Taichi Learning I
Taichi Lang I
I. Intros
巨佬们的工作(胡渊明,李子懋 both from MIT CSAIL):
- Taichi: A Language for High-Performance Computation on Spatially Sparse Data Structures. ToG 2019
刚好最近工作与图形学高度相关,并且一直觉得自己Python方面的技术栈太浅了(语法、代码加速了解得不够深入),于是想了解一下这个语言(与Python高度耦合)。这个语言在前年七月我刚开始做毕设的时候Dinger就在絮絮叨叨说Taichi怎么怎么香了,当时也玩了几个demo,但没有去了解语言本身。最近开始了解后觉得,要深入了解这个语言还是需要一些外围知识的辅助(比如,学了CUDA、LLVM等则会觉得接受其设计思想是一件比较容易的事情)。学这个语言的目标当然是用Taichi写一个简单的 path tracer 出来叻...。本文的主要内容有:(1)这几天学习时遇到的问题(2)一些Taichi底层原理(3)Python decorator补充(4)自己做的一些小demo。
II. Taichi scope
2.1 概念 & 调用问题
首先,我们需要明确Taichi scope与Python scope的定义(之后会给出一些由于我没有彻底搞清楚定义而犯错的例子)。根据官方文档:
- The code inside a kernel or a Taichi function is in the Taichi
scope. The code in the Taichi scope is
compiled by Taichi's runtime and
executed in parallel on multi-core CPU or GPU
devices for high-performance computation. The Taichi scope corresponds
to the
__device__side in CUDA. - Code outside of the Taichi scope is in the Python scope.
The code in the Python scope is native Python and executed by Python's
virtual machine, not by Taichi's
runtime. The Python scope corresponds to the
__host__side in CUDA.
我进行了一些小标注(__device__,
__host__)。就语言特性而言,与我的理解(类似CUDA)基本是一致的,甚至连kernel
call的方式也非常类似:kernel function只能在Python
scope中被调用,不可以在kernel或者ti.func中进行调用。CUDA实际上支持这一操作(dynamic
parallelism),但需要特殊的编译技术以及足够高的arch(而且从我之前的经验来看,动态并行的kernel调kernel技术不一定有多快)。
下面给出一个例子以说明如下问题:
A kernel can take multiple arguments. Note that you cannot pass any arbitrary Python object to a kernel because Python objects can be highly dynamic and may hold data that Taichi's compiler cannot recognize.
我在写SDF marching squares时由于有如下需求:
- 可视化的SDF颜色是不同物体颜色的混合,混合策略基于SDF(或者距离值)的大小。如果是简单的SDF marching squares算法,只需要把不同物体SDF加在一起即可。但由于有颜色混合需求,每一个物体的SDF需要被保存(以供后续使用,重算当然会更耗时)
- 我一开始直接用一个Python
list存储taichi.field,相当于:
1 | sdf_maps = [ti.field(dtype = ti.f32, (width, hieght)) for _ in range(ball_num)] |
一开始,我在Python shell中进行了简单的验证(是否会报错,是否可以修改其中的项),发现无问题。在实际运行时则报错(报错信息大概是)。首先简单提一下报错处的逻辑:
@ti.kernel函数,函数传入一个i32(作为当前处理物体的index)。那么如果需要计算对应index物体的SDF,则需要sdf_maps[index],将field从list中取出。
很快啊,直接报错:
1 | TypeError: list indices must be integers or slices, not Expr |
我大为不解。我传入的index都已经进行annotation叻,为什么说index是一个表达式?各种尝试无果,最后把list of 2D ti.field
换成了一个3D ti.field(我一开始的color
mapindexing也是这样的)。一个minimal的例子:
1 | ti.init() |
第五行的idx: int换成idx: ti.i32结果都是一样的。从报错的位置来看:
1 | ast\ast_transformer.py", line 250, in build_Subscript get_ref=get_ref) |
应该是在进行一些魔法编译或者LLVM转换。对此,Github的一个issue是[这样解释的]。
This is because Taichi doesn't like Python lists as data storage. The
Exprhere is acutually a Taichi integer, not Python integer, therefore cannot pass (原文打错了,达成了ass♂) as index to a Python list.
なるほど!
此即一个典型的例子:Python与Taichi数据结构最好不要混用。Python可以轻易访问Taichi的数据结构(比如在ti.init之后创建一个ti.Vector.field,通过indexing可以很简单访问),但在kernel中却无法很好地对Python的动态数据结构进行访问。而且动态意味着,编译时所处理的内容都是不确定的,谁能知道for循环内要对什么样的变量进行遍历呢?
顺便提一句,kernel要求还挺多:
- 只能有一个return语句(很久之前的CUDA好像也是这样的)
- 只能返回一个变量(不像python可以pack成一个tuple)
- 返回变量的元素不要超过30(... 为什么,出于性能考虑么)
- 返回值可以进行类型转换(比如我返回一个Vector,但是返回的type annotation是i32... 这样的cast做不到)
- kernel函数输入变量有大小限制(啊这):OpenGL为32个element,其他为64个。
- kernel会将全局变量视为常量(不当指针),应当只有field做得到非常量:
Vector,Matrix,Ndarray都是无法进行kernel内indexing的,会报错如下错误。
1 | AssertionError: __getitem__ cannot be called in Taichi-scope |
关于这一点,我多嘴几句。Taichi有强制 loop unrolling 机制(使得for loop无需判断循环条件,更快),所以在kernel中的 Vector, Matrix,其indices都需要是编译期常量(compile-time constants)。也即:
- field 可以使用变量进行indexing操作
- Vector,Matrix在Taichi scope中只能用常量进行indexing。不是特别方便,阻止了任意的向量、矩阵操作(只能使用内置的函数操作),CUDA至少还有很高的自由度(对应的开发难度当然也比较高)。
- scope local variable,看下面一个例子:
1 | vec = ti.Vector([1, 2, 3]) |
输出将会全都是[1 2 3]。感觉很奇怪?不奇怪,对Pythoner来说很奇怪:C/C++中重名的local
variable优先级都会更高,由于Taichi是编译式的,vec在kernel内定义了一个重名的local
variable,改变它的值当然不会影响global变量。而如果你想要改变global变量,在Python中我们学过global关键字,但在Taichi中被ban叻(会报错):
1 | Unsupported node "Global" |
而@ti.func的要求则很宽松。
2.2 反向问题 - Python scope做不到的事
最简单的:Python
scope中无法调用@ti.func修饰的函数,正如CUDA中,CPU无法调用__device__声明的函数而只能由__global__或者另一个__device__函数调用一样。从现在遇到的问题来看,这部分可以说的内容并不多:
ti.random不可在python scope中被调用(此外需要说明的是,这个函数只接受primitive types, 比如float, int之类的,假设我需要一个random matrix,最简单的办法可能是用numpy再利用Taichi的from_numpy接口)。- 原子操作(
atomic_xxx系列),看下面一个例子:
1 | def test_atomic(): |
注意,第九行可以顺利执行,结果也是正确的(虽然这里用原子操作并没有什么意义,原始代码就不会有什么race condition)。而第十行会报错:
1 | ...\taichi\lang\ops.py", line 1235, in atomic_add |
个人认为原因与kernel编译机制有关:直接在Python
scope中运行使用的是Python虚拟机以及解释器,可能不存在指针这种玩意?而如果在Taichi
scope中执行,会先编译并转为对应backend(如果是C++后端则可以有指针设计)。这个例子中,原子操作并没有被直接禁止(ti.random则直接报错说不能在Python
scope中被调用)。
此外注意,某些函数在ti.init调用之前不能调用(可能,所有函数吧),举个例子:ti.field创建一个field,这个函数不能先于ti.init调用,但ti.Vector之类的数据结构(Taichi基本结构,在ti.types中可以找到类型的,是可以的):
- 比如
ti.VectorNdarray,ti.MatrixNdarray,在ti.types中没有,虽然在没有init时调用不会告诉你May be call ti.init() first?,但由于在构造函数中都有:
1 | self.arr = impl.get_runtime().prog..... |
get_runtime()在ti.init被调用前是None,所以其实隐式要求了init。
2.3 泛型与编译过程
我还没有深入到泛型的使用,故本节只简单提一些设计以及逻辑层面的内容。
2.3.1 Why type annotation
C++的泛型还不是特别熟(use case不多,练得少,设计泛型小项目有点... 困难?费脑子?),只能进行一些基础编程。唔,现在接触了三种泛型,三种都是浅尝辄止(淦,感觉万金油什么都不会捏):
- C++ meta-programming
- Rust generics (Rust太久没写了,有点忘了)
- Taichi meta-programming
(正文开始)官方文档上有这样的一段话:
- Type hinting in Python is recommended, not mandatory.
- Taichi makes it mandatory that you type hint the arguments and the return value of a kernel unless it does not have an argument or a return statement.
也即要求进行显式的type annotation(在编译时Taichi backend编译相当于类型声明)。为什么要这样?原因其实很简单,类型推断不是一件简单的事情。我们在C++中接触了很多类型推断的case,举个例子:
1 | template<typename Ty1> |
问上述Ty1,Ty2,idx分别推导出来是什么类型?这里只给出结论,不清楚的话自己去补:Ty1 = const int,Ty2 = int,std::vector<int>::const_iterator。但从这样的简单例子可以发现(我的目前的理解,可能是错的,毕竟我泛型学得不深),C++可以进行类型推断一定在于参与推导的类型一定是编译期可知的(直接,或间接)。对于Taichi而言,由于kernel
function是从Python
scope中调用的,Python作为弱类型动态语言,类型是不定的,你要让Taichi编译器无中生有,从你都不一定知道是个啥的类型中推出来简直是强人锁♂男。所以参数、返回值需要强制type
hint(返回值的话,我总感觉可以推出来的样子?乍一想脑子里没有很好的无法推出的例子...)。
2.3.2 编译过程在做什么
粗浅理解一下,这里只提一些重要过程:
graph LR A(Python code)-->|AST transformation|B(Python/Taichi AST)-->|Optimization / compile|C(Taichi IR)-->|Optimization / compile|D(Kernels)
首先是AST transformation(Abstract Syntax Tree),相当于将Python code组织成更容易分析、跟踪的表征(比如,清楚地记录每个symbol在第几行第几列,属于调用、函数名、变量还是什么其他的类型),这是Python code在进入解释器之前的一步重要操作(可以看作是一种“编译”),详见[这篇文章]。Taichi也会生成对应的AST,对AST进行分析,生成Taichi中间表示(IR - intermediate representation),与LLVM不同,Taichi中间表示更加“高级”(high-level),粒度更大、更加抽象,所以保留了很多原有的信息,对Taichi IR先进行一次优化可以得到更好的优化效果:
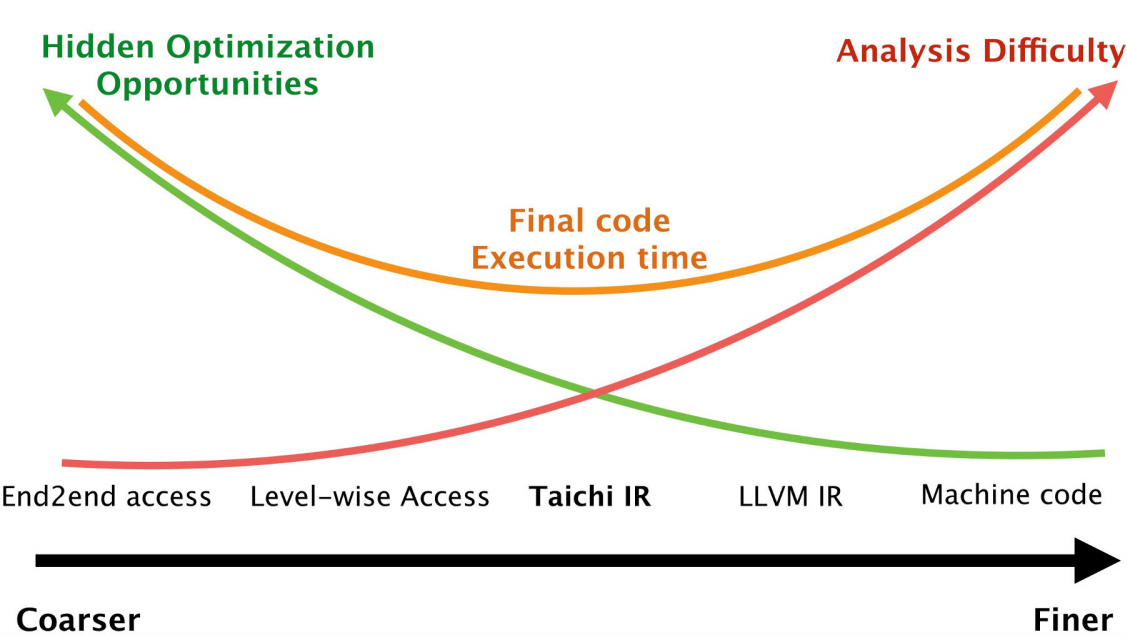
胡渊明在其PPT中提了一些有趣的点,用以佐证“信息越多,优化机会越多”这一观点:
- 指针名不可相互覆盖:
a就是a,b就是b,除非两者相同,否则两者不会指向同一位置 - 内存访问全经手
field[indices]:C中的指针可以灵活地cast,“几乎任意地”指向任何object,这会给优化造成麻烦,而Taichi中,指向的object以及类型都是固定的(const以及类型已知的指针) - 修改存储信息的唯一方法:
field[indices](灵活性换速度) - 读操作不会修改任何内容:不报错,也不会在超界时“智能地”new一个object出来
2.3.3 Interesting BLS
此处真就几句话带过:Block local storage(目前还没用到,但读docs时看到这个feature,觉得非常有意思),假如你明白CUDA内存机制,这个概念就非常简单,下面以CUDA内存机制进行类比:
- GPU的两类内存:global memory(顾名思义,任何block、线程均可访问),shared memory(一个block内的线程共享,不同block之间不可相互访问)
- global memory巨慢无比,shared memory访问速度可达global memory的20-100倍(通常,10个cycles内,相比于200cycles以上的global memory)
- 需要反复读取或者写入的变量:如果不存在寄存器上,就可以存在shared memory上加速访问。
Taichi也有类似操作,见下图,这里我就不展开讲了:
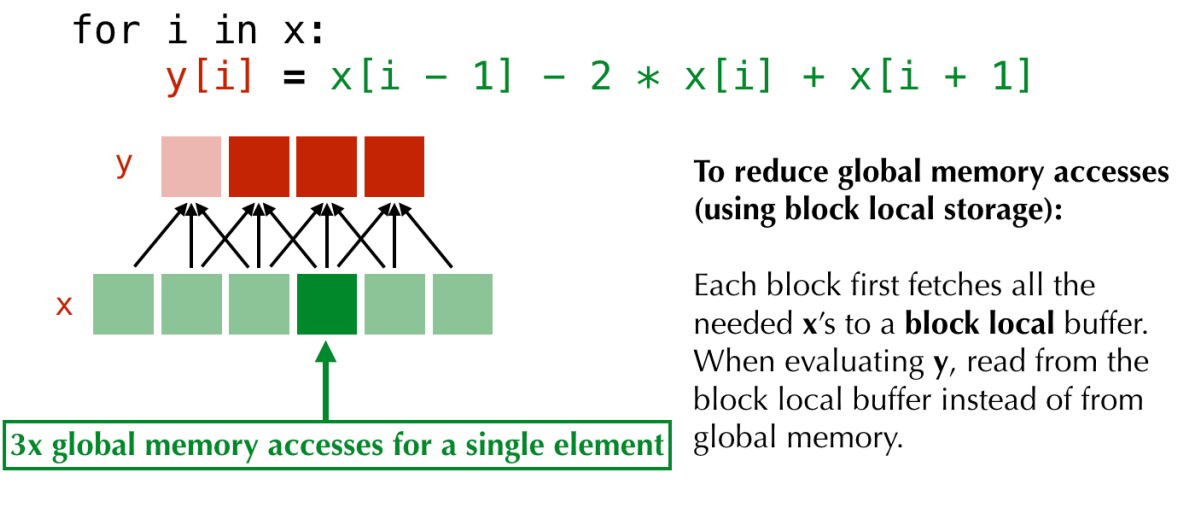
虽然Taichi没有CUDA底层那么灵活,但它效率高啊,我是经历过这种事情的(见下图),之后需要好好研究一下ti.cache_shared以及一些进阶加速写法。

III. Python盲区 - decorator
遥想公瑾当年,看不懂decorator的燃情岁月,仿佛就在昨天。当年对语言、算法的敏感度都没有今天那么高(相对高,绝对低),看不明白是很正常的事情,加上笔者比较笨、急躁,看两眼就润了...
decorator其实很简单,不懂的时候觉得装逼,懂了就觉得挺语法糖的(毕竟减少了代码重复率),对于简单的用法,其本质就是:由于函数也是object,可以赋值来赋值去的,一个“修饰函数”可以接收函数object作为参数,在原函数的基础上增加一些功能(但保持原函数代码不变性),内部实现就是一个函数wrapper:
1 | def init_notify(init_func): |
实际上,@init_notify过程就是把initialize包了一层,等同于init_notify(initialize),但是init_notify(initialize)写法也太函数式叻(假设我有很多wrapper,每个都要包一层,看起来就跟洋葱似的)。注意,如果修饰器要带参数输入(带参数修饰),则更加复杂,由于作为修饰器本身的函数只能接收一个参数:@init_notify
是修饰器函数,其本身的参数就是下面的initialize函数,跟在@后面的这一块是一个
单一参数函数,那么我们只需要设计一个函数,返回一个单一参数函数但同时支持输入我们需要的内容就可以:
1 | def notify(name: str): |
调用很简单:@notify("Initialization")。别以为这里的修饰器函数带了参数,修饰器函数不是notify,而是notify的返回值(一个单参数函数)。
参考Taichi的源码,查了一下@ti.func / @ti.kernel,代码中用到了functools的wraps函数:
1 |
这个函数的作用就是将输入函数的部分信息迁移到修饰后函数,由于修饰后函数实际上是返回的inner_wrapper函数,其名字(__name__),help文档(__doc__)都无了,故可以用wraps函数修饰inner_wrapper(直接在def inner_wrapper上方加@functools.wraps(func))。
注意,Taichi的修饰器函数貌似有两个输入参数。有默认参数则没有问题,代码中也给出了True的修饰方法:
1 | def func(fn, is_real_function=False): |
也就是说:@real_func就行了。不过我现在还没查到什么是real
function
这里提供一个小sidenote:@pyfunc修饰:表示被修饰函数可以在Taichi
Python scope中调用:
- 在Taichi scope中调用时,会进行编译
- 在Python scope中调用时,直接就是原始Python
code的执行方式。这么看来,相当于
__device__ __host__修饰的CUDA函数,可以同时在host以及device上调用,不过CUDA会编译生成两份代码(一份是NVCC编译生成的GPU代码,另一部分是C编译器生成的CPU代码)。
IV. Show Cases
很垃圾的玩意,刚学,技术很差。不过Taich确实强,SDF这个比我之前用OpenCV写得快多了(虽然逻辑不是特别一样,但功能更强了,OpenCV那一版本只能绘制zero level set,这一版本我可以混合颜色)。具体的代码见:Github: Enigmatisms/learn_taichi
| Distance Field visualization | SDF marching squares |
|---|---|
 |
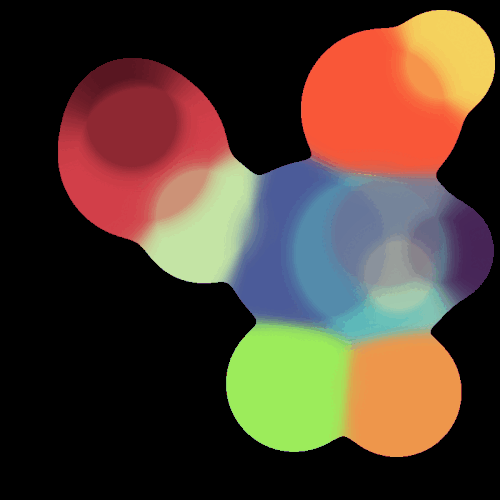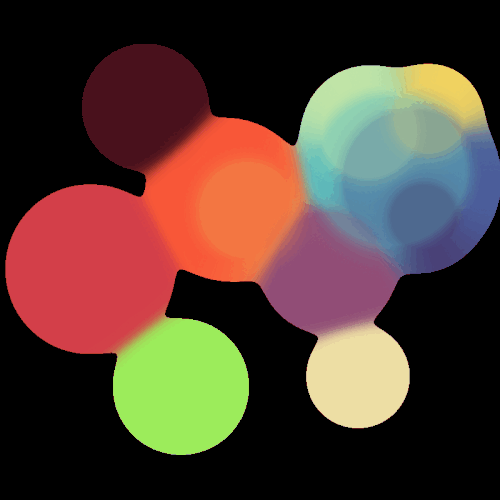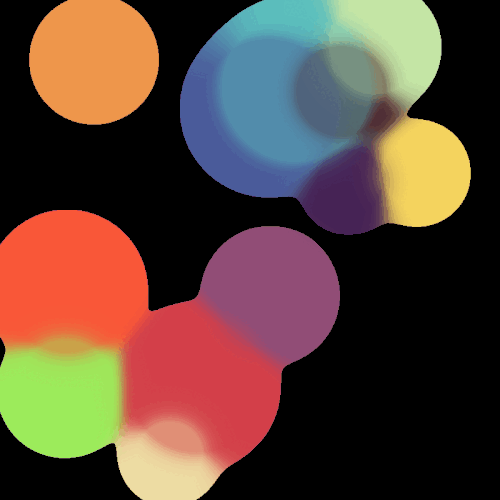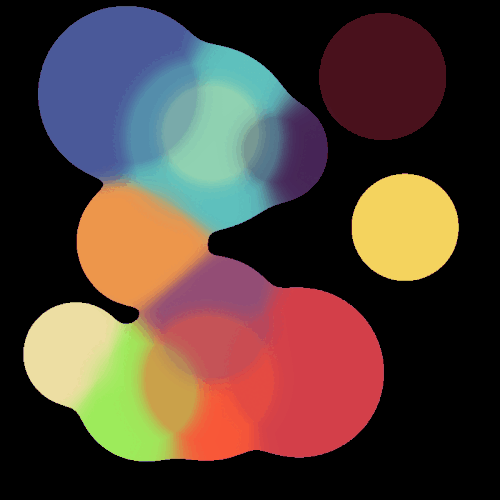 |
Reference
[1] Hu, Yuanming, et al. "Taichi: a language for high-performance computation on spatially sparse data structures." ACM Transactions on Graphics (TOG) 38.6 (2019): 1-16.
[2] Yuanming Hu: Life of a Taichi Kernel
[4] Taichi lang docs