Vision Transformers
ViT
I. Intros
去年的一个工作[1],Vision Transformer的成功带动了变形金刚在视觉邻域的应用。CNN-based的backbone可能就快败在NAS以及ViT衍生模型手下了。为了回顾transformer以及加深理解,我复现了这篇论文[2](其中的ViT-Lite以及CCT)。这个工作是对ViT进行轻型化,并且作者也提出了使用卷积加入inductive bias的方法。论文提出的网络复现起来很简单,毕竟不是什么大型网络以及复杂架构,但是要复现其结果感觉还是挺吃经验的。复现见:[Github🔗:Enigmatisms/Maevit]
 |
 |
|---|---|
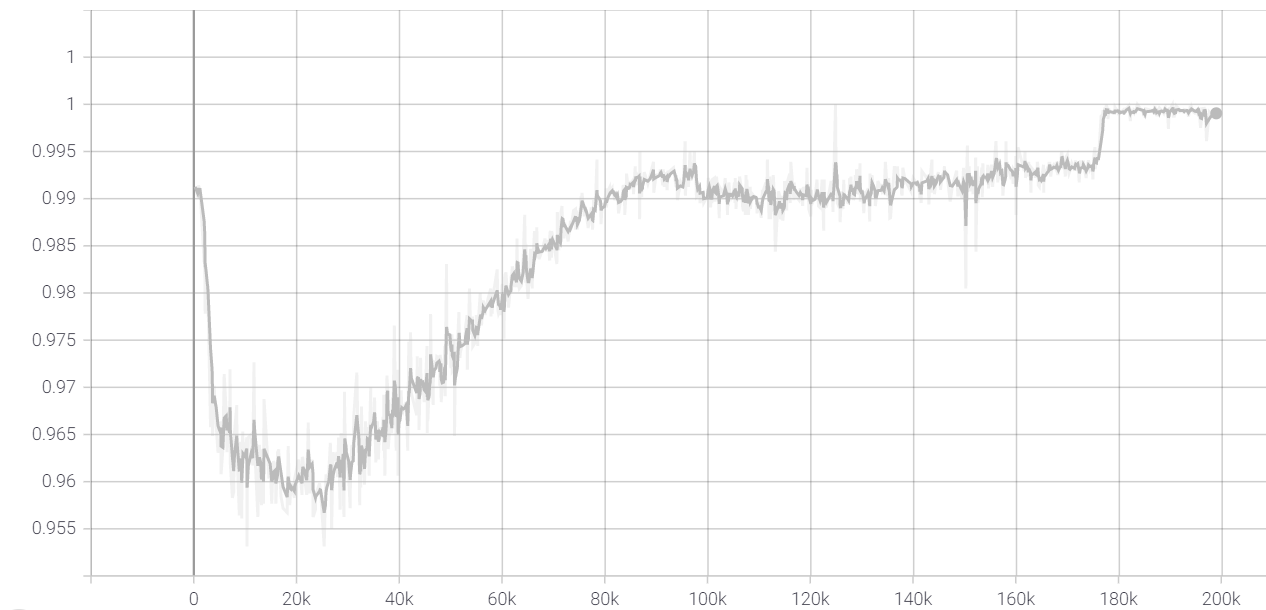
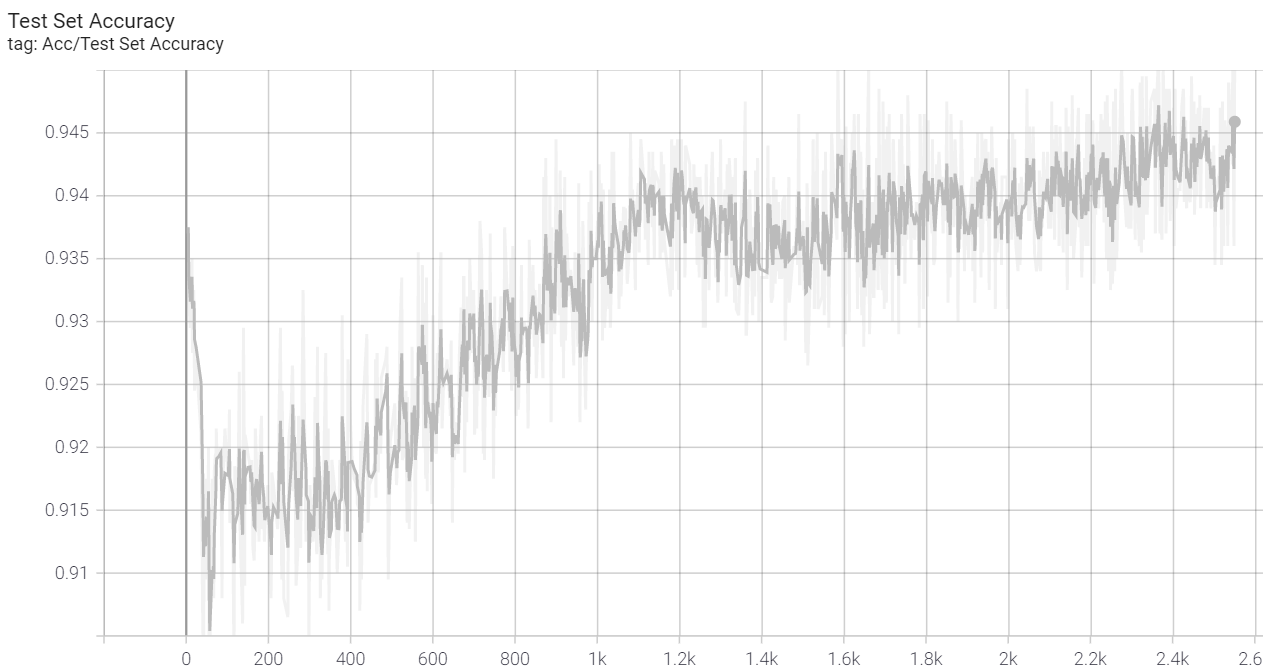
| 最终(无mixup)训练集准确率(约99.8%) | 最终(无mixup)测试集准确率(约94.5%) |
II. A Few Points
2.1 Inductive Bias
按照Wikipedia的定义,归纳偏置其实就是 为了处理没有见过的数据而在学习器上做的假设。
The inductive bias (also known as learning bias) of a learning algorithm is the set of assumptions that the learner uses to predict outputs of given inputs that it has not encountered.
维基以奥卡姆剃刀原理作为了其中一个例子。事实上,奥卡姆剃刀原理这种归纳偏置实际上是 权重正则化的底层思想:模型不应该过于复杂。
A classical example of an inductive bias is Occam's razor, assuming that the simplest consistent hypothesis about the target function is actually the best. Here consistent means that the hypothesis of the learner yields correct outputs for all of the examples that have been given to the algorithm.
ViT论文中提到:
We note that Vision Transformer has much less image-specific inductive bias than CNNs. In CNNs, locality, two-dimensional neighborhood structure, and translation equivariance are baked into each layer throughout the whole model.
此处所说的inductive bias实际上是卷积神经网络的特性。由于卷积核每次操作都是针对某个位置领域的像素(或特征)进行运算,卷积操作也就包含了一个这样的假设:一个像素(特征)的信息一般与其周围的像素(特征)存在一定的关联性(当然,如果你非要对每个图像位置,取出其周围的像素,过MLP,然后说MLP也有这样的inductive bias,那我也没办法)。
相比之下,Transformer看什么都具有全局眼光。Transformer 这种从NLP过来的结构,本来用于处理语句token的embeddings,语言这种东西就会存在长距离的关联关系,如果要使用卷积(比如一维卷积),可能层数得非常深才能使感受野足够大。于是,卷积层的领域信息综合这种inductive bias在transformers中是找不到的。所以说,ViT-Lite的作者希望自己能把更多传统CNN模型的inductive bias融合到ViT模型中(毕竟patch化以及插值是唯二利用率空间邻域信息的操作)实际上做的工作非常浅层:
- 我在输入Transformer前,让生成embeddings的网络具有卷积层不就行了吗?看起来像小打小闹。
2.2 两篇论文的思想
论文思想其实并没有什么好说的,就是Transformer模型在视觉中的应用:
值得一提的是,原论文名字叫做:An Image is Worth 16X16 Words....。可以从中看出其“patchify”过程,实际上是固定patch个数的。这使得ViT不适用于不同的数据集:
- CIFAR10大小只有32 * 32,那么一个patch只有四个像素,能有多少信息?不会要我上采样吧
- MNIST更不用说了
- ImageNet?真是谁有钱谁work啊,不是人人都能训的动image net这种贵物的。我们将这种人称之为:卡怪。ViT是一个大模型,参数很多(ViT-base效果不太可,ViT-胡歌效果才SOTA,但是胡歌(huge)版参数已经超ResNet-1001了,我没理解错的话,ResNet-1001是个千层面网络)。
- CCT就相对轻型很多了,而且可以适用于小数据集。我自己做实验使用的就是CIFAR-10。
III. 训练tricks
3.1 写在前面
我自己本身很反感调参。在我看来,人工智能训练师就是初中毕业就能干的活,但不管怎么样,打不过的时候,该加入还是要加入,至少了解使自己恶心的事物到底恶心在哪,才有机会去改变吧。由于之前一直被设备以及这种恶心感限制,一直没怎么了解训练tricks,这次花了一点时间稍微涉及了一点点。
人工智能训练师和驯兽师没有区别,训练的客体都是能力未知的对象,训练主体都不需要特别高的智力。乐观地说,人类还是有机会理解自己的创造的,但调参怪没有这个机会。悲观地说,你猜世界上有多少炼丹师是调参怪?
3.2 AdamW
之前在自建网络解决一个二分类问题时,遇到了很严重的过拟合。当时Google到的其中一种方案是:使用weight-decay,在优化器里直接设置即可。Weight decay 实际上就是 L2正则化(in SGD),很简单: \[ \begin{align} &L_{\text{final}}=L+L_{\text{L2 Reg}}=L+\alpha\sum_{i=1}^nw_i^2\\ &\frac {d L_{\text{final}}}{dw_i}=\text{grad}+2\alpha w_i\\ &w_{t+1,i}=w_{t,i}-\text{lr}\times (\text{grad}+2\alpha w_i) \end{align} \] 也就是说,每一次更新,权重都会根据上一次的权重进行一定的衰减。
至少,weight decay = L2 regularization在 SGD中成立。在一些复杂的优化器,又有momentum又有平均的的(比如Adam),weight decay实际上和L2 regularization是不一样的。
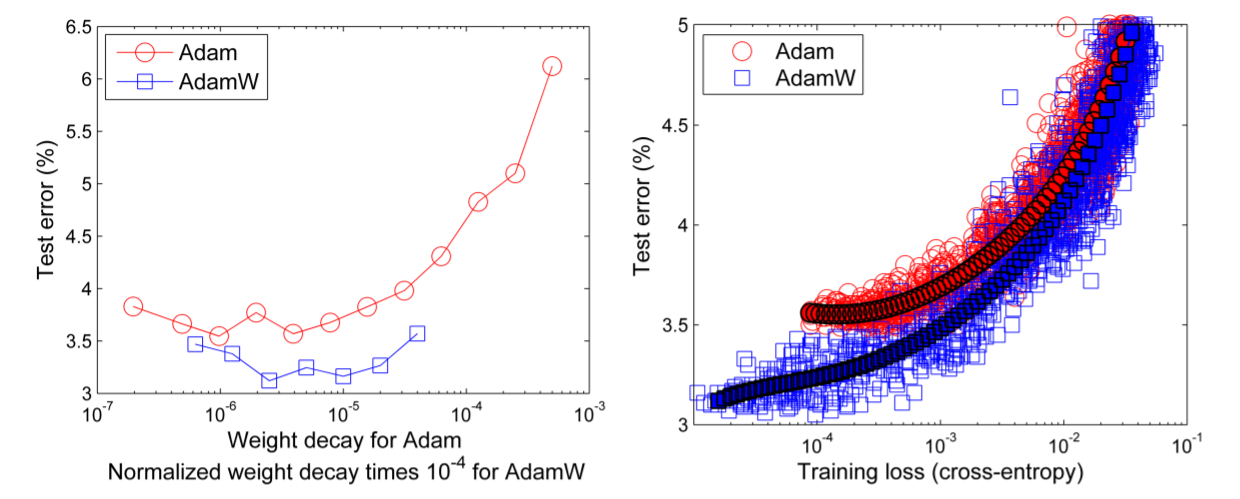
We note that common implementations of adaptive gradient algorithms, such as Adam, limit the potential benefit of weight decay regularization, because the weights do not decay multiplicatively (as would be expected for standard weight decay) but by an additive constant factor. [4]
这个优化器在之前的某个二分类任务中我已经用过了。关于AdamW的更多信息,可以查看[5]
3.3 CosineAnnealingWarmRestarts
Torch自带的cosineLR好像并不是我想要的样子,因为lr_scheduler.CosineAnnealingWarmRestarts出来的是这样的结果(下图绿色):
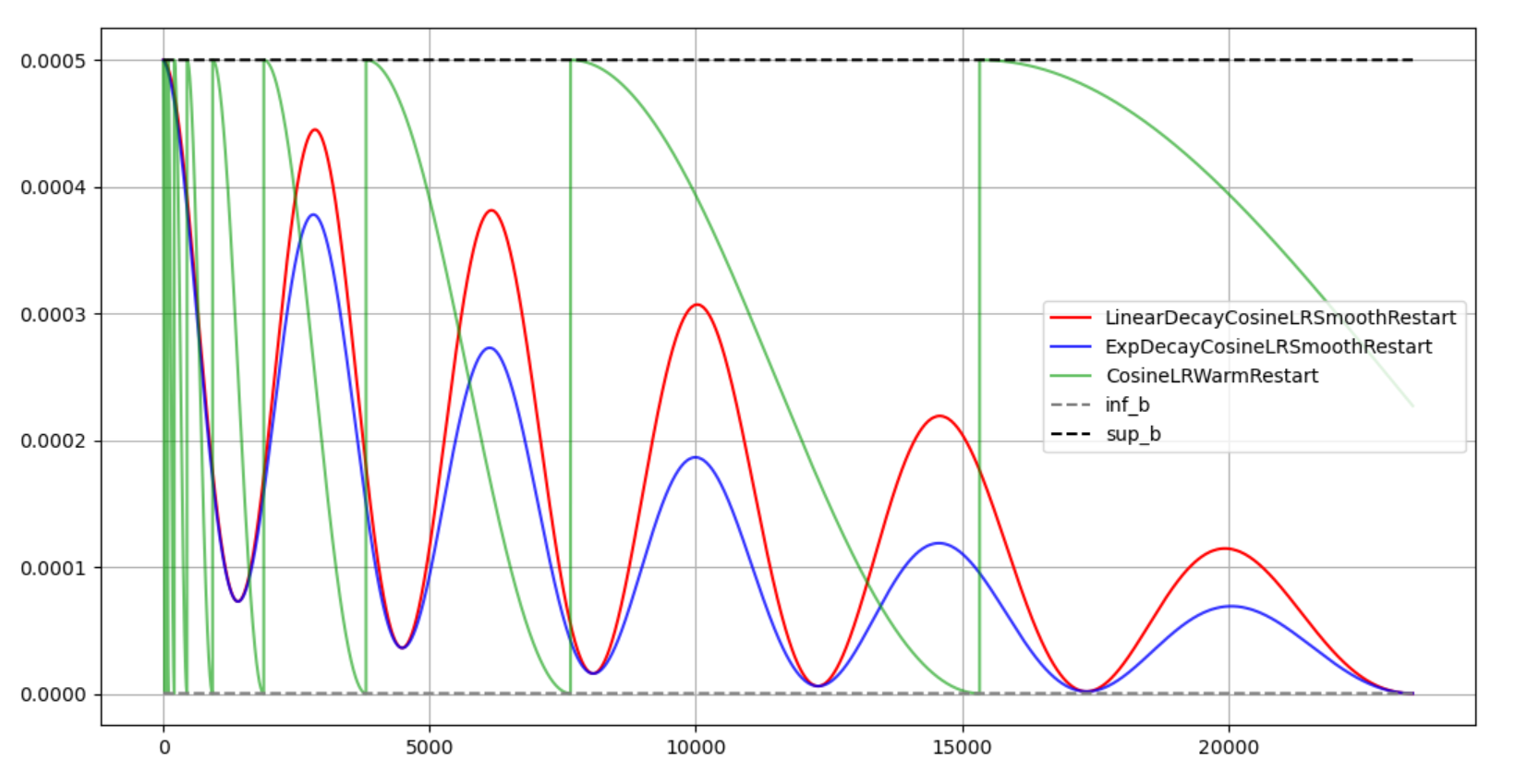
绿色的曲线其学习率是一直在回跳到最大初始学习率,这好吗?我没有在API里找到任何关于学习率变小的设置。并且,这个学习率设置还有个这样的问题:如果设置T_mult(也就是让restart频率越来越低,cosine周期越来越长的一个因子),很难控制其在一定epochs后,学习率降到最低(一般来说,最好降到最低才是最好的)。
所以我用LambdaLR设计了一个余弦学习率曲线,波动是为了其有一定的退火能力,而我同时希望:
- 学习率不断减小
- 波动频率不断减小,并且在指定的epoch减到最小
我将这个学习率称为(xxx-Decay-Cosine-Annealing-Warm-Restart),xxx可以是线性,也可以是指数。思想很简单,学习率曲线被两条曲线夹住(不是渐近线,渐近线很难求,但是可以按照渐近线理解)。一条确定学习率最大值(可以是线性衰减或者指数衰减),另一条确定学习率下界(指数衰减),可以根据初值、终值以及epochs计算所有参数。详情见:(LECosineAnnealing.py)
Timm (Pytorch Image Models)是个好东西,里面提供了可以衰减的CosineAnnealingWarmRestarts:
1 | from timm.scheduler import CosineLRScheduler |
学习率曲线是这样的:
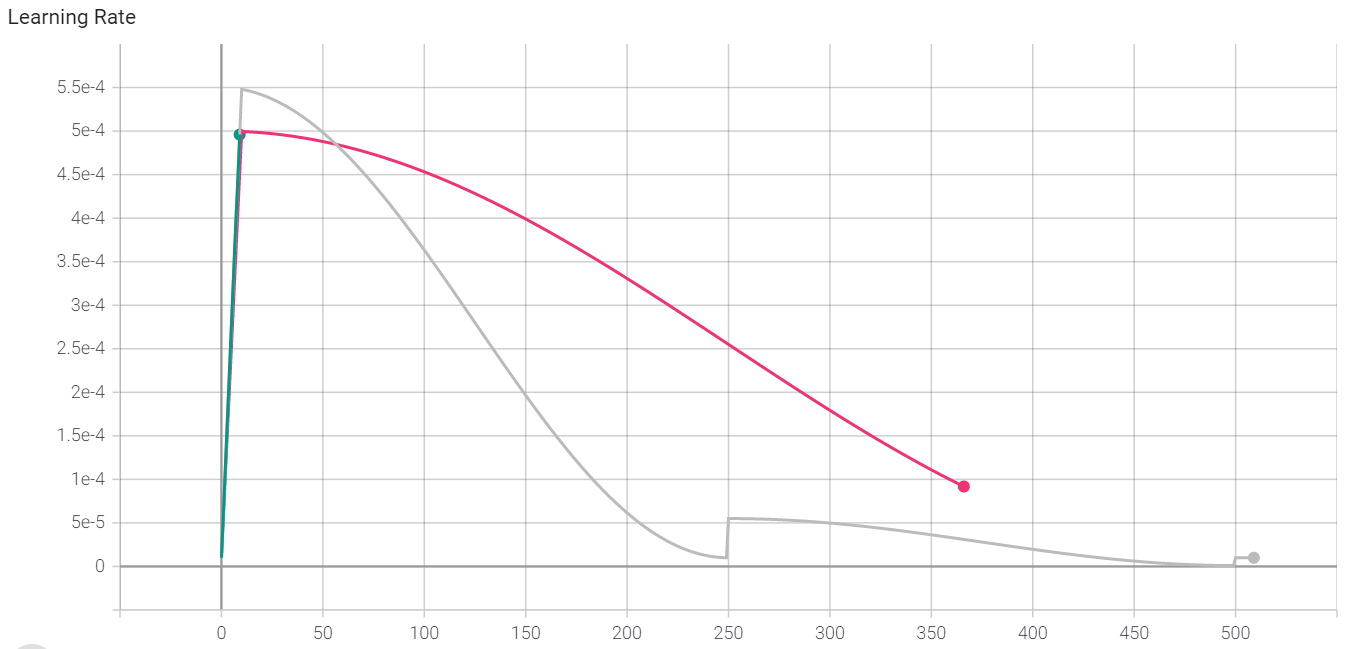
Restart不是瞬间的,而是线性增大的(只不过很快速)。其中涉及到这么一些概念:
- warmup-epoch:热身阶段。一般用于train-from-the-scratch(从头训练),开始的学习率小,是因为初始化模型时,参数随机,梯度也基本上是随机的。如果学习率太大,梯度乱飞,可能导致NaN。小学习率使得梯度稳定,开始时向正确方向移动。
- cooldown-epoch:冷静期。学习率减小到最小时(一般是周期性学习率scheduler结束),需要冷静一下,度过一段贤者时间,以小学习率训练一段时间。
3.4 LabelSmoothingCE
分类问题,标签是硬的。而神经网络输出,是模拟量,用模拟过程拟合离散过程存在一定难度(参考:正弦波无限叠加生成方波的吉布斯效应)。有可能在网络设计得不好时,分类很难是正确的。这个时候我们可以把硬的变成软的:
- Label本身转化成置信度(之前在二分类任务中用过)
- 在计算loss时进行label平滑。平滑嘛,那其目的离不开:防止过拟合,本质就是正则化手段,涨点tricks了
- Timm已经实现了这个loss,可以直接使用
3.5 加速
开始时我太笨?了?5个batch就很着急地eval一次,实际上没有必要,一次eval需要花费5-6s(CIFAR-10),那么batch size(开始时用的是64)情况下782个batch共需要eval 150多次,每个epoch训练的时间增加了10分多钟,太傻了。很显然这并不是我要说的加速。
加速有这么几种方法:
- 混合精度:我们已经知道(在我的CUDA第二篇学习博客中),双精度 非常拉,单精度还行,要是使用float16就更快了。pytorch提供一种混合精度的方式:AMP(Automatic Mixed Precision),自动确定哪些浮点可以简化。
1 | # From [6] |
- 当然,timm实现了更好的接口(NativeScaler),就不需要调用什么scale(loss).backward(), step之类的了:
1 | amp_scaler(loss, opt, clip_grad=None, parameters = model_parameters(model), create_graph = False) |
- cuDNN
之前一直不知道这个能怎么用,反正CSDN只顾授人以鱼嘛,告诉你装吧,也不告诉你装来干啥,粪坑实锤了(越用越觉得粪坑,实力坑菜逼)。cuDNN能加速一些运算,DL中,典型的卷积运算是会被加速的,cuDNN自动benchmark卷积,找到最好的卷积实现给你用。只需:
1 | torch.backends.cudnn.benchmark = True |
- 工人阶级的力量
数据集加载(Dataloader),使用多个workers。这里遇到了一些这样的问题:
- dataloader实际上在搞多进程,多进程默认是开子进程的(fork),但是:
The CUDA runtime does not support the
forkstart method; either thespawnorforkserverstart method are required to use CUDA in subprocesses. ---- Pytorch Document
如果在主进程中初始化了torch.cuda程序(先于dataloader有除了model.cuda()的别的cuda操作【?为什么model可以调cuda,难道因为它是进程间共享的?】),就会报错,说不能在fork的subprocess中初始化CUDA。解决方法确实就是,用spawn方法生成新的进程:
1 | torch.multiprocessing.set_start_method('spawn') |
spawn和fork的区别:stackoverflow.com: multiprocessing fork() vs spawn()。这里不多讲,spawn方式生成进程貌似炸了我的显存(原因可能有两点:1. spawn本身特性,会大量复制资源,每个新启动的python3解释进程都占用部分资源 2. 在CUDA误初始化,如果是这样的话,误初始化问题解决应该不会炸显存了)。炸显存的问题,这位CSDN老哥也碰到了,但他貌似没有解决。
开始时我一直没能用成fork,都使用spawn(启动很慢,而且还炸显存)。我发现官方实现可以使用fork方式,这让我感到很奇怪,查错最后发现是:RandomErase(Dataloader数据增强的transform)默认使用了CUDA,设置device为cpu就可以解决问题了。
3.6 Mixup
我超。我不知道这个工作:[mixup: Beyond Empirical Risk Minimization]。这个工作貌似是一种终极数据增强方法。
我超。这篇论文我看了30s之后就已经感觉有点6了,mixup就是将两个训练样本叠在一起,label可以不一样,叠加是加权的,最后形成加权的label,让网络去学。作者认为:
- 虽然普通的数据增强确实使得训练数据增多了,但是数据增强并不是在数据的真实分布附近采样,而是加了一些随机噪声,只是增强了抗干扰能力
- 简单地说,考虑一个多峰分布,mixup可以在峰与峰之间的某个位置采样,使得label和样本在另一种意义上被平滑了。Mixup的作者说到,mixup可被理解为是:
A form of data augmentation that encourages the model f to behave linearly in-between training examples
IV. 复现结果
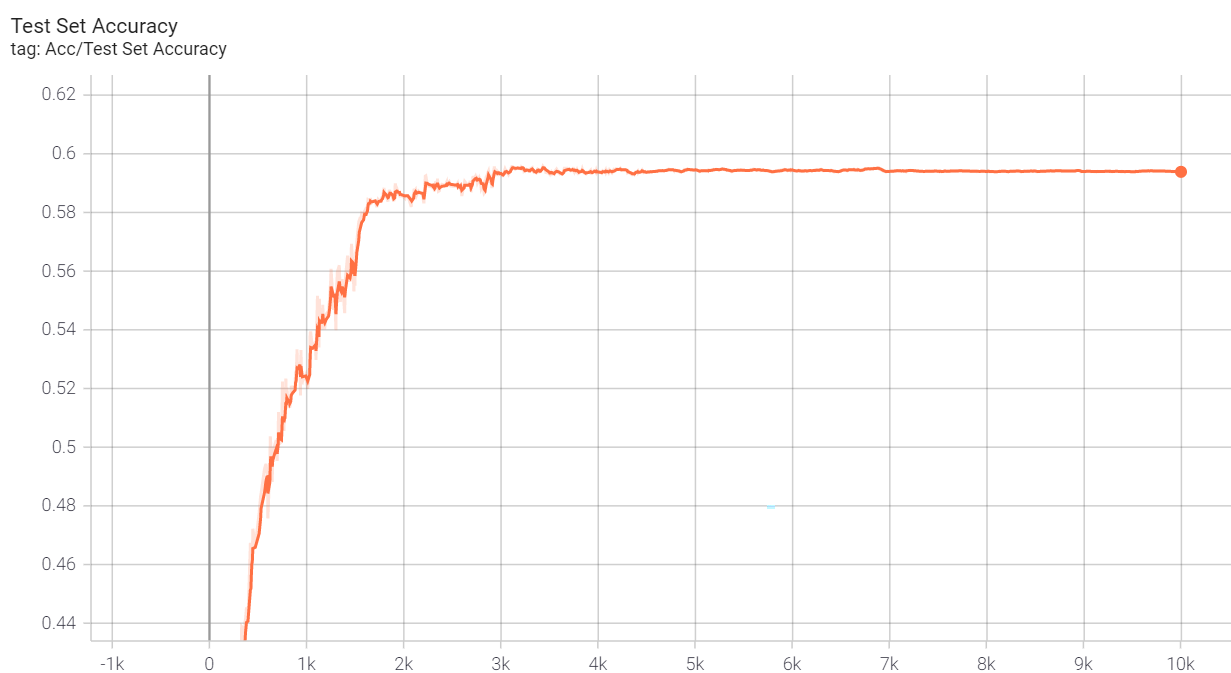
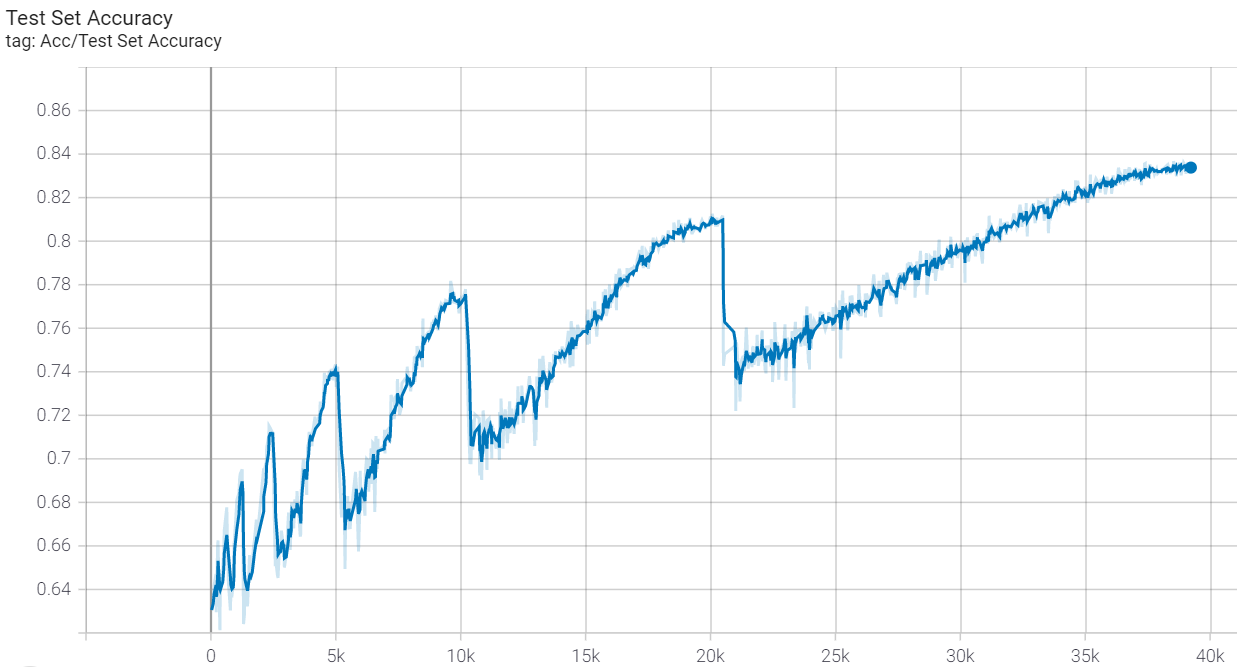
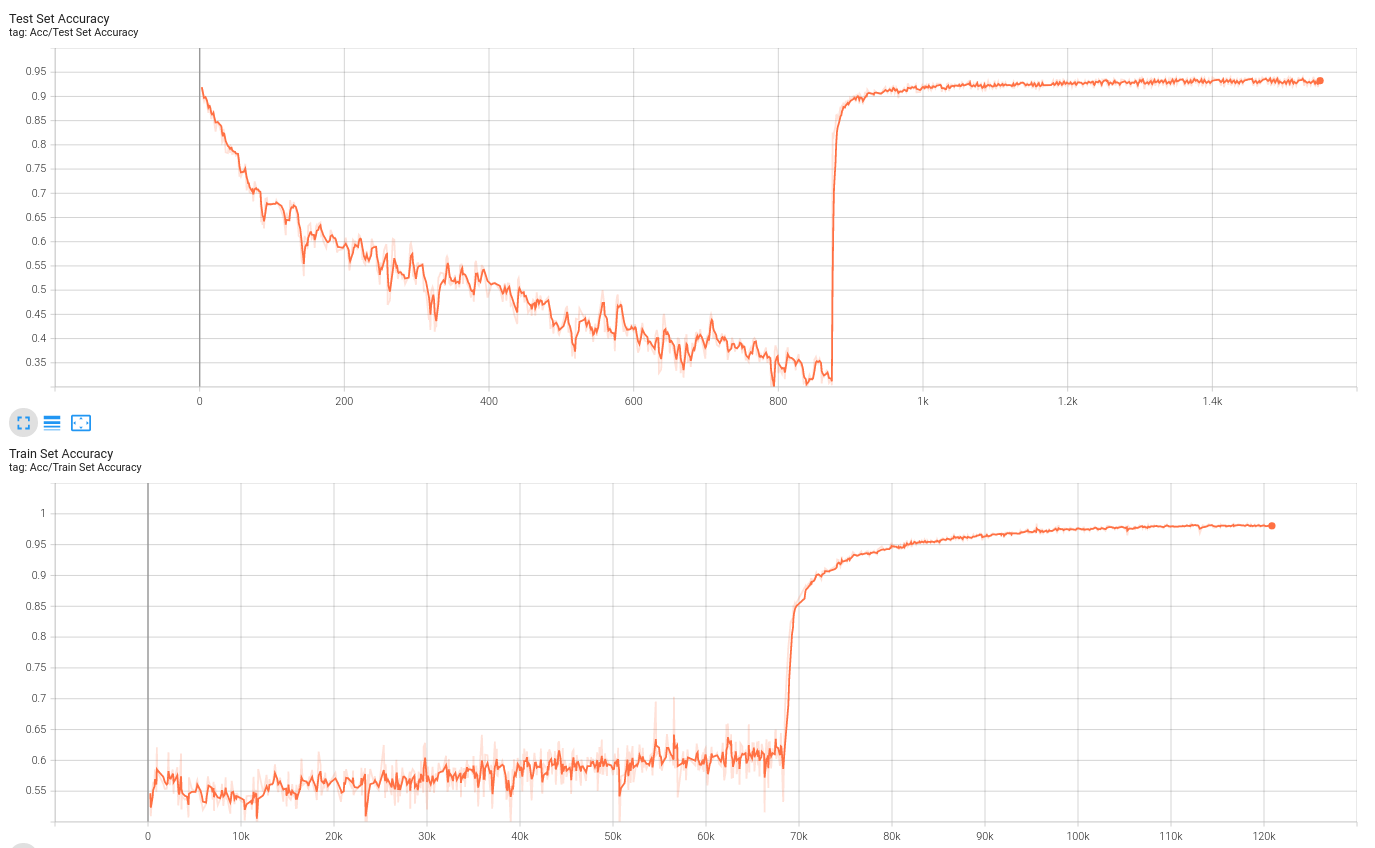
我怀疑我复现结果不如官方实现的原因是我并没有使用mixup策略,我使用的是传统的数据增强。我今晚(2021-12-05)尝试了一下mixup,但貌似(可能是没有用好,也可能是才训练了100个epoch,出不了结果)很拉,mixup参数与官方实现一致,就是没有直接调用timm库生成PrefetchLoader(因为没有时间去看文档)。无mixup训练的最佳结果是:训练集acc接近1,测试集acc 94.5%,过拟合还是有点严重:
|
|
|---|---|
| 最终(无mixup版本)训练集准确率 | 最终(无mixup版本)测试集准确率 |
12.8 更新
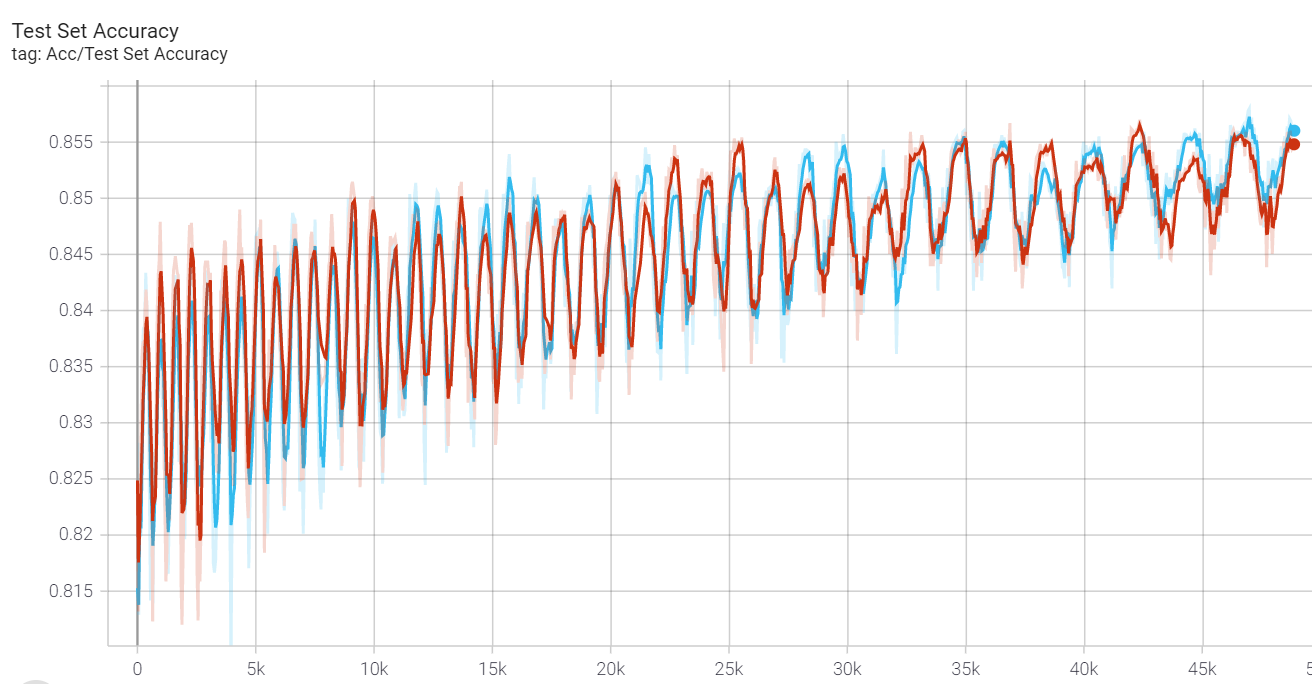
我尝试了一下Mixup(想要脱离timm库用mixup还是有点麻烦的,比如timm中的mixup把输入转换成了numpy。。。为的就是用里面的贝塞尔分布?所以不得不写一个可以把tensor转换成对应numpy格式的函数)。用mixup会使训练时的效果明显变差,但是一取消mixup,效果就很好:
Reference
[4] Fixing Weight Decay Regularization In Adam
[5] AdamW and Super-convergence is now the fastest way to train neural nets
[6] Faster Deep Learning Training with PyTorch – a 2021 Guide