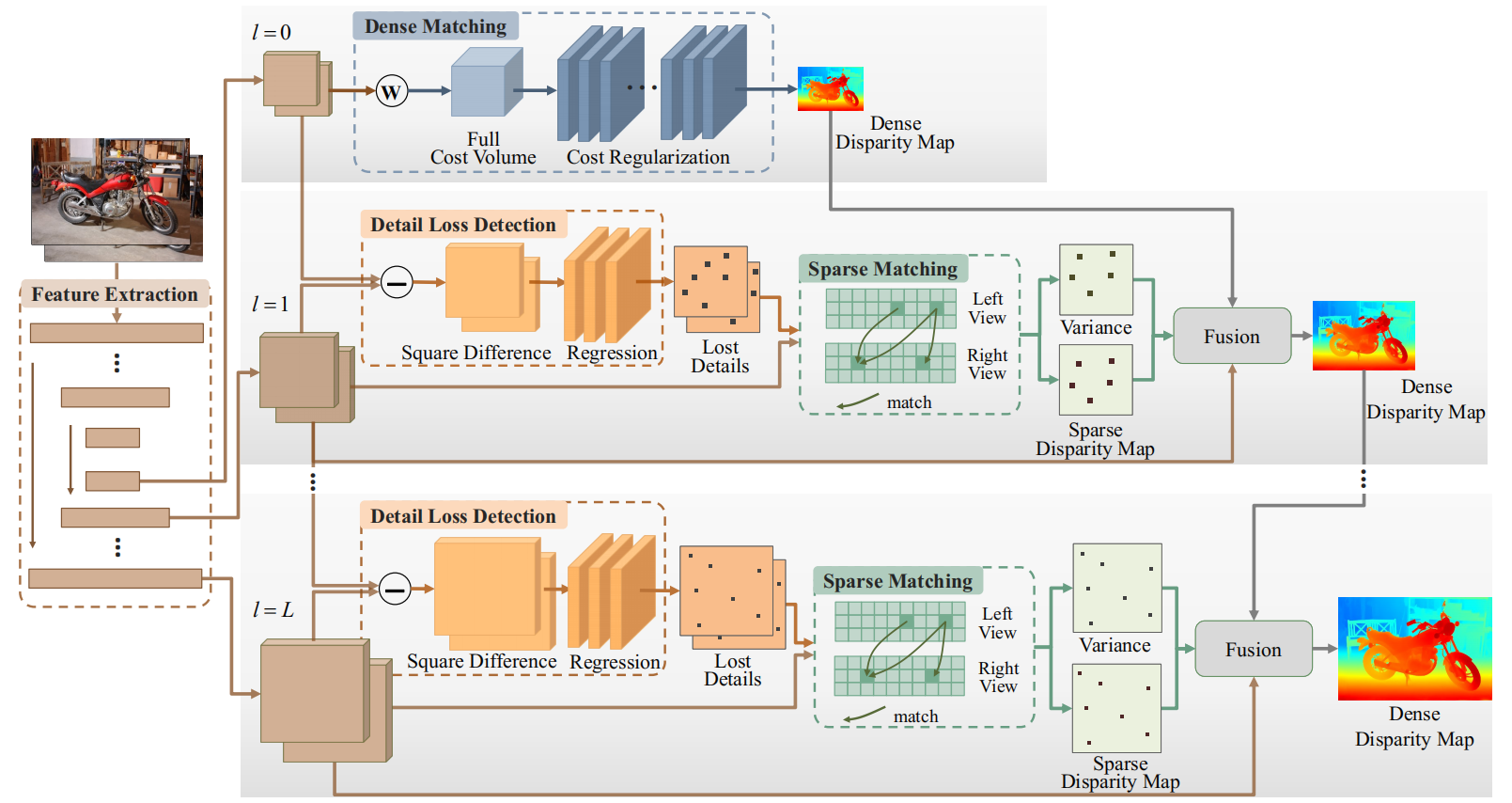
读完还是觉得这篇文章里有些很魔法的东西,但是也有很不错的思想。文章的方法主要可以分为以下四步:
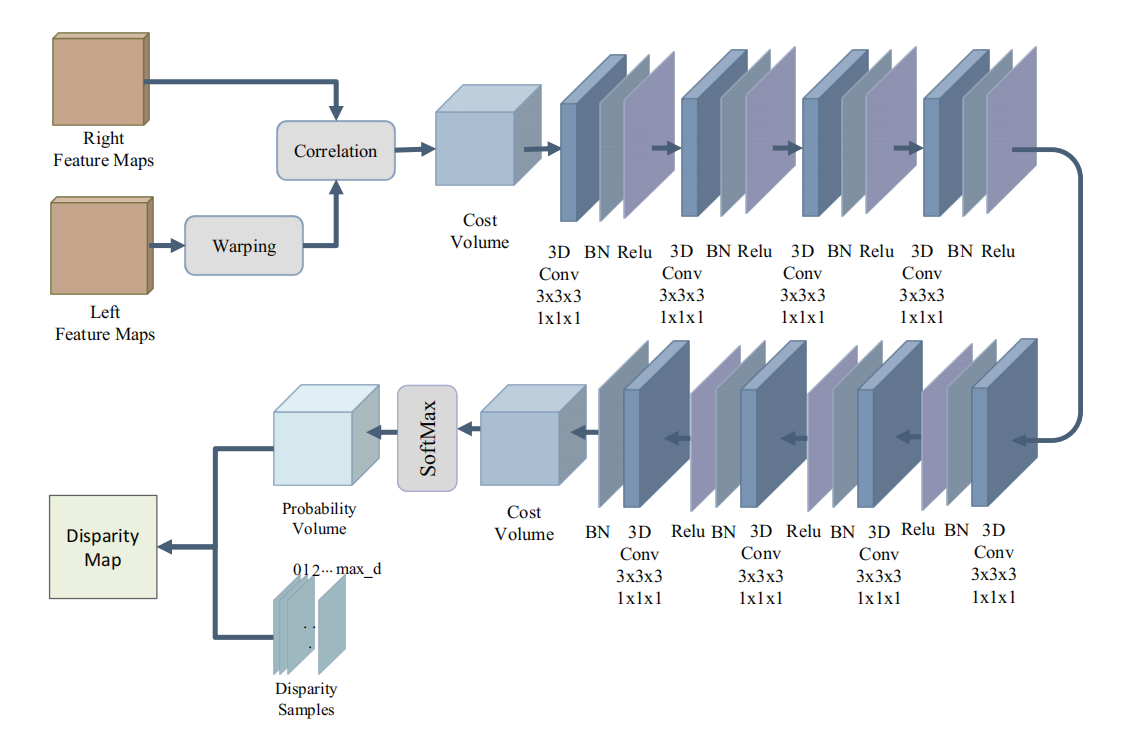
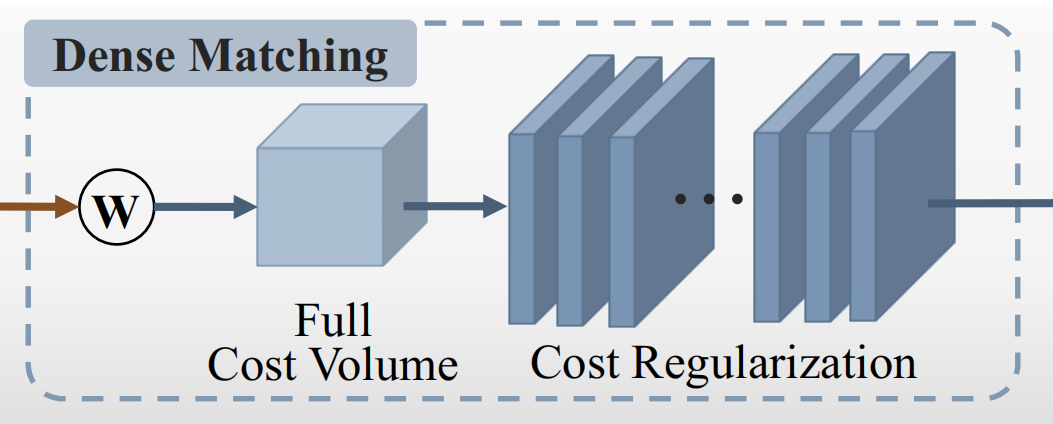
- 最底层使用full cost volume(可以认为是双目匹配里面的内存暴力法)以及cost regularization(文中使用了一个如Figure 3所示的网络,对cost volume又重新映射了一边)。文章称cost regularization的作用是“rectify cost volume”,但是我半天没看明白这和rectify的关系(双目就有rectification操作,难不成是用Conv3d做了一个深度rectification?)。在这样固定大小的左右视图上进行full cost volume匹配的开销是完全可以接受的。
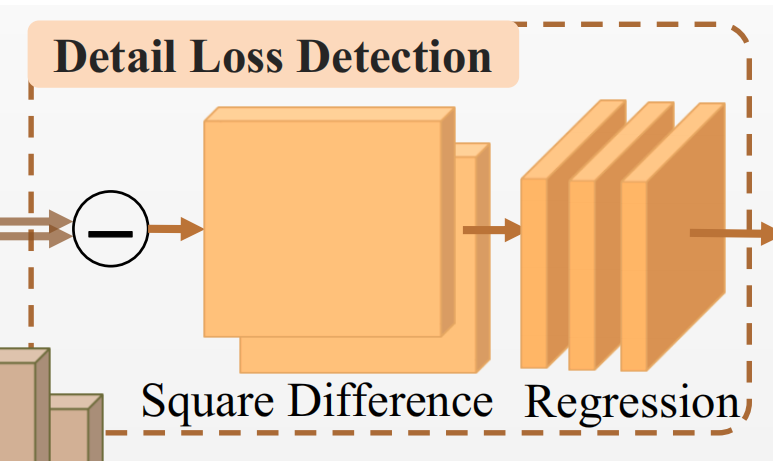
- 【稀疏的【损失细节】】检测。也就是使用一个无监督的网络,输入是:特征金字塔上一层(经过下采样的一层)的特征图的上采样结果,和特征金字塔本层特征图。无监督地学出可能因为下采样操作而丢失的特征(对应的position)。无监督学习,就是nice。
- 稀疏匹配。既然在上一步操作中,我们已经清楚有些地方就是没有匹配好,那么这一步我可以对那些没有匹配好的【损失细节】进行稀疏的匹配。由于稀疏匹配对应的特征们分布不规则并且大小不固定,使用cost volume搜索对应的方法是不好的。论文使用了一种agreement思想,使用cross correlation(相当于找到最大“卷积”响应点),转换结果为softmax,再求期望,这个想法不错。
- 视差融合。也就是稀疏视差图融合到稠密视差图上的操作。这个操作又分为两步:
- 视差图上采样。要把上一层视差金字塔的结果用上我总要上采样吧,但是做固定上采样不好玩,我们来搞一个CARAFE[2] ,一种更骚的上采样方法,具有【content-aware】能力,很玄乎吧,这个还好。最玄乎的是它做了一个大concatenation(我很讨厌无端的concat操作,把不相关的信息拼接在一起会让信息失去其原有的物理意义,这是个人粗浅的见解,会在稍后进行说明),对concat的结果进行了几次卷积,得到一个mask(也就是content-aware的权重),通过这个pixel-wise的权重将上一层上采样视差和本层融合。
2.2 Gradient Flow
我们需要考虑梯度流的问题,也就是说:我到底需要优化谁?我的loss最终作用在哪些单元?在没有看附录之前,就应该思考这样的问题。
首先我们发现,这篇文章不是pixel2pixel的匹配,而是特征到特征的匹配(可能深度学习上了就是这样的),特征提取在文章中说的是:
As shown in Figure 2, we first use U-Net to obtain deep features Fl on each level l for the stereo matching.
我当时反应了一下,之前读过一篇做风格迁移的文章(对应博客【CNN Style Transfer论文复现】,截止到9.5我都还没有填坑),文章直接使用了一个预训练好的VGG-19,固定参数不优化,提取特征。本文是这样吗?并不是,特征提取网络是需要进行优化的。那么与loss直接相关的待优化参数最后除了特征提取网络之外,还有什么吗?
 |
 |
|---|---|
| 步骤II | 步骤I |
这两个步骤虽然在网络中,但是其参数并不直接根据整个架构对应的输出以及loss进行优化。毕竟:
- 步骤II对应的操作是自监督的,应该完全可以独立训练
- 步骤I也是可以独立的(看实现),假如使用的方法是独立于输入的传统cost volume法,那完全可以。否则的话可能会收到U-Net输出的影响,内部的参数也需要参与优化。
在附录中,作者主要讨论的是U-Net生成的特征图作为自变量时的求导。
2.3 一些问题
2.3.1 Detailed Loss Detection
无监督的loss听起来很棒,但是我总感觉作者用学习的方式解决了一个NP-hard的问题(应该是NP-hard),我甚至有点怀疑可行性(虽然我在RM灯条检测里面也这么干过)。
如果需要人工标注lost detail mask的话,那工作量太大了,作者希望使用这样一个无监督loss,使得两个集合的差异最大:属于lost detail的特征点集合(A) 与 不属于前一个集合的特征点集合(B)(是一个覆盖)
差异体现在:集合A的平均特征误差应该较大(低精度上采样后无法恢复的区域),集合B的平均特征误差小。那么作者使用了这个loss: \[ \begin{equation}\label{dld} \mathcal{L}^{DLD}=|FA_l|-\alpha\frac{\sum_{(h,w)\in FA_l}\Vert F_l(h, w)-F_{l-1}'(h,w)\Vert_2}{\vert FA_l \vert} \end{equation} \] 其中\(FA_l\)为特征金字塔第l层的fine-grained(细粒度)特征,\(F_{l-1}'\)则是上采样的上一层特征。这个式子非常容易理解,但是... 从一个集合中挑选一个子集使得对于这个集合和子集定义的某个损失最小,感觉就是一个NP-hard的问题,毕竟暴力穷举之外貌似没有别的方法。并且,在这里优化问题遇到的是 分支的处理,我优化的是一个决策?(应不应该认为这个特征属于\(FA_l\)),我记得好像TF由于是静态图的缘故不方便设置分支?另一方面,我又觉得解决方案可能类似分类问题,输出是模拟的,但是计算cross entropy loss的时候转换成了long型(硬的)的index。
2.3.2 Sparse Matching
这个想法我觉得还挺不错的。我得到左右视图的lost details,现在要进行匹配了。由于occlusion存在一定一致性(并且由于存在对极约束),还是可以将lost details在一个方向左右滑动。那么对于这样的:两个信号滑动求最大匹配的问题,显然可以使用cross correlation。作者由此产生了一个三维空间的概率volume(注意不是分布,因为这是按照第三个维度也就是disparity归一化的)。 \[ \begin{align} & P_l(h,w,d)=\frac{e^{C_l(h,w,d)-C_l^{max}(h,w)}}{\sum_{d=0}e^{C_l(h,w,d)-C_l^{max}(h,w)}}\\ & C_l(h,w,d)=\text{cross correlation}(F_{\text{left}}(h,w),F_{\text{right}}(h,w-d))\\ & C_l^{max}(h,w)=\max_d C_l(h,w,d) \end{align} \] 最后,每个稀疏点的视差就由期望决定了(作者为什么把这个叫做regress?) \[ \begin{equation}\label{reg} \hat{D}_l(h,w)=\sum_{d=0}P_l(h,w,d)\times d \end{equation} \]
2.3.3 Supervised Loss
简单地提一下论文使用的有监督loss。无监督loss在lost detail detection阶段使用了,用于判定哪些是丢失细节,见公式\(\eqref{dld}\)。而计算视差图的过程中,我们有特征提取网络,Fusion网络,底层full cost volume对应的网络需要训练,这些都是基于disparity真值训练的。
多层的disparity就需要用到多层的真值,那么多层真值可以使用降采样来得到。然后作者使用了一系列的smooth L1 Loss。好玄乎哦,实际上就是Huber Loss。
III. SMD-Nets: Stereo Mixture Density Networks[3]
个人认为这篇文章没有那么魔法,读起来觉得还挺有道理的。最主要的思想就是:使用双模态描述结果。之前读的对比学习相关的文章,里面就提到过不同的模态数的优缺点:
- 单模态:计算十分方便,建模简单,并且也具有广泛的应用范围,但表征能力有限。
- 完全生成式模型(终极多模态):表征能力极其强,但是计算量一般都很大(比如对抗网络)
- 模态数少一些的多模表征:折衷。
本文使用双模态描述前景和背景,并且网络结构 / 输入不那么魔法,也具有一定的超分辨率能力(虽然感觉方法有点普通?)。
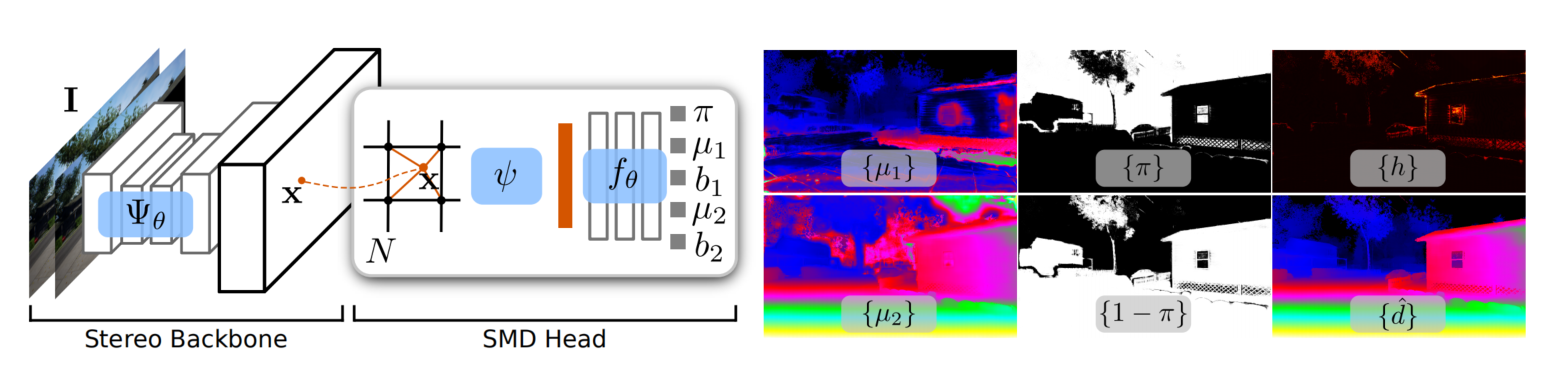
3.1 主要思想
主要可以分为以下三步:
- 前端使用了一个经典的双目视觉网络作为骨架,用于提取特征。就如Figure 4最左边,先下采样再上采样的典型结构(常用于Semantic/Detection/Mono/Stereo)。我不是特别了解这个网络提取出来的特征是否与原输入图像保持了空间一致性,虽然卷积可能可以做到这一点,但具体是如何保证的【一个特定区域】对应的【特征图元素】一定在特征图对应的位置上?而且看起来,深度学习的引入产生了很多特征-特征匹配的方法。
- 超分辨率:插值操作,插值操作只是为了能够得到任意精度位置的特征向量。个人对于第二步的理解是,作者对于每一个点都计算了双模态分布的参数,形成了一个双模态分布的二维结构(图像)。对每一个特征向量,都过一遍MLP,最后得到五个参数:
- \((\mu_1,b_1),(\mu_2,b_2)\)是分布的均值(期望)与不确定度
- \(\pi\)是两个模态的选择参数(相当于前景背景mask)
- 输出:根据模态选择参数,从两个模态中的均值中选择对应的视差值。
3.2 Some points
这篇论文我倒是没有什么特别想说的,感觉想法倒是挺简单的(简单不代表我能一下想到)。虽然我个人存在一些疑问,感觉作者也没有解释清楚(要怪就怪神经网络不可解释?):
- 前景(foreground)与背景(background)的区别在哪?disparity明显很大的叫foreground(虽然我感觉作者就是叫着玩的)?作者更被没有说两个mode的生成方式有何不同。为什么能恰好产生这种,在关键区域有互补性的两个模态呢?又为什么只使用两个模态呢?
- 当然,这确实可以用不可解释性来说。毕竟像\(\pi\)这种学出来的东西,真的就说不清楚其深层次的原理...
另外,我不知道别的网络是否进行稠密的训练,本文中,网络并不进行稠密的disparity训练(可以说是半稠密?)。首先对生成好的特征图进行采样,对采样得到的(稍微稀疏一些)点进行训练。由于作者需要更多地聚焦于边缘点的处理,所以作者使用了一种不同的采样方法:
- 生成边缘点mask,具体的方式也就是:首先检测深度不连续点(根据4-连通性),对检测结果进行膨胀
- 在边缘点mask内采样一半的稀疏训练点样本
- 在全图的非边缘点区域进行均匀的采样,采样得到另一半样本。
整个框架是有监督的,并且没有金字塔结构。其使用的backbone模型,PSM内部也是有一个大的cost volume的。
IV. DL立体匹配
深度学习用在立体匹配中?知道能用,但是具体的实现是什么样的呢?基于特征向量的匹配的流程具体是什么呢?完全不知道了。所以我在这里补充一篇综述性论文[4],帮自己补一补领域知识。只不过,这篇文章包含了很多方法,我在此只讨论基础的DL-based方法。
4.1 Pipeline
主要流程仍然大体相同:

那么典型的几个网络结构,论文也贴心地列了出来(这篇论文真的很适合入门了解行业啊):
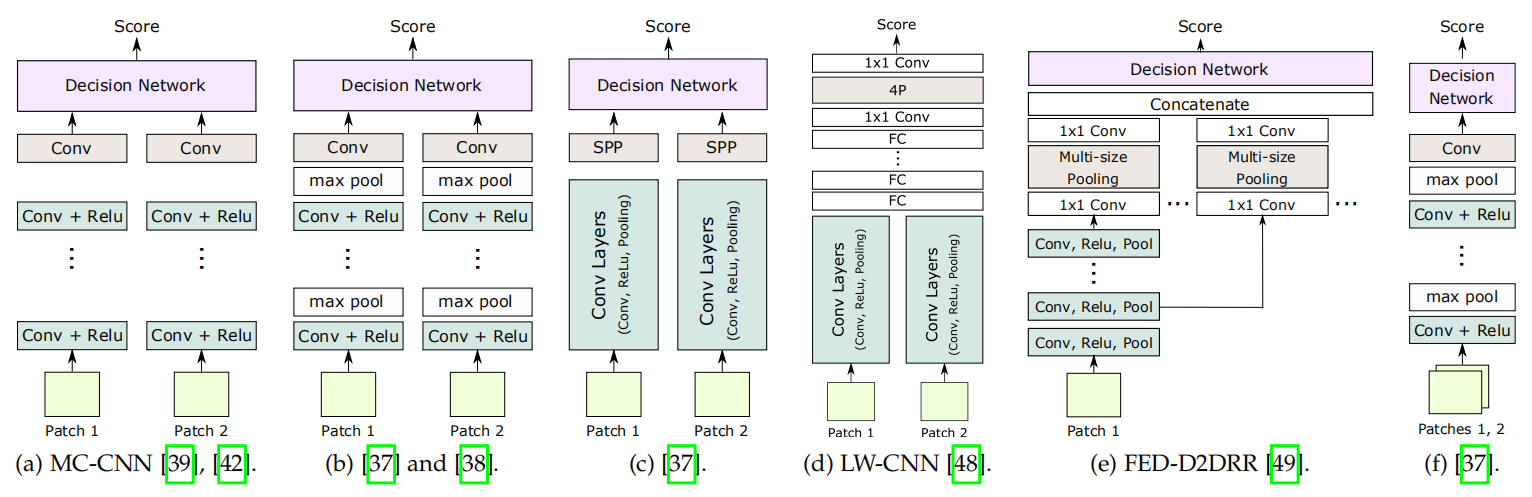
视差图生成网络的训练输入可以通过采样而来,也可以通过直接卷积而来。
- 采样的方法是:在输入图像中均匀“播撒”一些点(对应于一种稀疏的训练方式),切取点以及其领域的信息作为对应视图的输入。如果是有监督的结构,那么就在另一个视图中查找:
- disparity图真值对应位置的patch(作为正样本)
- 其他disparity值对应的patch作为负样本
- 直接卷积:每个点对应的卷积输出就已经是特征了。但是这种方法如何保证左右特征一致?一种简单的想法就是直接共用完全相同的encoder(孪生网络)。
- 当然也可以直接跳过特征描述,直接端到端生成一个cost出来
这种基于DL特征的描述,实际上是对人工描述子的升级,卷积操作对每个点都会有个特异的表征输出,假设我们的卷积就是奇数大小的kernel并且以其中心为anchor,那么在(x,y)位置的卷积显然就会得到以(x,y)为中心的领域特征描述,能保证[3.1中(1)里提出问题的解决]。这一环节,我们的目的不是只得到特征(然后神奇海螺:什么也不做),而是使用特征来衡量两个像素位置是否存在关系,比如使用L1或者L2距离来判定特征的相似度,越相似说明两个位置匹配度越高。
根据loss函数可以计算出一个cost volume,为了方便起见,我只讨论3D cost volume。3D cost volume每一个(x, y)位置都对应了一串可能匹配的cost,我们需要根据我们选定的策略来计算一个最好的disparity。方法有很多。我确实是开了眼了,学到了,见下一小节。
4.2 Cost Volume Regularization
有了cost volume之后,紧接着就要进行cost volume regularization。但是这是个什么操作,与regularization又是什么关系?
我们知道,正则化(regularization)在深度学习中是被用来防止过拟合的,因为引入正则化惩罚之后,原本起伏不平的超平面,会变得平滑。这是因为正则化项要么限制了描述超平面的参数个数,要么限制了其取值,使之描述力下降(不那么活跃)。也就可以认为,正则化项\(\approx\)平滑项。
巧了,双目视觉通常也有平滑项(虽然我感觉SMD-Nets一定程度上在鄙视平滑假设)。我们希望网络的输出不要那么起伏不平的,一个深度差不多的平面就不要因为噪声而有太大的小范围波动了吧。所以需要施加平滑项,当然还存在一些其他的约束项,比如:
- (x, y)已知与(x+d, y)完美配上了,那么(x+1, y) 对应的视差必定不可能小于d-1(右视图匹配不交叉)
- 保证深度不连续边缘锐利性的一些约束项
那么施加约束项/平滑项就是在做正则化!目的就是优化输出图像,所以叫regularization。一般来说,cost volume regularization伴随最终视差图的产生,这是因为regularization之后,full cost就求出来了啊。当然是选full cost最小的。故可以将cost volume regularization看作是视差图求解。
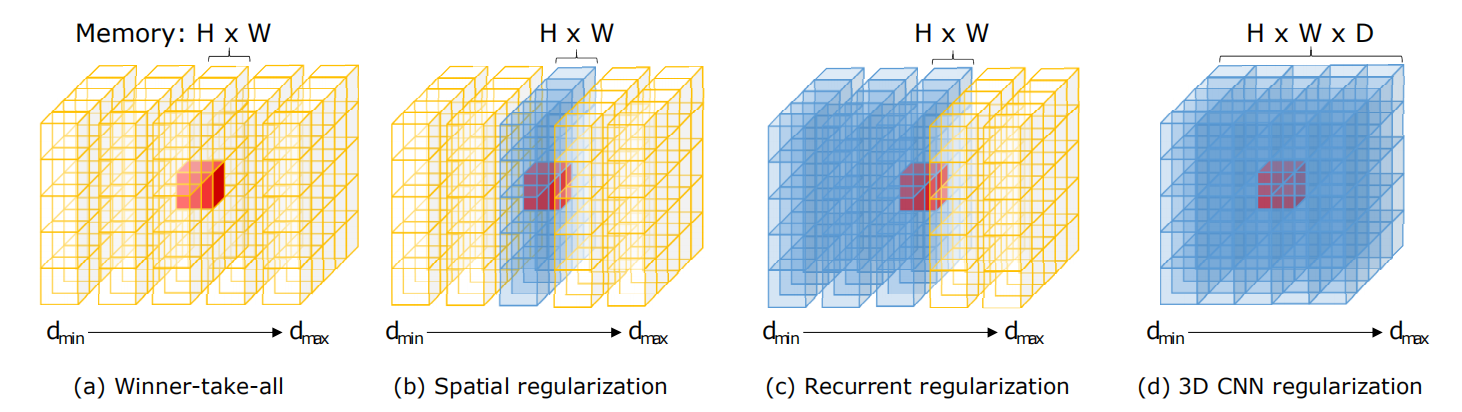
论文贴心地把几种常用的regularization方法可视化了出来:
- 滢者通吃!(误,在这里简单地cue一下我的女朋友)。谁小选谁。
- 考虑空域特性:2D卷积,综合空域信息。
- 考虑不同的disparity上的信息:基于RNN的正则化
- 3D卷积:全域正则化(这个结构在两篇论文的regularization中都有)
Reference
[1] Yao C, Jia Y, Di H, et al. A Decomposition Model for Stereo Matching[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 6091-6100.
[2] Wang. Carafe: Content-aware reassembly of features. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2019
[3] Tosi F, Liao Y, Schmitt C, et al. SMD-Nets: Stereo Mixture Density Networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 8942-8952.
[4] Laga H, Jospin L V, Boussaid F, et al. A survey on deep learning techniques for stereo-based depth estimation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.