CUDA踩坑实录【2】
CUDA II
I. Introduction
CUDA十分有趣。因为我基本就是做算法和软件的,所以对于计算机体系结构,硬件设计等等了解得不多。尽管个人这方面知识有限,我仍然觉得这方面知识十分必要。Profiler能帮助我们在数据驱动的形式下优化代码,但并不会有助于我一开始就写出高质量、符合相应设备特性的代码。而深入了解CUDA对理解计算机内部一些底层的实现非常有帮助,比如说:内存访问,存储结构,流水线设计,带宽利用... 等等。
为了进一步精进CUDA技术,我又设计了一个新的项目:粒子滤波加速。本来是想给之前的【Particle Filter Simulation】这篇博文中使用的Volume2D算法进行加速,但做着做着就发现该算法不适合加速,遂推倒重来,重构的过程中学习了很多新的知识。整个项目作为 激光雷达仿真器LiDARSim2D的一个补充模块,现在更新在了[仿真器repo:LiDARSim2D]下。
II. PF-GPU管线
2.1 之前的算法
之前的粒子滤波基于Volume2D算法,主要问题有两个:
不是说Volume2D算法慢,Volume2D算法虽然是性能瓶颈,但是单次也能只花0.2ms就算出结果来。而问题是,粒子滤波需要计算成千上万次,0.2ms在2000粒子的情况下,经过8线程加速,也就大概6fps的样子,远远达不到实时性要求。
前一版算法,只对2D(x,y)进行了定位,这存在两个问题:
- 旋转这个维度,虽然相对平移来说只有一维,但是其对结果的影响一般来说都更大。(旋转导致视角变化,视角变化导致观测可以发生巨大改变)。此外,不做角度维度的滤波使得这个粒子滤波直接失去了当2D建图中的一个附加算法模块的可能。
- 为了保证采样充分,三个维度比两个维度需要更多的采样点(比如之前如果是1600=40*40,那么直觉上来说,三维应该需要40*40*40=64000),这就引回到第一个“计算慢”的问题上了(20000点,0.6fps)。
两个问题都是无法接受的!!!!不过!解决这两个问题的关键,是解决速度问题。速度上去了,那么可以接受更多点的采样,也就能解决维度问题。于是我开始思考如何加速Volume2D计算,Volume2D见[我的博文]。其中最有并行加速希望的地方在这:
长代码段
1 | void ParticleFilter::edgeIntersect(const Edge& eg, const Eigen::Vector2d& obs, std::vector<double>& range) { |
但是实际缺很难做,一是因为此处求交点是针对一段折线,需要先旋转数组二分查找。此外,Edge这个数据结构也不方便使用(变长Eigen::Vector2d的deque),还逼得我了解了一下thrust的libcu++ vector。遂放弃加速。
2.2 渲染管线
突然有一天上午,我觉得自己之前很蠢:之前的粒子滤波是写着玩的,要不然求range image的方法也不会是这样(当时因为受Volume2D的启发,想要复用一下这个算法)。事实证明,这个算法不适合求深度图。想到这个,我直接开始思考用激光雷达模型
我称之为:正向法,也即求激光雷达发射光线生成深度图的模型。
深度图获取,在我看来就是一条GPU渲染管线(渲染经常做这个事情啊),而且我觉得本问题用GPU实现实在太适合了,原因有二:
- 每个粒子根据此时的位姿求深度图,进而求重采样权重,是完全相互独立的。
- 每个粒子内部,渲染深度图使用Z buffer方法,应该是有很不错的并行度的。
于是我直接设计了一个Z buffer方法:
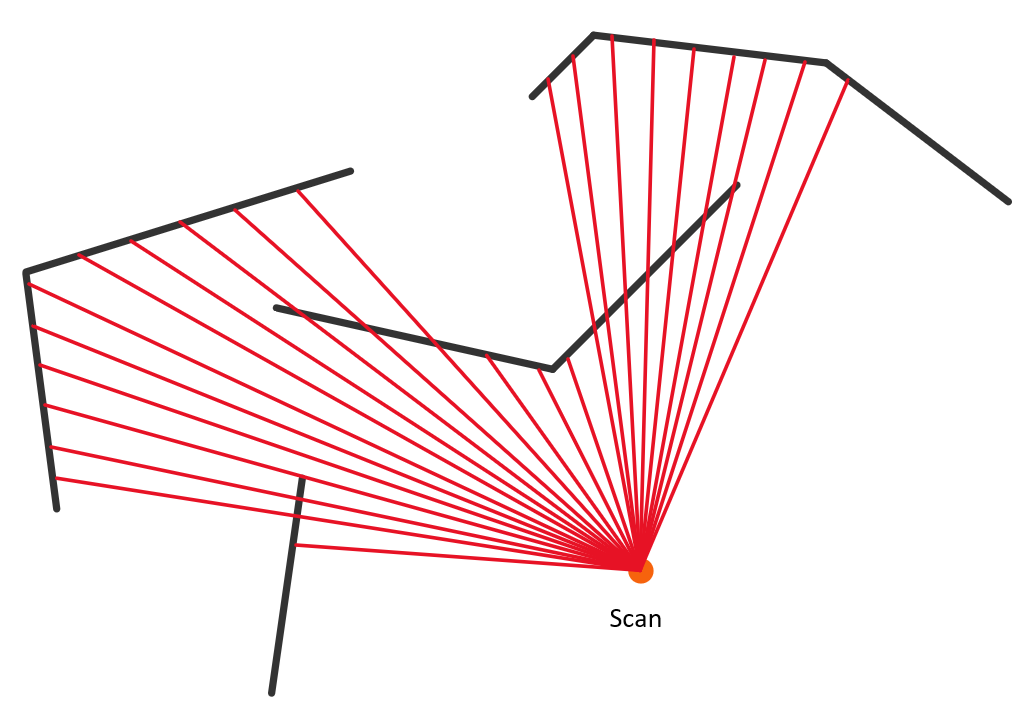
Z buffer 很好理解,它与Volume2D的异同是:
计算哪些地图边界能被实际观测到(计算遮挡关系,求出没被遮挡的所有边),使用未被遮挡的边计算激光交点以及对应深度。
不管遮挡关系,激光与所有可能边相交,取离自己最近的那个值(最小值)。也就是说,Z buffer直接计算所有可能的相交,求最小值。
III. 算法设计
3.1 第一代
数据关联越不紧密的,并行的粒度应该越粗。--- 我的理解
这么说的原因是:数据关联紧密的,可能可以使用共享内存。比如本问题中,不同粒子之间,经过背面剔除(back culling)之后的边都不一致,并且观测点也不一致,不适合放在同一个block内部,故一个粒子应该是一个block。而block内部细粒度的并行,应该针对【一个确定粒子下(观测点确定)】的所有地图边(地图两个相连角点确定的线段)(见下图说明:)
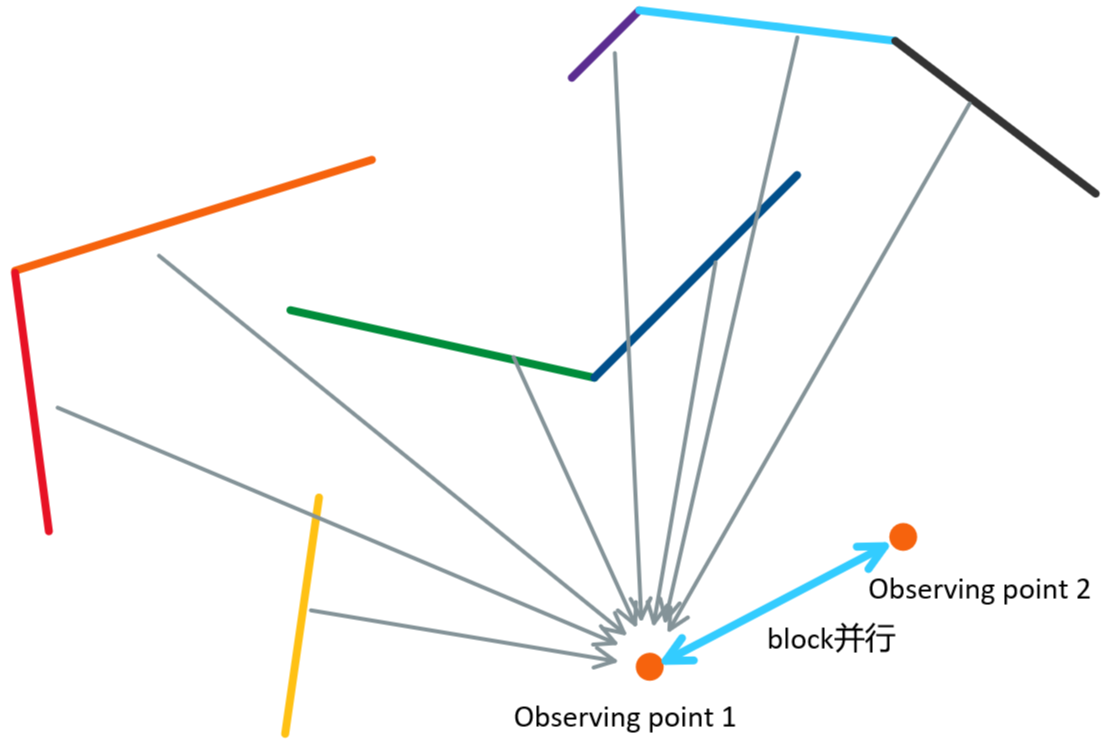
不同的观测点位于不同block,同一观测点下的不同线段(比如observing point 1下的地图线段),线段之间是thread并行的(不同颜色线段产生的深度信息是并行计算的)。使用线段而不是Edge作为处理单元以及这样设置并行带来几个好处:
- 线段是定长的数据(4个float就可以表示)
- 不同block可以在常量内存中共用同一个地图(初始线段)
- 同一个block内处理不同线段的thread,可以将back culling的结果输出到一个共享的flag数组上,并且计算的深度值也可以使用共享内存保存,加速内存读写。
于是初代算法的流程大概是这样:
- 观测点数为girdDim.x(也即block数)(10000+),线段数量为blockDim.x(也即线程数)(通常小于400).

由于第一代算法几乎就是整个算法的思想主体(之后的都是优化迭代,没有大改),重点说一下。
3.1.1 背面剔除
背面剔除需要flags:输入的是原始地图,原始地图中有些线段是不需要的(背面),在背面剔除函数中每个线程计算自己对应的线段是否是正面,保存在flag中。以下代码块是动态内存分配,平均每个block使用1-2KB的共享内存(很节约)。由于CUDA动态共享内存 只有这一种方法分配,所以跨类型或者多数组是不可能直接写的,需要强转指针(我哥建议我使用reinterpret_cast来完成指针转换,但是我发现这样也没问题)。注意由于分配的是int数组,故在kernel launch时,指定的数组字节数需要为4的整数倍(bool只占1字节,所以可能需要padding)。
1 | extern __shared__ int range[]; //...一个数据类型分为了两个不同意义以及类型的块 |
3.1.2 单线段Z buffer*
假设本thread的id对应的线段需要被处理(事实上如果不需要被处理,会直接return,这确实会引起warp divergence,但是overhead可以忽略),那么就需要计算这个线段产生的局部深度图。
其中的难点在于控制逻辑:-PI~PI是atan2的角度输出范围,角度奇异性(由于是逆时针,一般情况下起始点角度小于终止点,但是跨\(\pm\pi\)界限(x负半轴)时会出现奇异)会影响数组下标 / 角度id等等的计算,这里不多讲,有兴趣直接看代码吧。
此外重要的一点就是:Z buffer保存的始终是某个角度上深度的最小值,但是如何计算最小?需要我们把所有线段深度算出来然后求最小?显然不是,这样太慢了,而且需要线程间数据交流(共享内存)。我们考虑增量式的方法:
计算值每次和深度值数组range(共享内存)对应id进行比较,保留更小的值。但是这会涉及到一个问题:线程访问冲突。
使用原子操作!原子地进行比较并且替换为更小值就行。但是很可惜:CUDA不支持float原子比较。
那么怎么办呢?stackoverflow上有人给了方法:
把Float直接按位解释为int,对此int进行一些计算,转化为一个可以保序的(ordered)int,对int进行原子比较可以使用atomicMin。
关于Ordered int转换,见这篇别人写的博客[Float radix sort], 以及stackoverflow上的[一个回答](最高赞的是错的,Informate.it写的是对的)。原子操作十分香,而且感觉很优雅。
3.1.3 相似度权重
所有线程计算结束之后(相当于本粒子对应观测点的深度图算完了),一个block内计算参考深度图与本观测点深度图的L1误差\(L_e\),\(1/(L_e+1)\)是本观测点的权重。
3.2 之后的优化
第一代算法存在一些速度缺陷:
- 使用double,进行计算:CUDA对double并不是特别友好,一些double函数比如atan2就更不用说了。int也是滥用了,有些数字使用short即可,完全不必用int。
- Z
buffer中的线段求交点函数
__device__ __forceinline__ float getRange(...)内部过多Eigen或者自定义数据结构的重复索引操作,并且有些计算没有复用。这个函数是整个单线段Z buffer的瓶颈。 - 使用Eigen,库虽然方便,但是速度慢了
- (重要):并行度低,没有使用流水线(stream),单kernel,GPU占用巨大。
第一个问题优化之后,使得我的算法从与CPU差不多的速度升到的CPU的五倍(相比于8线程),第二三个问题修正使得我的速度上升为CPU速度的16倍(相比于8线程),而profile以及流水线优化使得我的算法先后达到了32x,45x加速!所以我重点说一下stream concurrency。
3.3 Stream Concurrency
stream,翻译是“流”,我将其理解成为流水线。实际上是GPU的一个操作“队列”:
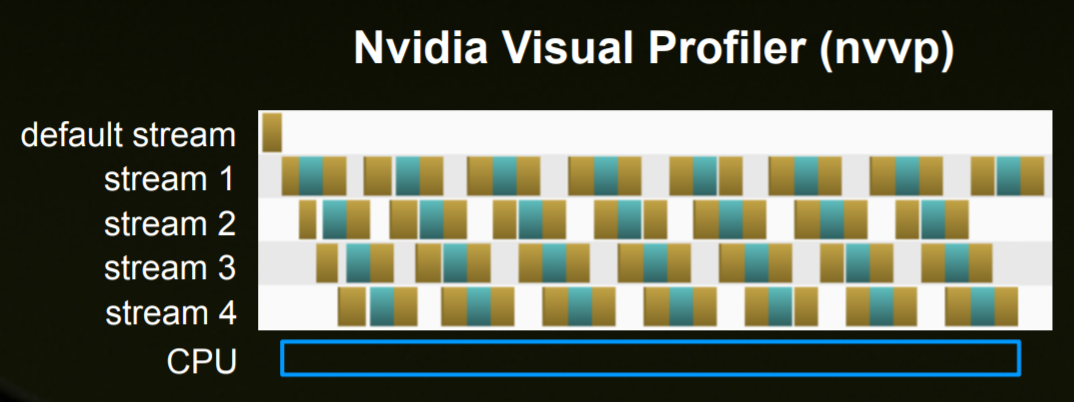
stream有这样的特性:
- 如果一个kernel或者是cuda操作(比如Memcpy)在同一个stream下被launch,那么是按照issue-order(发射的顺序)执行(与之相对的是乱序发射)。
- 如果分配到不同的stream下,那么可以乱序执行,并且根据GPU资源利用情况,可能有overlap。
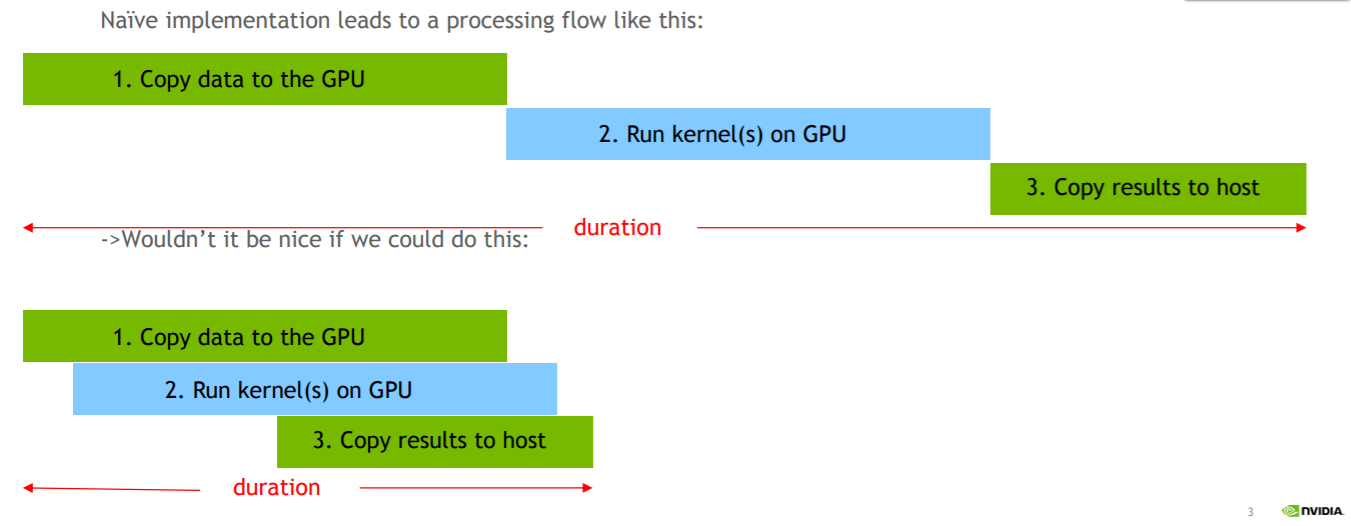
那么显然,overlap多大,说明GPU越不容易空闲,很可能可以有几个kernel函数的并行执行,相当于流水线操作,上一个kernel还没执行完,下一个kernel已经开始了。如果不指定stream,使用default stream,那么profile得到的图会是一个完全阶梯状的,阶梯之间一般没有并行(issue-order限制),一开始我就是单stream执行的,并且是一个超大的kernel(需要处理上万个block)。
当我意识到这一点之后,我将kernel拆分了,反复调用particle filter这个核函数,不过每次只处理不到100个block。开始时跑的效果并不好,直到我使用了CUDA Profiler,将运行状态绘制出来之后发现,诶?完全阶梯状的kernel调用,并且profiler也告诉我:“kernel overlap too small: 0%”,也就是说,block几乎是顺序计算的,这样的效率太低!
查阅了很多资料[1][2][3],最后确定使用stream:
1 | cudaStream_t streams[8]; |
创建了不同的stream(cudaStreamNonBlocking),循环地把不同的kernel(处理particles的不同offset位置)发射到不同的stream上,实现更加紧凑的并行。cudaStreamDefault 在CUDA7之后不会有之前的隐式同步问题(默认stream会导致操作串行化),所以可以使用。
当然,流水线最后的级数,block的大小都是profile试着调整过来的。32x加速的版本,使用的grid有点过小(4个粒子,8个streams):
- 4个粒子的kernel会迅速执行完,但是kernel时间并没有长到可以充分利用流水线调度空余时间。
- 最后使用16个粒子的kernel,速度提到了45x(profile之后突然想到的)
3.4 一些其他的加速尝试
以下是证明在本问题中无效的加速尝试:
- 动态并行(dynamic parallelism,这也是在上一篇CUDA博客中折磨我的东西)。这个完全没用!反倒是增大了每个kernel的线程资源消耗(一个block就只有最多1024线程),导致算法变得更慢。很显然嘛,一个block大概200-300个线程,那么每个线程还得再launch一个子kernel(多线程),显然资源会不够。
- 内存吞吐流水操作:CUDA希望我做这个事情:内存的移动是小块小块的,不要一起完成,否则没有太大的流水线加速效果。但实际情况是:即使是个几百MB的global memory复制,也非常迅速地完成了(貌似没到1ms)
- 更加激进的位宽优化(能换short就short了),剩余的一些优化用处不大。
- 等等等等:尝试了很多方法,不一一列举了。
3.5 采样点不足
旋转对算法结果的影响能力比平移大。试想一下自己平移一些之后看到的世界与旋转一点看到的世界的差异就知道了。开始时,角度的采样明显是欠缺的:
- 三个轴上都使用均匀分布随机数。因为开始时我希望保证三个维度下的采样应该一致,但这种做法并不好,因为我 并不能保证,在每一个平移位置,旋转的采样都足够了。
之后我使用了如下的策略:12800个点,先在平移上均匀采样1280个点,每个平移位置:360度等间隔采样(10个点,36度一个),那么一个平移位置对应了10个点,再对这10个点加少量位置噪声。这种策略,可以保证每个平移位置的角度采样都是充分的,就不会因为角度采样过于随机导致视角缺失。
3.6 一些坑
- Eigen/CUDA不兼容的坑:在同学的RTX 2070设备上测试时,他的驱动是CUDA
10.2,Eigen 3.3.4,我的驱动CUDA
10.1,Eigen相同,我可以编译,他报错:找不到
Eigen 找不到<math_functions.hpp>:把Eigen升级到3.4.0 (直接上Gitlab爬下它的源码进行include),正确选择arch代数(RTX 2070至少应该选arch=sm_70? 我的MX150是sm_61)就可以通过编译。 - std::atomic库与CUDA不兼容:我想把之前写的键盘操作用在CUDA可视化中,但是编译不过,CUDA中的std::atomic部分类型的copy constructor是deleted functions,没有实际意义。最后没有解决,放弃了,直接使用OpenCV。
- nvcc要加一些flags才能避免Eigen的一些傻逼warning:
--expt-relaxed-constexpr -Xcudafe --diag_suppress=esa_on_defaulted_function_ignored,CMake添加这个:add_compile_options(-Wno-deprecated-declarations) - __constant__ memory访问的问题:定义__constant__ 变量,是不能用extern的,并且constant内存是已经存在的,只需要声明用多少(不能malloc),只要能看到这个变量的定义,那么这个变量对能看到它的函数都是全局的。在不同文件中使用同一个constant memory变量,需要:打开CUDA的separate compilation选项(目的是生成一个relocatable的代码),separate compilation在之前的动态并行中说过。
- 一些结构体定义的函数如果需要在GPU上用,要声明为__host__ __device__ (双重属性),这样的话,CPU / GPU上会各有一份实现。
- 带cuda开头的cuda runtime API一般都是host only,不要使用在kernel中。
- 使用nvvp进行可视化profiling,需要安装java8,配置jre-1.8(针对Ubuntu18.04),环境错了是打不开profile工具的。并且profile的时候需要有root权限。
- 粒子的运动:每个粒子应该朝自己的方向前进后退左移右移,而不是与控制点保持一样的方向。方向一致的运动结果是有问题的。
IV. 实验结果
4.1 粒子滤波效果一览
6fps慢速播放效果:
4.2 Profile结果
小block的kernel方便进行kernel之间的并发,而大block的kernel就可以明显看出执行偏顺序化了。
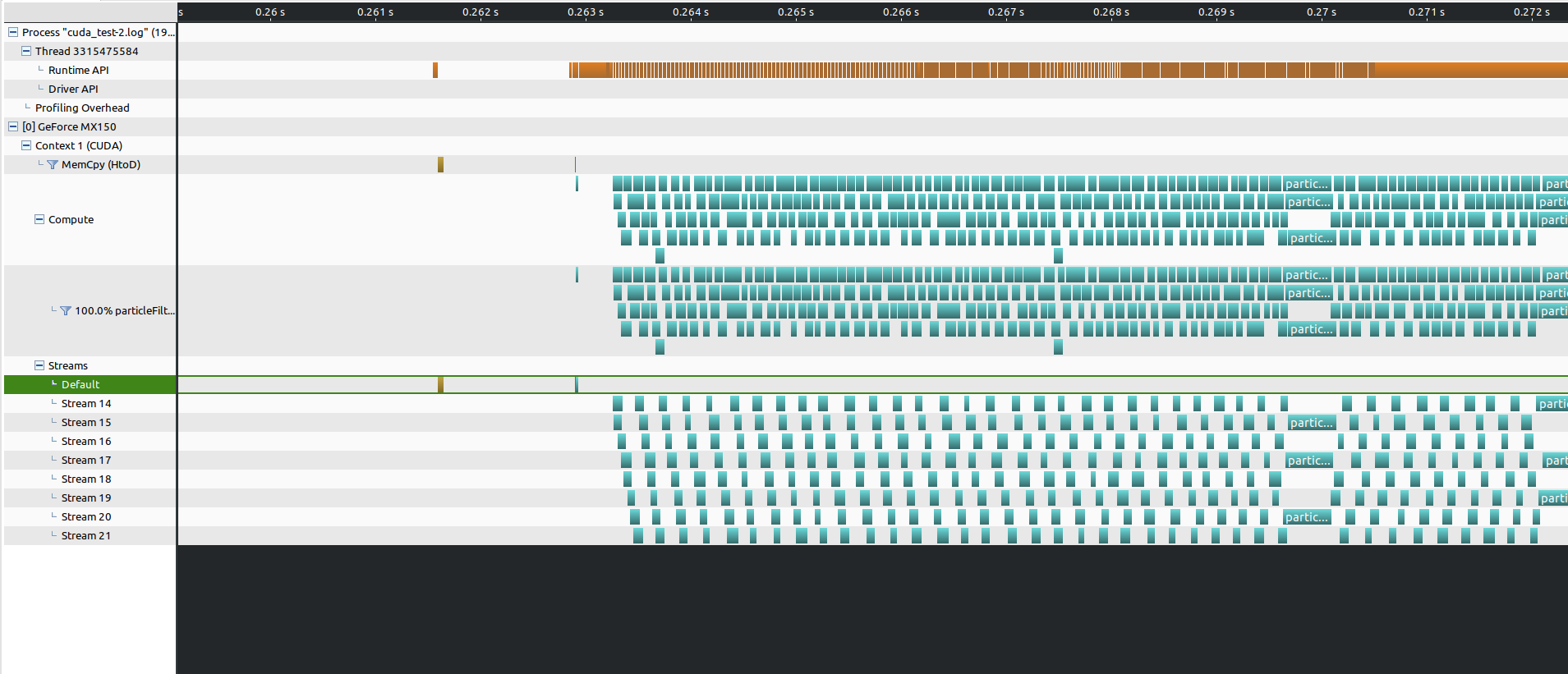
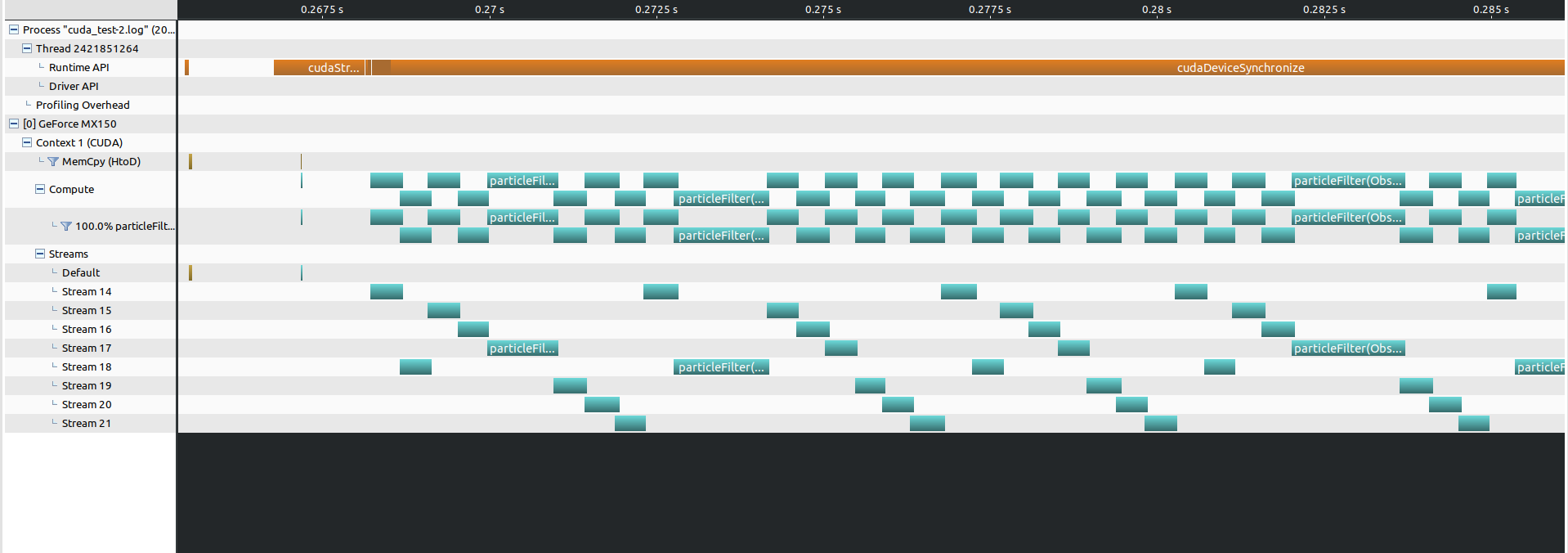
极端情况是单stream大block,由于资源占用过多,kernel之间完全是串行执行了。
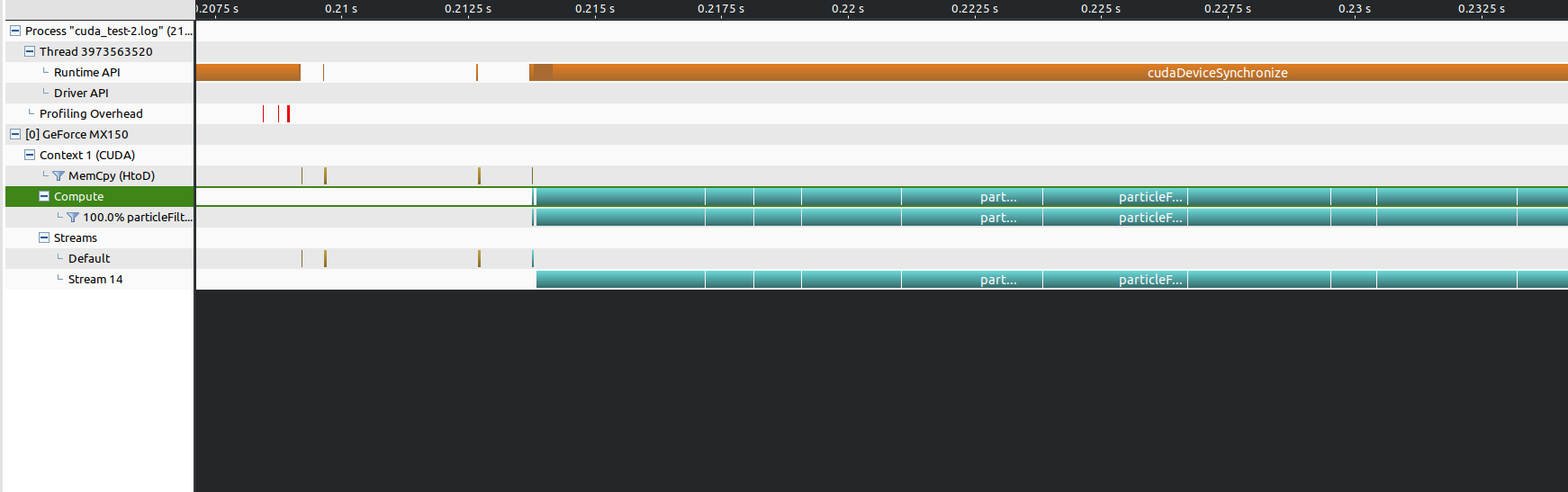
4.3 速度说明
已经测试的速度(12800粒子,$$115度激光,角分辨率0.5度,共330个激光点的情况):
- GeForce MX150: 约为42fps
- GeForce RTX 2070: 约为116.5fps
4.4 四张图
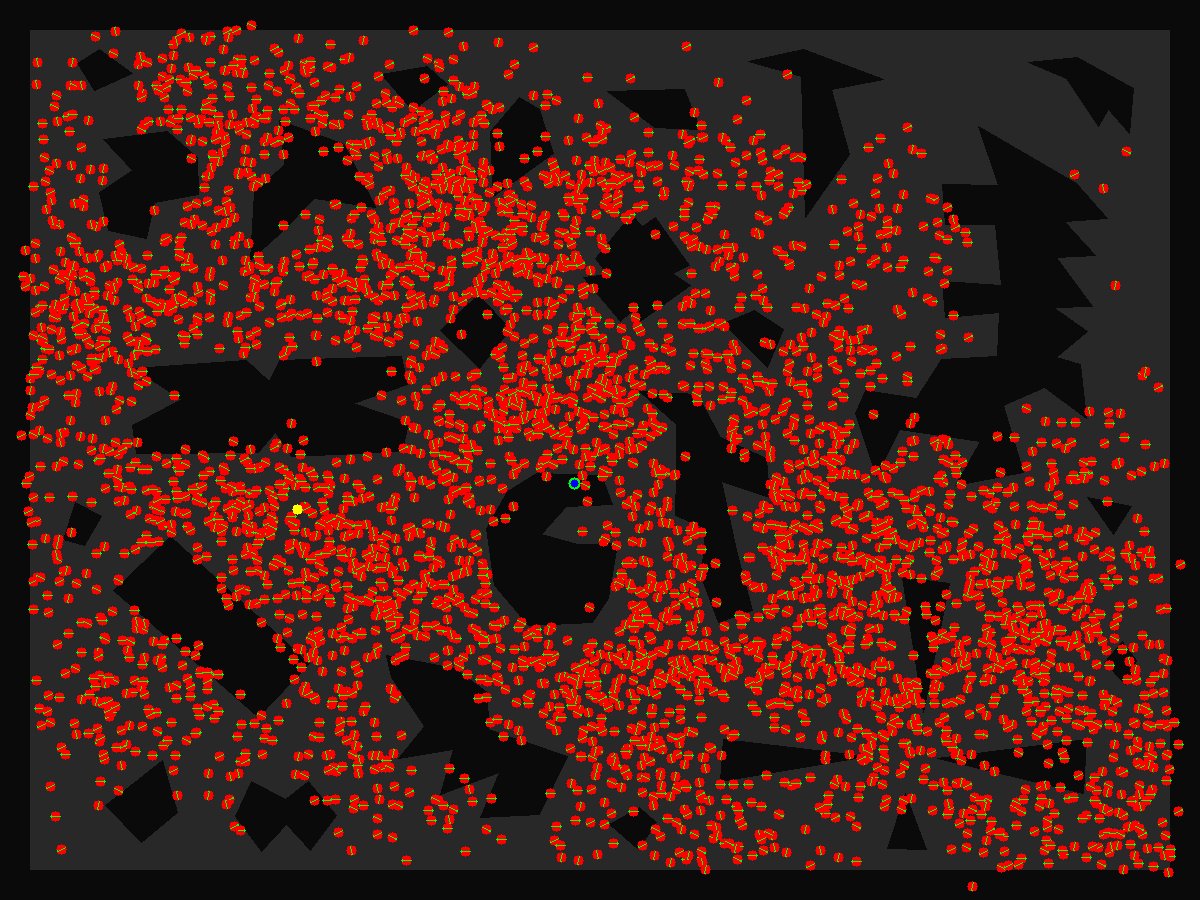
红色粒子为采样,红色粒子内部有黄色箭头(很小),指示了粒子的方向。蓝绿色点是所有粒子按照权重加权平均的结果(带权重心),黄色点是真值。
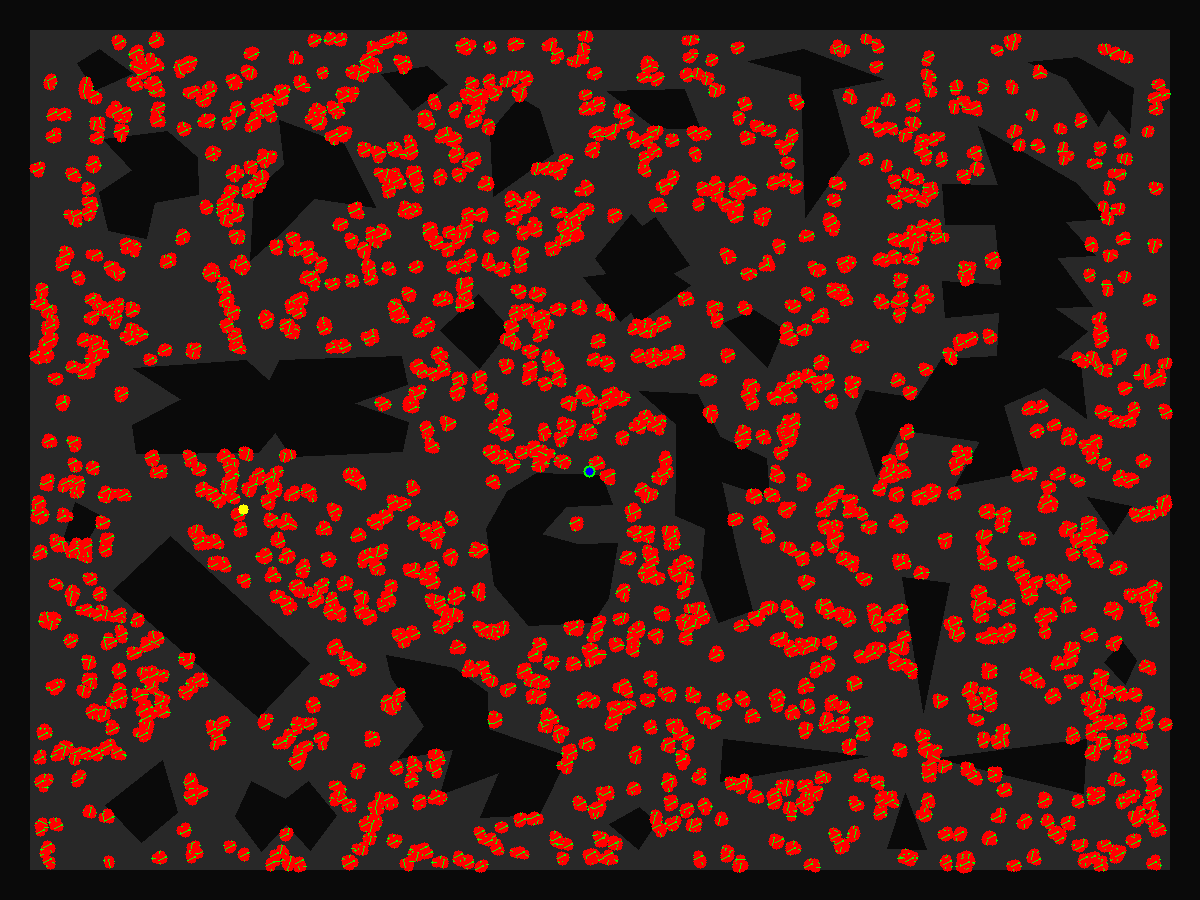 |
|
|---|---|
| 开始阶段:粒子簇在平移均匀分布(略带噪声) | 移动一段距离,每个粒子都更新了自己的位置 |
 |
 |
| 收敛中:粒子均值已经收敛到真值附近 | 收敛,有偏差,这是初值估计可以容忍的 |
Reference
[1] Steve Rennich - CUDA C/C++ Streams and Concurrency
[2] Nvidia Bob Crovella CUDA Concurrency
[3] Justin Luitjens - CUDA streams best practices common pitfalls