CUDA踩坑实录【1】
CUDA I
I. Introduction
在复现A Decomposition Model for Stereo Matching这篇论文的时候,发现其Sparse matching并不是直接的pytorch实现。本来我想直接pytorch了事的,但仔细一思考后觉得虽然反向传播实现不用考虑了,但是整体变得很慢。阅读官方源码发现时看到一些我不太懂的东西,后来我才知道这些是CUDA自定义pytorch算子,是pytorch的CUDA extension。出于以下目的:
- 复习CUDA(特别是在学习完GPU存储结构与计算之后,急需实践)
- 学习setuptools的使用以及torch的CUDA extension写法
我给自己定了一个小型的CUDA任务,与SDF以及marching cubes算法十分相关。项目见[🔗Enigmatisms/CuTorch]
II. 任务设定
在一个800x600的画布内,随机生成一些“泡泡”,这些泡泡在运动过程中应该可以自由地融合。泡泡的融合不是简单地叠加,叠加应当是平滑的。如下图所示:

每个泡泡对应着2D平面上半径为r,中心为(x, y)的一个圆。那么需要计算:
- 每个泡泡对应圆的SDF,并且将其叠加在一起
- 设置一个阈值,跨越此阈值的部分将形成边结构(也就是等高线)
整个小项目的完整知识在这里:【Jamie Wong: Metaballs and Marching Squares】。写得非常不错,6月份做SDF的点云融合时,曾经参考过其marching cubes的实现方法。本文与具体的算法实现没有太大的关系,因为算法本身非常简单。
2.1 基础知识
2.1.1 Dims
grid 与 block是CUDA的分级管理的两个层次,grid相当于是block的集合,而block相当于是thread的集合(或者warp的集合)。但我在写CUDA的时候好像并没有看到warp的直接使用。注意grid与block两者的维度 gridDim以及blockDim 千万别搞混了。对于一个kernel:
1 | kernel_function <<<A, B>>> (); |
A指定的是grid的形状,可以是dim3类型,也可以是一个数字(指定block),A是数字的情形很常用,二维图像处理一般可以这么做:A,B分别代表图像的某一个维度。
B指定的是block形状,数据类型同理。那么gridDim则反映了A的输入,blockDim反映B的输入,比如:
1 | dim3 grid(3, 4, 5); |
在kernel内部,会有:
1 | (gridDim.x, gridDim.y, gridDim.z)=(3,4,5); |
相应地,blockIdx.x \(\in\) [0, gridDim.x ), threadIdx.x \(\in\) [0, blockDim.x)。每一个实际的id,其范围是层级式的。block id与grid有关,thread id与block有关。并且也要注意以下的问题:
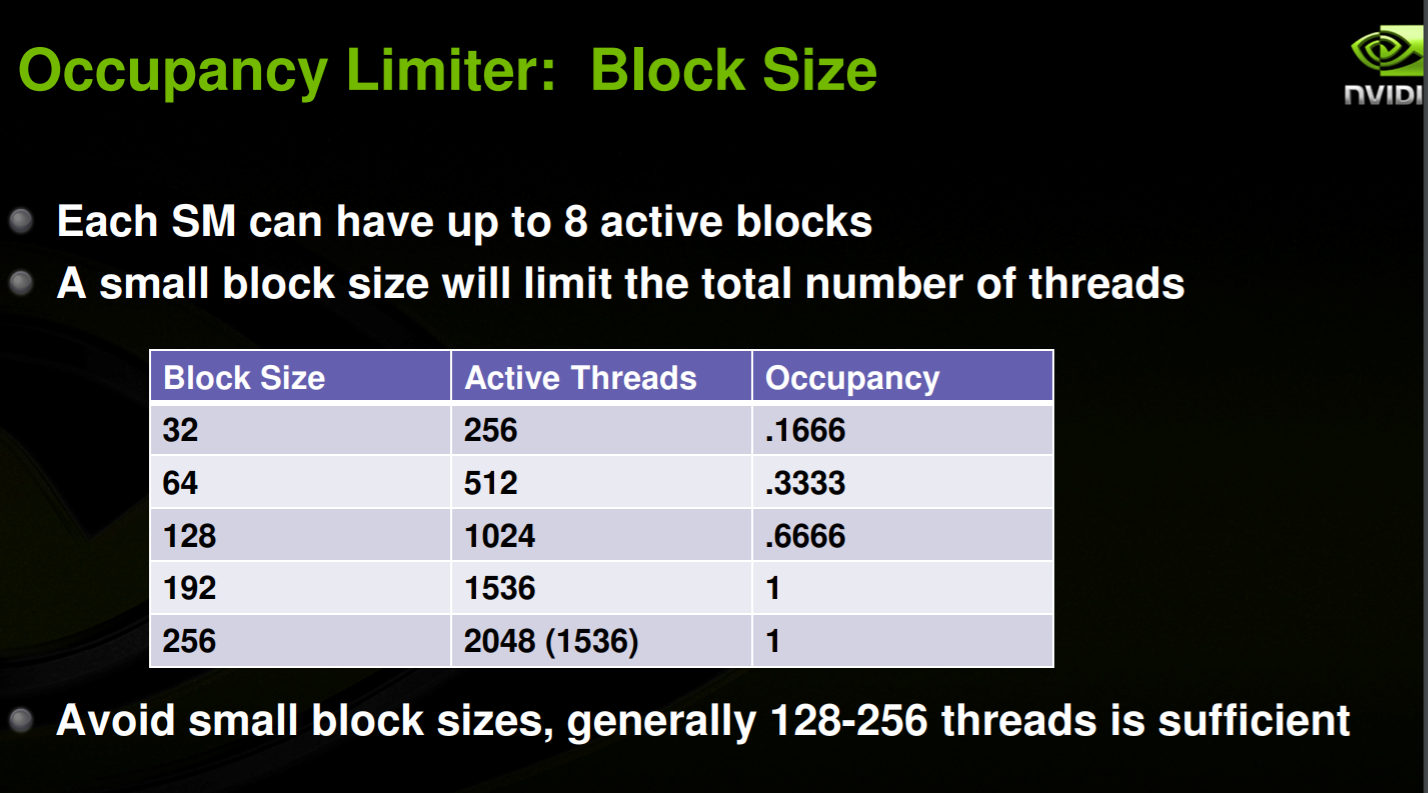
Goal: Have enough transactions in flight to saturate the memory bus.
Latency can be hidden by having more transactions in flight. [1]
2.2 Dynamic Parallelism踩坑
Dynamic parallelism,我更愿意直观地称之为:nested kernels(嵌套的核函数)。以我自己的代码为例,我尝试了一下嵌套核函数:
1 | __global__ void fineGrainedTask(const float* const bubbles, const int x, const int y, float* shared_tmp) { |
第二个函数 __global__ void calculateSDF
是主核函数。其目的是求二维矩阵中每一个点(i,
j)的SDF值。而显然,每次输入的泡泡数量(num)可以很大,那么内部求signed
distance的for循环,应该是可以并行化的。第一个函数__global__ void fineGrainedTask
就是为了做这样的并行,在第十行也被调用了(num路并行,使用__shared__保存临时的结果)。
CUDA在 architecture 35以及之后就支持这种nested的dynamic parallelism结构,允许核函数内部调用核函数,因为确实也是会有层次并行的需求的。
但是CUDA dynamic parallelism + Python却有一大堆坑
假如只是使用CUDA + CPP进行嵌套核函数的编写,虽然有点小坑,但是很快就能过编译:
Dynamic parallelism需要separate compilation,CMake里面有很简单的设置:
1 | set_property(CUDA_SEPARABLE_COMPILATION ON) |
但需要注意两点:
- separate compilation需要指定arch:
1 | -gencode=arch=compute_35,code=sm_35 |
- nvcc编译的时候,会指定:
-lcudadevrt -lcudart,在/usr的某个文件夹下有一个动态库(libcudart.so)以及一个静态库(我的设备上是静态库:cudadevrt.a)。不方便设置这两个编译flag的时候,在target_link_libraries中可以手动链接。
但是Python setuptools编译并没有那么友好。首先我也知道我需要进行separate compilation,所以我需要指定:
1 | setup( |
-rdc=true貌似和-dc作用差不多。还需要手动指定一下架构代数,默认好像是一个很小的代。好,不要忘了增加-lcudadevrt以及-lcudart以“保证”可以链接到CUDA的一些库。
看起来很简单,编它。编译通过,很好,跑它。首先import torch(由于本项目C++内部使用了libtorch,里面的libc10.so需要torch导入,不先import的话会报错)。再import march(我的库名称),这一步直接死掉:
什么什么undefined symbol,与CUDA库相关。
大概意思就是:cudadevrt.a你根本没有链接上,里面还有一些函数定义呢。好家伙,python的所有库都是动态加载的,你一个静态库你叫我怎么加载(简单的方法就是:(1)
重新编译静态库为动态库 (2)
编译整个项目为一个extension,具体原理我也不懂)?我还指望你直接给我编译到march这个库里面呢。
尝试了很多方法,无论是在C++ 编译flags里面链接,还是nvcc flags,还是stackoverflow上说的所谓:setup函数的extra_compile_objects参数,没有一个有效果的。
我也尝试过手动分别编译:
1 | nvcc -O3 -use_fast_math -gencode=arch=compute_70,code=sm_70 -dc -I/opt/libtorch/include/ -I/opt/libtorch/include/torch/csrc/api/include/ -I//usr/include/python3.6m src/sdf_kernel.cu src/marchingCubes.cu -Xcompiler -fPIC |
想把两个cuda文件编译跟原有的静态动态库一起编译成一个动态库,但是中途报了有关fPIC的错误,说是这样编译是不被允许的,反正不是那种很简单的错误。。。搞了半天,无果。各种问题都出了,最后我甚至都怀疑是编译器的bug(自信!)。最后貌似在CUDA forum的某个地方看见有人说,Python现在对这个的支持还不是特别好,就弃坑了。
最后一个小坑就是:tmd不要随便用很高的代数!不知道为什么,我在setup函数nvcc参数设置时,定代数为:-gencode=arch=compute_70,code=sm_70。结果跑结果的时候,输出图像一片漆黑。最后查出来结果是:核函数根本没有被执行,跳过了,开始我以为出了内存问题(老
千(次)越(界)了)(PS:CUDA
runtime出错可能导致核函数不执行),写了个CUDA错误检查,发现完全没有错误。最后灵光一闪,我把代数改成了35,好了。。。
感觉被坑死了。原本预计一个下午解决,结果因为grid/block搞混,结果错误,多调了3小时,又因为dynamic parallelism,多调了6小时。
菜,或许就是这样的吧?
完整的项目以及结果见[🔗Enigmatisms/CuTorch]
Reference