高性能异构计算相关知识
HPC I
投了几个 HPC 岗... 虽然不是科班出身,但个人觉得 HPC 还是挺有意思的(尤其是自己写 CUDA kernel 加速几百几千倍,那种成就感简直...)。HPC 的魅力之一在于,反馈非常及时:某种优化策略可能可以瞬间带来 profiling 时某一项的提高(比如 throughput, speed 等等)。我自己搞 rendering 的过程中也在不断尝试一些小的 tricks (比如SSE啥的,毕竟多线程这种东西根本不用我写... 随便拉出一个线程池来都是自带 scheduler 的...),感觉过程中还是能学到很多东西的,对 CPU/GPU 的各种设计也能有更深的理解。
本博客是我认为比较重要的相关知识(第一部分)以及我觉得我可以回答的一些问题。
1.1 底层计算加速知识
解答这个问题,主要知道 CPU 的流水线模型。CPU 执行代码一般都是按如下的方式:(1)取指令(2)取数据(3)执行指令(4)写回。假设我们有大量计算需要进行,实际上可以:
取指令(1) 取数据(1) 执行指令(1) 写回(1) 取指令(2) 取数据(2) 执行指令(2) 写回(2) 取指令(3) 取数据(3) 执行指令(3) 写回(3) 取指令(4) 取数据(4) 执行指令(4) 写回(4) 我的理解:每个这样的简单阶段都需要花费一个时钟周期,所以如果我们把这四个阶段标注为 A, B, C, D,实际的执行顺序会是:A1, (B1, A2), (C1, B2, A3), (D1, C2, B3, A4), (D2, C3, B4), (D3, C4), D4。看起来好像还是串行的,那么为什么流水线化就有好处?因为被骗了,可以这么理解:调用(call)一个指令,一般只要一个周期,但是指令完成(complete),时间是不定的。比如 B1(第一次取数据),cache miss,则可能花费几十到几百周期。在此期间,CPU 可以选择直接开始执行 A2。A2 完成了如果 B1 还没有完成,则 B2 会停下来等 B1,整个流水线停住(流水线停滞)。
如果要更清晰地理解,请看下面将 GPU stream multiprocessing 的图 (Figure 1.1)
所以为什么要五级?越多看起来虽然越好... 但是:(1)硬件复杂度与设计、实现成本。流水线多了硬件自然就复杂了,而且功耗可能还会变大。(2)会提高流水线停滞的风险:越多指令进入,就越有可能产生数据依赖与竞争。这是一方面:不能太多,多了也不好。自然,也不能太少,少了则无法做到 latency hiding,吞吐量也上不去,指令级并行(Instruction Level Parallel)效率也就不高。
五级是骗人的... intel i3/i5/i7 很多是 14 级。
里面的另一个概念:超标量处理器(super-scalar)。超标量处理器表示此处理器可以同时(真正的并行,而不是并发)执行多条指令,比如:
1 | ADD R1, R2, R3 ; 整数加法指令 |
以上四条指令可以一起处理。可以认为是一种“硬件层面的多线程”:
- 并发:同一时间段内处理多个任务。不要求某一个时刻多个任务在进行。单核也可以并发(时间片轮转),非超标量处理器的指令执行模式一般就是并发。强调任务之间的协调与调度。
- 并行:同一时刻处理多个任务。超标量处理器可以同时处理多条指令,所以是并行模式。强调任务之间的同时执行。
关于 CPU 流水线中可能出现的 hazard,本文罗列一下三种:
data hazard:数据依赖性:一个指令依赖于另一个指令的数据,但对应指令尚未完成,使用的错误的值进行计算。
RAW(read after write):指正常情况,第二条指令执行需要在第一条指令执行完成之后,写入了某个区域再读取(最常见的,比如说连续计算)。当出现乱序执行或者超标量执行时,顺序可能会变,导致 read before write(相当于使用旧值)。这种情况在compile time一般无法处理,需要在run-time 处理。因为对应的数据依赖是 compile 不可知的。
WAR(write after read):这种情况正常时,是读取完对应区域的值后,再用新值覆盖之。结果出现 hazard 时,还没有读某个区域,就已经覆盖了对应区域。导致读到的值过新。这种情况一般可以通过 register renaming 在 compile time 就解决了。
1
21. ADD R1, R2, R3 ; 将R2和R3相加,并将结果存入R1
2. LOAD R2, [MEM] ; 从内存中加载数据到R2寄存器比如上面这个例子。R2 是会发生 WAR hazard 的寄存器。实际 register renaming 时,renaming 会将 R2(load 指令)替换为一个实际的物理寄存器地址(本来是逻辑寄存器)。是的 ADD 的 R2 与 LOAD rename 之后的寄存器对应不同的物理寄存器,避免了 hazard
WAW: write after write。指对同一处内存的两次 write,顺序错了。比如应该是指令1先 write,指令2 覆盖。结果由于乱序导致指令1 的结果覆盖了指令2(正常人写不出这样的指令,因为这样的指令必然导致一个指令的结果被覆盖,一般都是乱序发射和超标量引起的顺序改变导致的)。所以也可以在 compile-time 进行 register renaming。
control hazard:主要是逻辑跳转不加处理时,流水线不知道之后应该往哪一条路走。一般来说,control hazard 引入的是控制逻辑的依赖,会导致流水线停滞。处理方法一般有两种:
- 分支预测:预测对了就不会有问题,相当于没有分支,流水线不会停。而如果预测错了,只能清空流水线了。所以... if else 能不用的地方就别用。GPU 不喜欢,CPU 其实也没有多喜欢。branchless 的 二分查找都比有 branch 的快很多。
- branch delay slot: 之前计组课说到了。主要意思是:分支指令执行一般需要比较长的时间,我们可以利用这段时间来处理分支指令附近无依赖关系的指令(比如先做个预取)。实际实现时,就是在分支指令后插入(调整位置)对应的指令,使得分支指令执行时,流水线可以继续处理。
structural hazard: 指资源竞争。比如 IO 设备,DMA总线,ALU 等等。比如:两个计算指令,只有一个 ALU,那么两个指令只能排队。这种情况就只能去设计一个好的调度算法,并且注意资源复用性。
C++ 与 Rust 是编译型语言,内存的使用与释放都需要显式定义。虽然引入 RAII(资源获取即初始化)之后,“显式”并不那么突出了:
- std::vector 你知道其底层怎么分配数据的吗?代码全部将这一块藏起来了。实际是其对应的 allocator 进行的,其析构实际上是对应变量超出生命周期后,自动进行的(析构函数的调用是由编译器插入的,比如插在 delete 后,或者超出生命周期位置)。
- 但对于编译器而言,什么时候申请与释放,大多数时候都是确定的。
Java 与 Python 是解释型语言(Java 是 JIT,其实还挺快的,Python 属实... 那什么)。这两种语言使用的内存管理模式是 GC (garbage collection)。因为执行是动态的,变量的生存周期难以确定,只能找个捡垃圾的人,不断地问:你这水瓶还要吗?不要我捡走了。但 Python 和 Java 的操作不一样:
- Python 的 GC 感觉挺像 std::shared_pointer,是有一个引用计数的。但是引用计数坏就坏在存在循环引用,循环引用还会比较恶心:假设 A 要 B,B 要 C,C 要 D..., Z 要 A,就成了一个大环。Python 会有一个查环的机制,如果查到一个环,并且没有外界引用,相当于瓶子开会,瓶子们希望保留别的瓶子,那捡垃圾的哥们可不管这么多,发现都是瓶子互相依赖就捡走了。
- Java:从某个根对象开始,标记所有变量是否可达。如果不可达(没有引用关系),就回收掉。
所以 GC 本身会占用一定的算力:一般是以一个后台线程或者进程实现的。GC 会定期检查不需要的内存(或者在用户指定时,比如 del 可以触发 GC。慎用,小变量就没必要了,大内存回收可以手动)。
下面我们来讲讲 C++ 的 operator new 与 delete 与系统调用 malloc/free 的区别,以及 operator new / delete 是怎么实现的。
可以这么认为:new 是个更强力的 malloc。底层也有 malloc,但 new 会多做这么两个事情:
- operator::new 会调用对应对象的构造函数。malloc
就只有一块内存(没有经过
initialized的)。相当于:
std::vector::reserve就在申请一块未初始化的内存,emplace_back则会原地初始化。 - operator::new 会抛出异常:如果申请失败,会抛
std::bad_alloc,相当于一个带 try / catch 的 malloc,malloc 失败就返回一个 NULL。我们可以指定new(std::nothrow)来模拟普通 malloc 的模式(失败返回 nullptr)。
同样地,free只清除内存分配空间,不调用析构函数(所以,如果有特殊析构就GG)。但 operator delete 一般不会抛异常,除非析构函数抛异常(说是,我们应该避免在析构函数里抛异常)。注意,我们一般不会说 delete 有什么异常(exception)特性,但除调用析构函数之外,与 free 还是有一些其他区别:
delete []会逐数组元素调用析构函数。- delete nullptr 什么事都不会发生。nullptr 是 delete-safe 的。但我们不能 free(NULL)。
最后提一句,为什么要避免在析构处抛出异常:析构函数首先需要保证一件事情:任何时候都可以成功完成,不会被打断,应该是
noexcept 的(C++ 的一个隐式声明,析构一般都是
noexcept(true)
的)。一旦被打断,可能会导致未定义行为以及调试困难:
- 部分析构:某些动态内存没有完成 free,直接泄漏了。某些文件句柄没有 release,直接泄漏了。
- 调试出现很大的问题:抛出异常时,调用栈一般会开解(回想一下:调试的时候,出现了异常,异常会按照调用栈不断向上抛,抛到一个合适的 entry point,可以被异常处理机制捕获到,此时,与异常相关的一些变量全部会存在内存中),但如果是析构函数,调用栈开解前可能释放了部分内存,导致调用栈的上下文信息不完整。
delete 行为与析构关系很大,一般delete抛的错误是析构函数抛的。delete 失败(比如 double delete)一般是出未定义行为,可能会抛异常,也可以直接段错误了。
Memory bound:
- 光线与场景求交。求交操作本身很简单:AABB
与光线求交就没有特别难处理的计算,而光线与面片相交本质是求一个线性方程组(重心坐标u,
v 以及光线方向距离 t,三个值我们都需要),计算也不难。但不同的
BVH,AABB,面片以及 object
信息,在内存中的位置可能非常分散(即便使用了一定的访存优化)。此部分很容易引起
cache miss。
- 化分树线性化。BVH 树,或者 KD 树通常的构建方法是基于指针(指向左右孩子),这种方法会导致内存非常分散。当光线求交时,我们总是顺树去查:从根到对应的叶子,而跨度大可能造成 cache miss。如果将树展成线性的,比如中序遍历输出或者是先序遍历输出,所有节点保存在连续的内存中,可以提高访存效率。相应地,对应的面片数据也可以按同样方式划分。同样,存成 AOS(这里 SOA 效率不够),AOSOA 感觉也不用考虑。
- texture fetching 也是 memory
bound:光线每次击中的位置都可能非常不一样,不同核(对应不同cache)可能每次拿到的光线也不一样(基于thread
pool,可能没什么规律,tiled-based 会好一点)。而一般每次 texture
都只取一个 texture map 上三个孤立点:texture 经常变,texture mapping
的点也经常变。
- 怎么优化呢?AOS 和 SOA 需要权衡。比如 texture 一般是 SOA 的(R G B 分别存),但光追 texture mapping 每次就取几个 离散的 RGB,所以 RGB 连续会比较好。否则不同通道之间还可能需要多次传输,可能还会存在 cache miss。
- tiled-based:分块渲染。块内的光线方向差别不大,在光追时,击中的位置相对集中(相对,相对于本次取 (0, 0),下一线程取 (H - 1, W - 1))。可能可以带来更好的 cache coherency。
- Path guiding: 在线学习的 EM 过程是 compute bound(用于迭代的数据比较集中,取一次迭代多次),但采样 / 空间划分的时候是 memory bound。这个怎么提升不多说了,方法差不多。
Compute bound:
采样算法:比如 microfacet 模型吧:\(FGD / (4\cos\theta_o\cos\theta_i)\),F 是菲涅尔(不是特别好算,但已经算不错的了),\(D\) NDF(一般来说是一个复杂的函数),G(也是一个复杂的函数)。分母还有两个 cos(不是 cos 就是点积)。而且有的时候需要 MIS(多种采样策略,每一种都试试,最后加权),我论文里的 distance sampling 就是典型的 compute bound。
其他时候,光线追踪中的 compute bound 并不多。BDPT 中的 MIS 算另一个,但那个就很复杂了,而且很难说清楚是 compute bound 还是 memory bound (vertex 内存分散,但计算本身又需要循环)。
怎么提升? compute bound 一般都很难通过 trick 提升。计算复杂是没办法的,特别是与数学公式有关的。只能找一个更好的理论,或者找更好的算法。否则只有近似这一条路。我们一般不讨论 compute bound 问题的提升方法,因为非常 domain/task specific。
负载不均衡问题:可以使用 tiled-based rendering 解决(local tile 的负载一般比较均衡,除非场景的几何在图像域的变化非常大)。在实现代码的过程中,需要尽可能避免分支。比如 DrJIT 以及 taichi lang 其实都有对应的条件选择函数,实现 branchless 值 selection。现代 GPU 有 ptx 指令集的 SEL 指令,我们也可以实现 masking,也可以通过条件表达式来做到这件事。
texture 与 常量内存使用的问题。constant memory 不用多说,constant memory 适合存小块的且经常访问的内存(比如,光源信息,相机信息,全局场景介质信息等等),关于 constant memory 为什么快,看 3.2 节的内存访问模型。texture memory 我们说得很少(我自己没用过),texture memory 需要经过 CUDA 绑定为 texture 对象:
1 | cudaArray* cudaTexArray; |
先分配一个 Array(多维数组),后将 texture 绑定在对应的
Array,将会生成一个 texRef (纹理的引用),可以用
float value = tex2D(texRef, x, y); 来 query。注意,此 query
自带硬件 lerp(可以设置方法),而且还可以通过 cudaTexDesc
设置 mip-mapping(牛)。texture memory 可以使得 text fetching
这件事简单一些(效率更高)。光线与场景求交就用 RT-core 吧!剩下的采样...
写在kernel里。
1.2 底层计算加速知识
GPU 的内存模型还稍微好写一点,执行模型就有点不行了... 感觉自己老是分不清楚 SM, SP 这些概念。
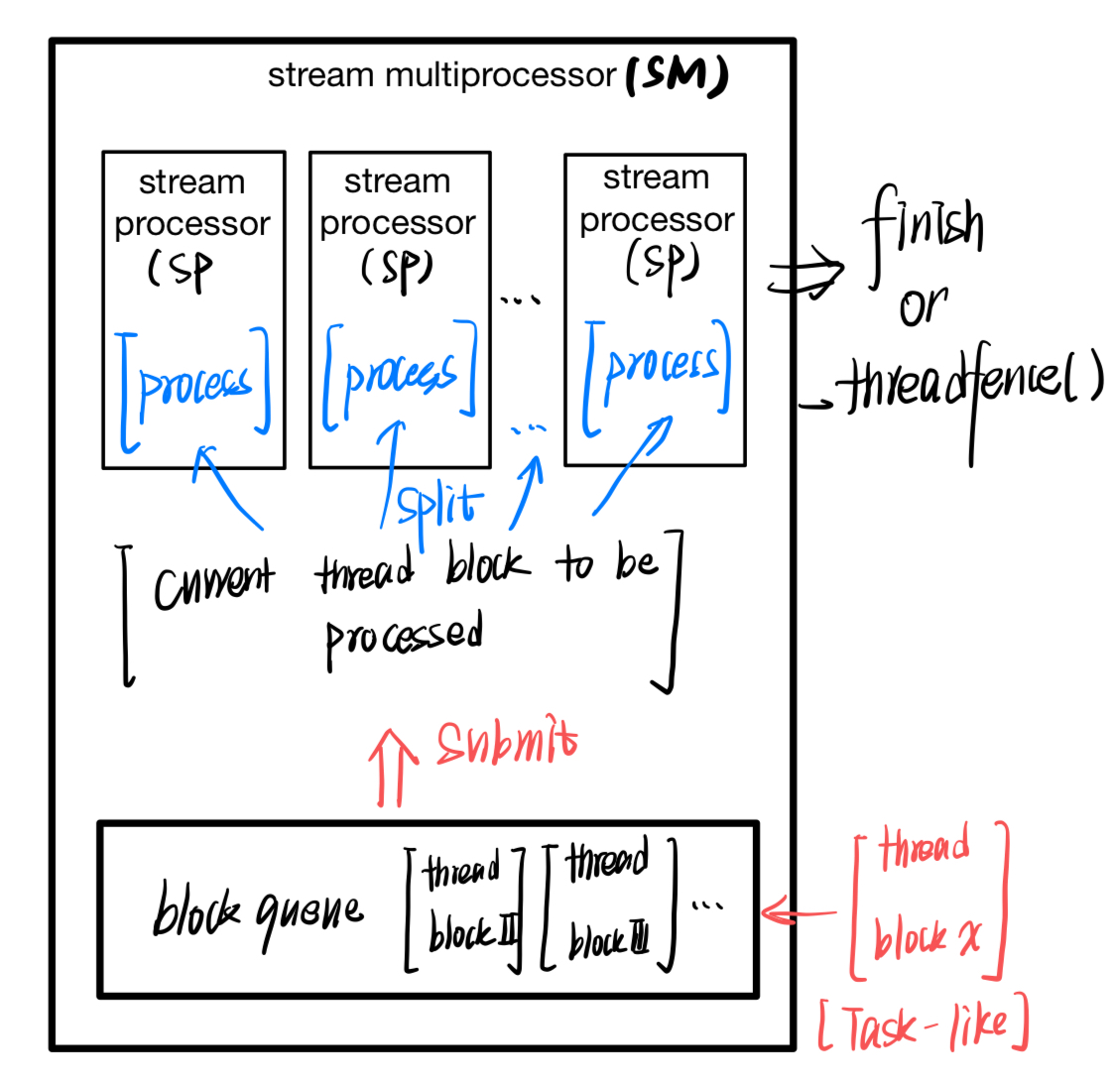
SM 是一个执行器,一个 SM 只能同时处理一个 block(所以说,为什么要 block 内部线程足够多)。如果线程不够多,相当于我们给一个庞大的工厂提供了一个简单的任务,而工厂维持设备运转是有成本的(高负荷生产一小时也是X成本,低负荷也是X成本,那理所当然应该高负荷),需要工作尽可能填充对应的机器。SM 是最顶层的计算单元,一个 SM 将会有很多 SP(stream processer)。而由于一个 SM 处理一个 block,那么可知,一个 SP 处理的是 block 的一部分,那么是哪一部分? 很容易想到:warp。我们可以这么认为:
- 一个 SP 通常只有一个 IP(instruction pointer),所以一个 SP 只能在同一时间处理同样的指令,有同样的行为。如果遇到 branch (warp divergence),就必须有一部分线程被 mask 掉,处于暂时 idle 状态,直到待会儿需要的时候继续执行(串形化)。
- 顶级 SIMD 思想:只有数据不一样,指令是一样的。
注意,SP 和 warp 一样,都是硬件概念。 warp 是 nvidia GPU 中任务执行的基本硬件单元(不是 thread 哦),thread 是基本的软件单元:thread (软件端)定义了一个 warp(硬件端) 的行为 --- 写 CUDA 的时候都是定义单个 thread 的行为,而不是定义单个 warp 的行为,因为 warp 内部确实是允许有不同行为的(分支):
- thread:编程模型,软件端的最基本单元
- warp: 硬件模型,执行指令的最基本单元
SP 一般包含三个大组成部分:
- warp:被执行的“指令容器”(相当于一块可编程的电路)--- 被执行的硬件单元
- 执行单元:ALU 等 --- 配备给 warp 中的每个 thread(软件行为层面的概念) 的:相当于 warp 有 32 个 lanes,每个lane可以容纳一个线程(包括指令流,上下文,寄存器与内存状态),对应 lane 会提供 ALU,寄存器等。
- 存储器:包括寄存器、cache以及对应的内存。
对应地,block 也是一个软件概念:由于 block 相当于任务(包括其逻辑与指令),其执行器是 SM,也即:硬件端 SM 的资源限定了 block 的任务能用多少资源。则 block 在进行设计时,需要考虑 SM 能给多少寄存器、thread lane:
- thread 的软件概念就是 a stream of tasks, 硬件实现就是一个工人。warp 就是这32个工人的小车间,SP 会提示这32个工人要做什么(通常,都只需要广播,因为大家做的事情都一致)。block 就是某个对应订单(block 打包的所有 thread 对应的人物)的大车间,大车间内只有有限个工人(thread 限制),有限的袋子(寄存器)以及有限大小的大箱子(共享内存),以及一个超大,但是超慢(当然,工人们要走过去)的工厂库房(global memory)
- 当一个任务过大时(一个大车间干不完),那么就划分成多个
block(多个大车间一起):同时要保证划分合理:
- 一个车间工人过多,会导致袋子不够用(寄存器,比如出现寄存器 spilling 问题,工人 A 的袋子不够用了,就只能先往工厂库房里存,之后再取出来),且也有可能根本站不下那么多工人(超过 thread 数量上限)
- 一个车间工人过少:不能极致压榨!工人 8 小时工作里面摸了四小时鱼。我开灯要钱吧?开空调要钱吧?放这么多袋子,你也用不了多少。
那么 stream 是做什么的?stream 是个软件概念,CUDA 中描述的是执行任务的机制。还是太抽象了,stream 描述的内容本身就不是一个 kernel call 了,而是多个存在依赖关系的 kernel call。如果两个 kernel call 本身不存在依赖关系,则可以直接并行,由 GPU 调度:直接调用完 A 调用 B,因为 A B 不存在依赖关系,且 kernel call 在不 synchronize 的情况下,是异步的,A 和 B 会被送到不同的 SM 同时执行(几乎,可能A稍微快一点,毕竟A先被call)。而存在数据依赖就不能这样,我们必须老老实实:A结束,GPU 层级的 synchronize,之后调用 B,synchronize,... 直到所有顺序化的工作完成。而这样实际上是不太好的:会出现短板效应。
- A kernel call 完成并且 synchronize 取决于 A 最慢的执行单元花了多长时间执行。直到所有执行完毕,才能继续。
stream 所提供的好处就在于:我可以把大的任务划分为小份,小份任务内部是自动串行自动同步的,而小份任务之间可以并行,任务之间又不存在依赖关系。实际上可以用这样的图表示:
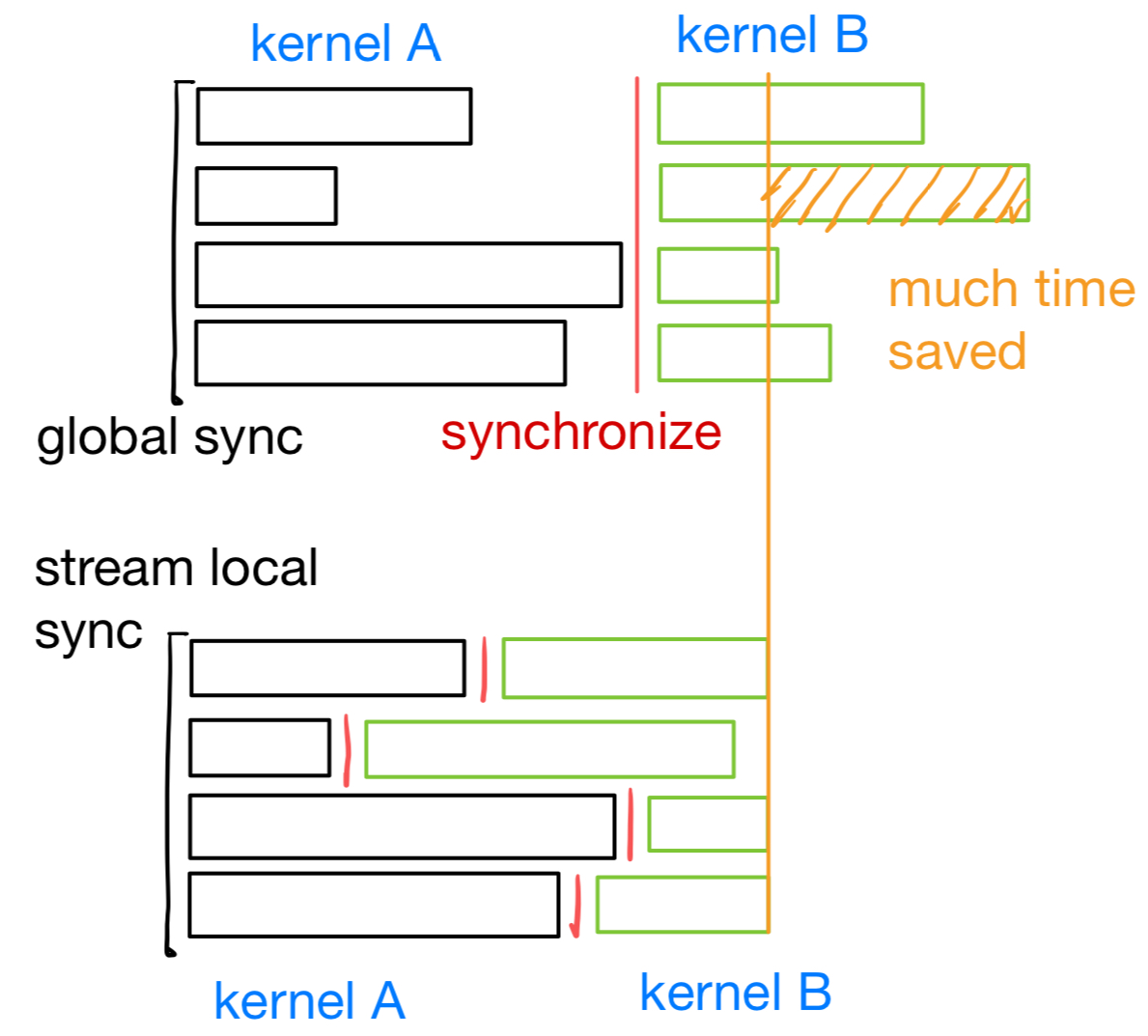
可以看到,这种情况还是节省了很多时间的,因为不同 kernel 对应的短板不一定是一起出现的。
感觉今天算是完全理解了 stream 这个简单的概念:
stream 适合用在具有依赖关系的任务上。不具有依赖关系的可并行任务,当 kernel 被调用时,我们可以手动将其映射到不同的 stream 上,以实现多个 kernel call 的同时执行。千万注意,不是同时调用:
A 与 B 之间,不管有没有 synchronize,只要 A 和 B 在同一个 stream(包括默认的 default stream),A 和 B 执行就会顺序化。synchronize 只会让 B 在 A 执行完成之后调用。看下图:
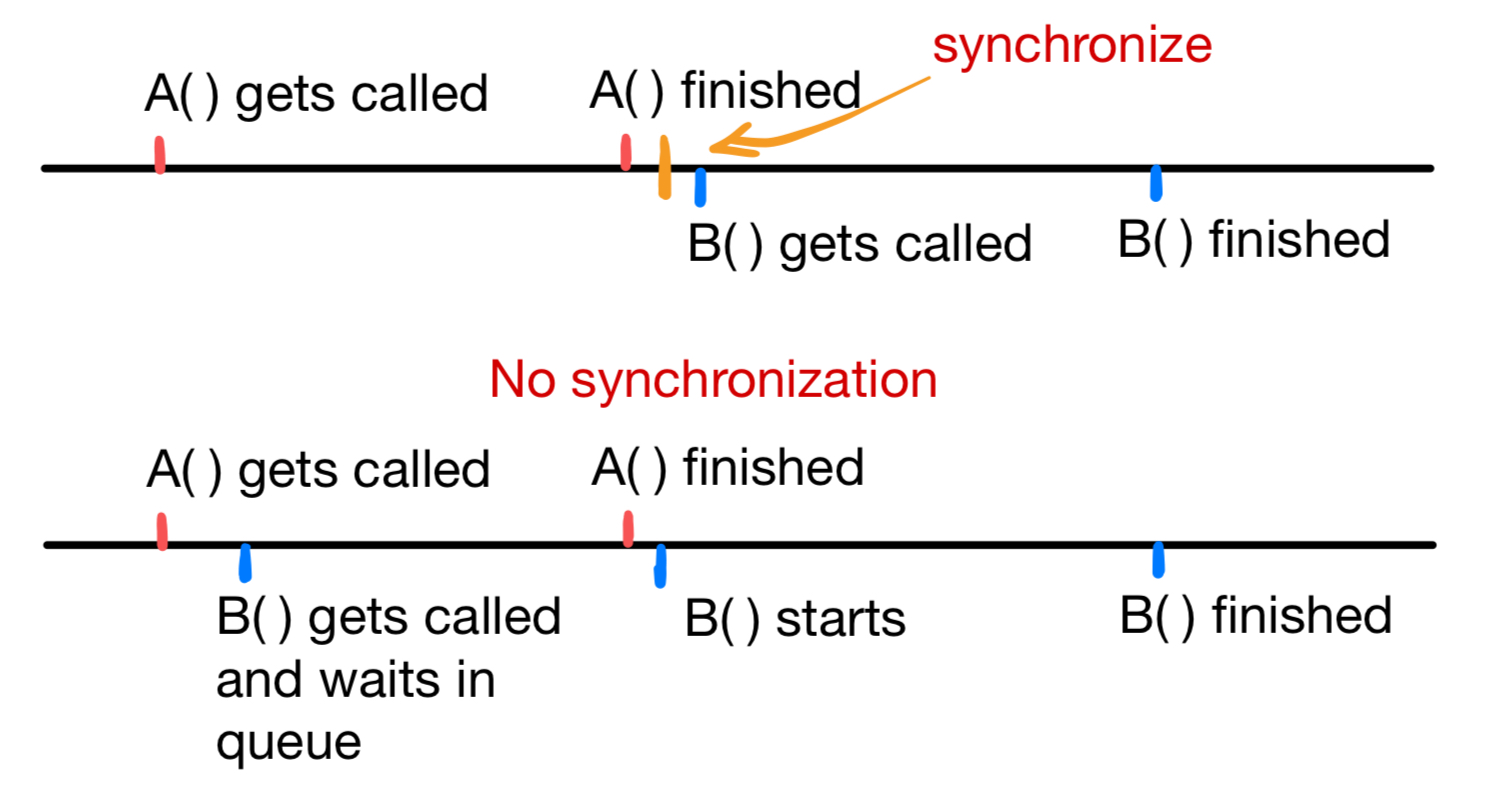
Figure 1.2 synchronization
所以,要让两个函数并行调用很简单:别同步就行。但要并行执行,需要至少在不同 stream 上(相当于不同的 task queue 上),为什么说至少?软件可以开很多 queue,硬件够不够是另一回事。
此部分和 Hyper-Q 有一定关系,可以联系起来说。
单个 kernel 就别划分为 streams 了,没必要,控制好 block 数量就行。别瞎 jb 加花,我研一上学期写的 CUDA 就有这种傻逼操作:
1 | for (int i = 0; i < 8; i++) { |
你说你一个 kernel 分啥 stream 啊,还多次调用。而我大三写的 CUDA 却没有(虽然不是多个 kernel,是 GPU + CPU 代码,也算拆分成不同块,并行执行了)。所以我感觉我写 CUDA 这么久,到现在就没有真正是用过 stream。所以回到打比方上,stream 是什么呢?
单 stream:大家都做完同一个工作,再进入下一个工作。理所当然地,有些小车间快一些,就会停下来不做事。
多 stream: 给车间分组,只要整个组做完了,就可以整组进行下一个工作。
-
没有 hyper-Q 时,同一个 kernel,即便 stream 不同也是不能并行的。因为没有 hyper-Q 时只会有一个 hardware queue。同一个 kernel 的不同 calls,放在不同的 stream 内,也会压到同一个 FIFO 结构中。
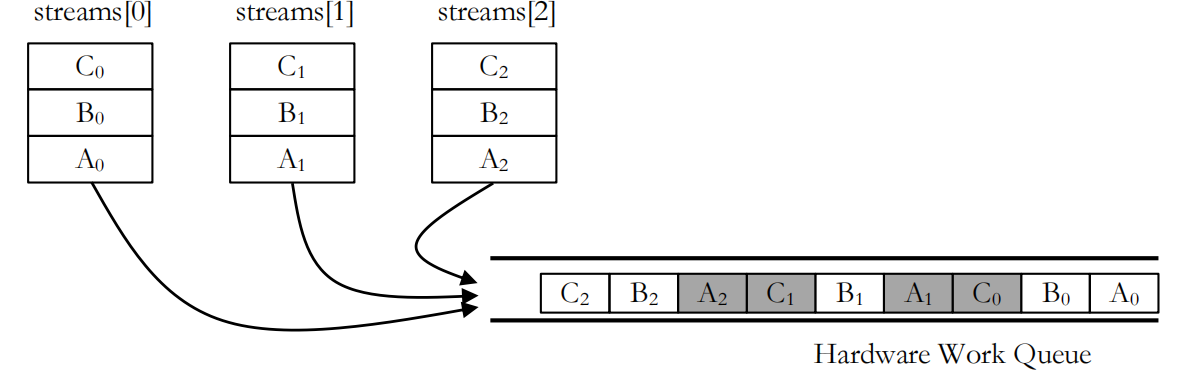
Figure 1.3 false dependency (来自CUDA官方一个讲Hyper-Q的文档)
执行顺序是从右往左。注意 kernel 的启动顺序刚好与执行顺序一致(FIFO):
1
2
3
4
5for (int i = 0 ; i < 3 ; i++) {
A<<<gdim,bdim,smem,streams[i]>>>();
B<<<gdim,bdim,smem,streams[i]>>>();
C<<<gdim,bdim,smem,streams[i]>>>();
}由于 B 依赖 A,C 依赖 B,所以AB不能并行,BC不能并行,C和另一个stream的A可以并行。最后会形成这一效果:
无 Hyper-Q:长流水线。这是因为 A 与 B 不能并行,只有 B 被 call 时,才会查看队列中是否有可以同时 launch 的 kernel。

Figure 1.4 false dependency (来自CUDA官方一个讲Hyper-Q的文档)
有Hyper-Q:
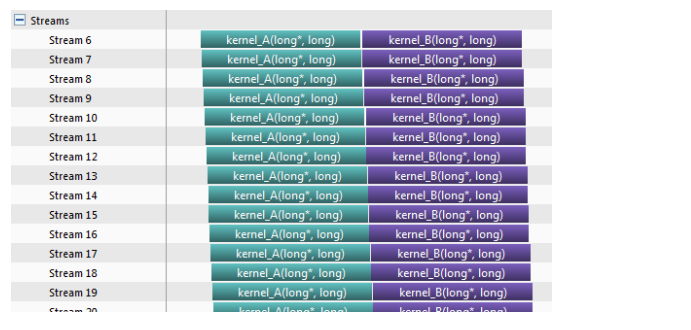
Figure 1.5 no false dependency (来自CUDA官方一个讲Hyper-Q的文档)
理解 Hyper-Q 的关键是任务输入队列的模式(FIFO),A1, B1, A2, B2 是输入顺序。A1 如果和 B1 存在数据依赖,那么 B1 的 kernel call 一定在 A1 完成后才进行。B1 kernel call 之后,由于不存在依赖,可以直接开始尝试 call 下一个 kernel,这时 A2 才能被调用执行。
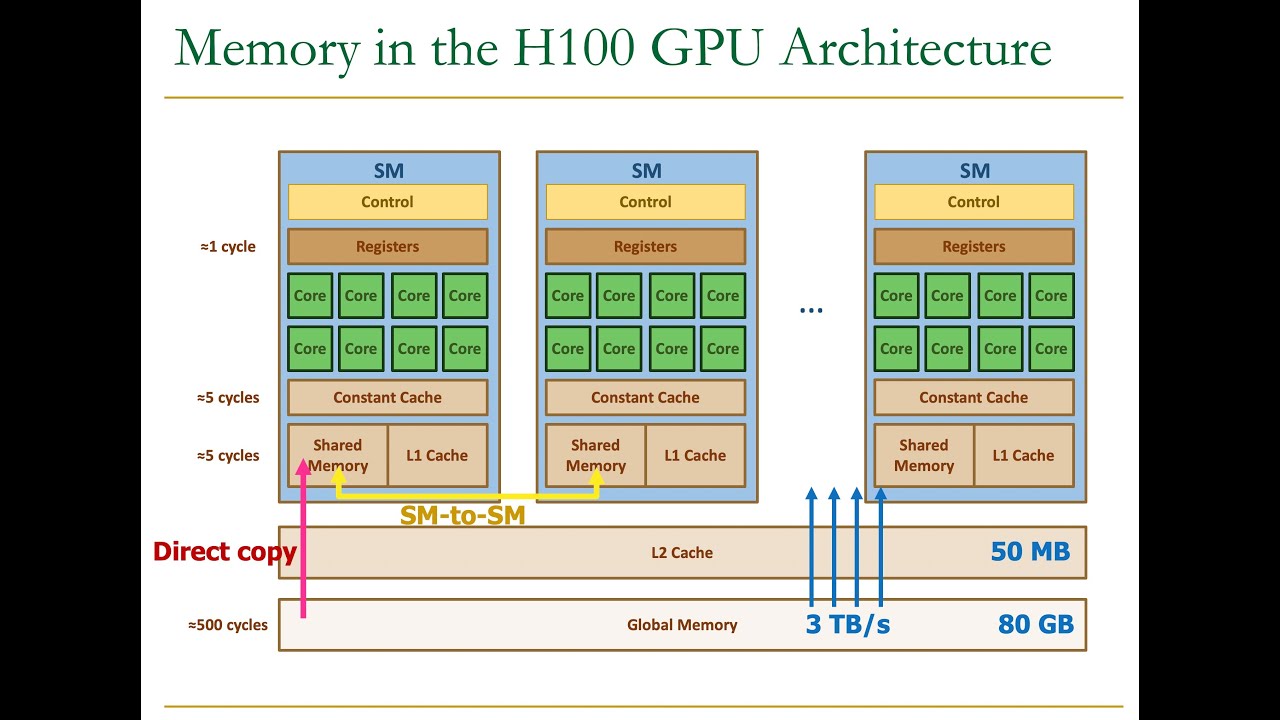
重点说一下不常见的以及一些 memory copy 机制:
L1 cache:首先,修正一个误区,register spilling 会首先与 L1 cache 有关(不会一溢出就往很慢的 gmem 里存)。注意,L1 与 shared memory 是在同一物理区域的(设计与电路都是一样的),我们动态设置的 shared memory 实际上就是从 L1 中抽取了部分可用空间。1
Constant cache: read-only cache,read only 的大块区域会被放在这里。但是... 为什么是 per SM 的?
Constant Caches - are special caches pertaining to variables declared as read-only constants in global memory
- 说是 global memory,怎么跑到 SM 里面去了?难道别的 SM(block)不可见?明白了... 要用 cache 去理解。cache 存在的意义就是为了加速更满的memory 的存取。L1 的存在是为了和 global memory(以及其上的 L2)打交道,也存在命中,写回等操作。而 CUDA 的 constant memory 是基于 global memory 同样的 DRAM 存储实现的(相当于,DRAM 有一块专门存 constant memory)。所以 constant memory 也比较慢,需要一个 constant cache 来专门加速与 constant memory gmem 的数据交互。当 SM 的所有线程都访问同一个gmem 地址时,对于 constant cache 最友好,因为此处被取到 constant cache 之后,就可以不断被其他线程快速读取重用(broadcast)。
L2 cache:L2 已经是 SM 外的 cache 了,是存储多个 SM 中,需要来回在 local shared memory 以及 global memory 中交互的数据。
Texture and constant memory:都是 read-only。但 texture memory 是 cache 在 L1 里的,只有 constant memory 是 cache 在 constant cache 里的。所以,为什么 constant memory 稍微快一些?(1)有 broadcast 机制(而且一般都可以用,常量嘛,很多情况下都是全局的)(2) 有单独的 cache,不用和别人抢,所以 cache miss 更少。
- 注意 texture memory 与 CUDA 的 texture object 没有直接的联系(后者有硬件支持的bilerp)。
注意 CPU 甚至还有 L3 cache... 牛逼。
关于更多 GPU model 介绍,可以看这个 [^2]
1.3 CPU/GPU 加速技巧
| GPU 概念 | 定义 | CPU 等价概念 |
|---|---|---|
| thread | thread 是软件概念,别忘了:分配给一个 CUDA core 的指令流与数据。相同的指令作用于很多线程(SIMT) | N/A,惊讶不? |
| CUDA core | CUDA core 是硬件概念:执行 SIMT 指令流以及数据的基本单元。 | vector lane(SIMD 指令中的向化概念) |
| warp | SM 执行并行任务的基本单元:相同指令,作用在不同数据上(小车间)。 | vector(SIMD 指令中的向化概念) |
| kernel | 需要并行处理的任务(所有任务的集合) | thread(s):软件概念,一个任务可以分配到很多 threads 上,与 kernel 一样。 |
| SM, streaming multiprocessor | 核心处理单元,处理 block 的单元。 | core |
三类原语:
数据交换:最常用的是
__shfl_xxx_sync(shuffle)类,剩下的还有一些很有趣的,比如 warp vote function:__all_sync(相当于在warp 之内做一个 bool 类型的 reduce,如果有一个 thread 是 false,那么所有__all_sync都会返回 false),同样还有__any_sync(任一则1),还有__uni_sync(唯一则1),需要说的,没那么 straightforward 的是:__ballot_sync,这个相当于是:提供了一种统计方法,对于给定的线程(warp内),只要其条件成立(predicate = true),就会把结果对应的那一位设成1(32位int),相当于:多少predicate为真就多少位。则用 __popc 可以计算 32位 int 中有多少为 1。unsigned int __match_any_sync(unsigned mask, T value);: 给定一个 value,返回线程符合 mask,并且对应 value 等于当前输入的 value 的线程id(以mask形式返回)。unsigned int __match_all_sync(unsigned mask, T value, int *pred);这个比 match any 复杂一些:如果所有 value(mask线程)都一致,返回对应的 mask(... 不就是输入的 mask吗)且设置 pred = 1,否则返回0 且设置 pred = 0... 感觉没啥用的函数。
__activemask,就这么一个原语。此原语会返回当前(时刻,调用发生时)有多少线程是 active 的(有些可能因为 branching 什么的非 active)。这个原语用来做什么... 我一开始以为只返回有多少线程是 active(数),但实际返回的是一个 mask:哪一位是1,对应的线程就是 active 的。这就很有用了,我可以使用这个 mask,在仅 active 的线程之间传输数据。__syncwarp:每个 warp 在这里会进行一次同步(为什么要这样?),何时需要 warp 级别的同步?warp 级别的同步一定是做了非同步的 warp 操作才需要吧。注意,__syncwarp接受一个 mask:代表我可以只同步某几个线程,比如:- 我们已知
__syncthreads不能写在条件语句内,因为 predicate 只要为 false,对应线程永远无法到达__syncthreads,产生死锁。、 - 而有了
__syncwarp,我们可以指定:在 if 内,先调用__activemask,对对应线程同步。else 内再先__activemask,之后同步。
- 我们已知
我TM看了 CUDA-C-programming guide 的 API 文档才知道,warp reduce 根本不用自己用
__shfl_xor_sync写,有对应的 reduce 函数:1
2
3
4
5
6
7
8
9
10
11
12// add/min/max
unsigned __reduce_add_sync(unsigned mask, unsigned value);
unsigned __reduce_min_sync(unsigned mask, unsigned value);
unsigned __reduce_max_sync(unsigned mask, unsigned value);
int __reduce_add_sync(unsigned mask, int value);
int __reduce_min_sync(unsigned mask, int value);
int __reduce_max_sync(unsigned mask, int value);
// and/or/xor
unsigned __reduce_and_sync(unsigned mask, unsigned value);
unsigned __reduce_or_sync(unsigned mask, unsigned value);
unsigned __reduce_xor_sync(unsigned mask, unsigned value);- 不过注意,是 int 和 uint。float 还得自定义(int/uint感觉范围并不广,在一般的科学计算里比例较小吧)
warp 操作很多,甚至有 warp matrix multiplication(
mma_sync)以及一大堆 warp 矩阵操作4
这里只做一个记录。对面试没有什么太大帮助,毕竟面试官估计不会考这么细:
- 你知道 CUDA 可以写一些帮助编译器优化的原语吗?比如:
void * __builtin_assume_aligned (const void *exp, size_t align)告诉编译器,对应的 pointer 至少有align个对齐的字节。对齐:起始地址是某个值的倍数,比如 4, 8 等等。 对于对齐的数据,访问可以更快(显然,比如一个float,如果其高8位在对齐float的第八位上,而后低24位在第二个对齐float的高24位上,相当于 float 被从第一个 Byte 处切断了,float 数组的起始地址是 第三个 Byte)。一般来说,我们会希望:64位数据类型对齐到 8 的倍数上,也即起始位置是 8 * k 个 Byte 处,32 位则对齐到第 4 * k Byte。这个原语可以让编译器认为某处就是对齐的,直接按对齐的走。void __builtin_assume(bool exp),通过 exp 告诉编译器,与 exp 相关的表达式肯定成立,你信我,直接按照这个先验来优化。比如我们告诉编译器,某个索引不会超过某个值,编译器就会尝试去根据这个已知信息优化。long __builtin_expect (long exp, long c),比较离谱... 写在 if 语句里帮助分支预测(???离谱)的。相当于:我有一个条件判断:比如if (i > 0)这样的,我可以告诉编译器,啊 i > 0 大多数时候都成立,你按 i > 0 去预测最保险。
直接说的话是很虚的:
CPU 端,使用线程池(手写)或者 OpenMP 来管理任务。将任务划分成一个个包进行自动调度。尽量避免手动调用
std::thread,用std::async可能都比直接std::thread优雅。线程池可以高效利用并行资源(内部一般包含一个队列,一个 mutex 和一个 condition variable,实现 enqueue 和 pop 两个函数即可,通过模板化技术以及函数指针(或者是函数对象)可以实现非常灵活的任务执行器)。- 例子1:渲染器使用的就是线程池的实现。是这样处理的:首先将需要渲染的 images 划分为 tiles,一个 tile 内可能有 16 * 16 或者 8 * 8 个像素。每个像素都需要进行 path tracing (计算光线在场景的弹射,并且累积 radiance contribution),则可以启动一个线程池,每次提交的任务就是像素渲染:只给定像素坐标,场景、光源等信息在一个全局区域,所有线程可见(或者提供引用或指针),此外提供一个渲染函数(用lambda 打包的),输入除了像素坐标之外还有一些辅助信息,并且按引用捕获 RGB buffer。每个线程负责从给定像素 trace SPP 条 paths,累积值到 RGB buffer 对应位置。尽管进行了 tiling,光追的算法逻辑决定了不同线程之间的负载必定有比较大的差异,所以用任务队列来管理,避免手动同步(如 join)带来的overhead 以及不灵活的问题。
- 例子2:本科时做过的几件事情。(1)Robomaster 大二开发基于优化的灯条2D位姿优化,计算误差的时候就可以 OpenMP reduction。(2)大三大四写的激光雷达仿真器也是直接 OpenMP 对 for 循环并行的。
CPU 端,尽可能使用 SIMD 操作(一次读取多个多字节数据,比如 4-8 个 float,这算是一种 burst mode?burst mode 描述的不是这个)。SIMD 的作用不用多说。
- 本人论文的 DA-based distance sampling,做 RIS 时,由于 DA 的计算是 compute bound 的,我用 AVX2 指令加速了一下(快速向量exp,向量乘加以及存取)。
CPU/GPU 端:尽量使用无锁数据结构。pthread 库以及 windows 线程库在操作 mutex 结构(加锁,解锁都是系统调用)时都会进入内核态,进入内核态这个操作可能带来巨大的延迟。有些库,比如 TBB 确实提供一些别的方法,比如自旋锁(spin lock),自旋锁就是那种一直轮询状态的锁,虽然不用进入内核态,但会引入 CPU 占用的问题(开几个空转的 while (1) {} 试试,相当于 CPU 时间片全部花在在这里转了,如果里面有
std::this_thread::sleep,时间片还能被让出去)。所以,能避免锁的地方,最好避免锁。比如用原子操作,CUDA 和 C++ atomic 是有硬件支持的,所以不用锁实现。Taichi lang 估计也不用使用锁,毕竟都有硬件支持。- 原子操作:研究生阶段用得很少,基本上会尝试避免原子操作。CPU
端的例子基本没有了(我项目里很少用
std::atomic,机器人队里的需求有一点,但都是边缘化的),GPU 端的例子挺多的:- flash attention 的实现(我自己的实现版本),使用 atomicAdd accumulate softmax 的分母。
- GPU z-buffer:不同 block 将对应的深度图片段(可能重合)进行合并时,用 atomicMin 求深度图每个位置的最小值。
- 原子操作:研究生阶段用得很少,基本上会尝试避免原子操作。CPU
端的例子基本没有了(我项目里很少用
访存优化。这我不多说了,访存优化对是否并行都很重要。访存优化对于 GPU 性能提升尤其重要:控制 cache 行为,利用多级、不同速度的存储这件事,CPU 端没有给那么灵活的操作方式,而 GPU 提供了:shared memory, thread local memory (register), constant memory, global memory 这些,如何将数据复用部分的访存优化到极致,是 GPU 访存优化的重点。
尽可能解除数据依赖性(说了等于白说...?怎么解除)
1 | void sgemm_kernel<(int)128, (int)128, (int)8, (int)8>(float *, float *, float *, float, float, int, int, int) |
首先介绍这个概念:GPU Speed Of Light Throughput,指的是理论极限(speed of light 指速度上限,很生动吧,速度的物理极限是光速)。可以看出,我们这个 kernel 花在计算的时间上只有 22.37%,而 memory 占比(显存访问)为 43.74%(比较低),访存问题还是很大的。所以,GPU 才会说:" This kernel exhibits low compute throughput and memory bandwidth utilization"。compute 占比低,看了一下我写的 NCU profile 矩阵向量乘法,结果发现 compute 占比还是很低(22.39%),可能是正常的,说明这个任务本身就是 memory bound。
(SGEMM) This kernel's theoretical occupancy (25.0%) is limited by the number of required registers See the CUDA Best Practices Guide。
SGEMM 有一个较大的 local 数组(8 * 8),但好像也不至于用了特别多的 register?我看到 Registers Per Thread 都 253 ...,这么离谱?SGEMV (矩阵向量相乘) 竟然只用了 18 个resgister,所以一个 block 里的活动 warp 可以很多...
所以总结一下,可以先看这么一些内容:
DRAM Throughput:小于 60% 时访存都有一定问题
L1/L2 cache throughput: 过小说明 cache miss 比较严重,看看内存访问 pattern 是不是比较没有规律。
Occupancy 部分:theoretical occupancy 与 achieved occupancy。
SGEMM 例子中,occupancy (theoretical) 受到了 register 数量的影响。但我们如果想通过减少一些 local 变量(比如,去掉几个 int xxx 之类的)就减少 register 使用,是不太可能的(naive)。register 使用量将会受到指令数量影响:register 会被隐式地用于保存一些计算的中间结果,越是复杂的代码,使用到的 register 就越多。比如:
1
gmem_addr = gmem_base_b + ((kid << 3) + tile_r) * n + tile_c;
你说上面这段用了多少寄存器?不只是有名字的变量如
gmem_addr,tile_c之类的,中间结果通常需要被保存(一些右值)。我们如果想要限制 register 用量,手动调整一般不好,因为这都是编译器设定好的,编译器没有那么笨。控制编译器数量意味着有些中间结果无法被存下来,需要重算,则反向增加了指令数量(时间开销)。这也是一种 trade-off 吧。
矩阵相乘是有大量数据复用的。在优化矩阵相乘时,一般通过分块的方法(tiling),分块相乘后相加即可。一般在 GPU 的实现中,对于大矩阵相乘(\(A\times B\)):
- Thread coarsening: 一个 thread 可能需要同时处理输出矩阵的多个位置(比如 8 * 8)。我们以 8 * 8 为例:
- 一个block 处理一个大块:比如 128 * 128(输出),每个线程 8 * 8 则对应 16 * 16 = 256 线程
- 输入:由于输出的某一块,是A的某几行(与块行数一致)与 B 的某几列(与输出块列一致)相乘获得,除非中间维度特别小,一般来说我们在 thread 内部用循环将中间维度拆分为多个块。比如最终为 128 * 8 大小的块(从 A 中取出),以及 8 * 128 的块(从 B 中取出)。本例子中,由于有 256 个线程,我们可以每个线程负责复制 A 块的 4个值以及 B 块的四个值(FLOAT4 优化)
- 块存在 shared_memory 中(因为块还是比较大的)。每个线程计算的结果存在local 数组中(register)。
对于矩阵和向量相乘,注意使用 warp reduce 就行... 之前是用 shuffle 手写,现在 int 可以直接 reduce 了。
矩阵相加(element-wise)操作:注意,element-wise 操作一般是不会涉及到数据复用的。所以优化空间其实不算大,一般就是:(1)thread coarsening (2) 在 thread coarsening 的基础上,连续传输(FLOAT4)(3) coalesed memory access(非常重要)。
矩阵转置:CPU 明显是可以分块去做的,但 GPU 为什么要分块?为了提高缓存一致性:GPU 也是有 cache 的。我自己写了 CPU 和 GPU 分块/不分块的实现,见(1024 * 1024 float 矩阵转置) transpose.cu。如果从 CPU 计时看,差不太多(大概 10-20% 速度提升),但是从 NCU profiler 的结果看,GPU 分块的实现只需要大概一半的 cycles 数就能完成。CPU 端的话,一般分块是 7ms,不分块是 10ms,提升也挺明显的。
cache 每一个 cache line 包含 3 个部分, 分别是什么作用?与 cache 的实现相关,回忆一下计组:
- tag(标签):cache 肯定需要保存对应数据在主存中的地址,tag 中一部分重要内容就是主存地址(毕竟需要写回之类的)。访问 cache 时,第一步就是与缓存中所有标签对比,以确定是否命中缓存。
- data(数据):必不可少,缓存存的就是数据。若判定缓存命中,就可以直接从数据项中取出对应结果。
- valid bit(有效位):用于确定当前 cacheline
数据是否有效。数据如果过期了,可能会设置为无效,即使命中,也需要去下一级存储中查找。以下常见情况,有效位会被设置为
invalid:
- 缓存未被初始化时(刚上电)
- 主存被修改(比如别的核心修改了主存对应位置)
- 缓存替换(缓存满了,需要装入新数据时)
cache查找一般来说就是三步:
- 地址解析:CPU 发出查找请求后一般会给一个访问地址。访问地址是三部分组成的:标签 + 组地址 + 偏移量。什么意思呢?标签包含了主存地址等其他控制信息,而组地址与偏移量则完全与 cache 查找相关:cacheline 是分组的,相当于我们首先需要知道在哪个组查找,组内哪个位置,组的起始地址。
- 缓存lookup:已经确定了对应的 cacheline 了,就需要确定对应 cacheline 是否就是我们需要查找的内容:比较标签。如果不匹配,则发生 cache miss,进入处理 cache miss 的操作。
- 数据检索(retrieval):如果命中,并且标志位也是有效的,则取对应数据返回。
我们首先说一下 cache miss:cache miss 发生的条件很多,比如地址解析失败,缓存lookup 不匹配(对不上,或者 invalid),这里说一下最为 prevalent 的一些预防方案:
- prefetch 机制(防止 cache miss或者降低 cache miss 率):prefetch 对于冷启动很有效(所有缓存行都无效),对于分散但体量较大的访问(需要经常切换访问位置,但切换后的开始几次访问可能数据量大且连续)也是有好处的。预加载到 cache 中。
- 缓存行替换(防止 cache miss或者降低 cache miss 率):比如 LRU,LFU,替换缓存中最近最少或者最近最不频繁使用的项目。
- padding(降低 cache miss 率):不进行 padding 时可能多个地址映射到同一个 cacheline,导致对应地址总是发生修改,cache miss 总是发生。如果可以选择合适的 padding,使得 cache 地址可错开,则可以降低 cache 换出的频率。
那么 cache miss 之后一般是什么流程?
(1)内存读请求首先发送到最近的 cache(L1),如果L1没有命中,则继续往下发(L2,L3)。
(2)如果继续下去仍然是 cache miss,读请求最终会来到主存
(3)主存接到请求会直接根据地址去查找,查找之后数据会返回到内存控制器
(4)各级缓存需要被更新:写回操作,更新对应项(可能一整个缓存行都会被覆盖)。如果 CPU 请求是一个缓存行,那么直接返回写回后的缓存行
(5)数据返回到 CPU:CPU 取用计算
多级cache的使用原因:
- cache(SRAM)的成本比较高,考虑成本时,越快的 SRAM 越小。而越小的 SRAM 越容易 cache miss,cache miss 之后被迫到慢速的内存中取数据。为了提高 cache 命中的概率,降低内存访问时间的期望:
\[ E(T) = p_1 T_1 + (1 - p_1)p_2T_2 + (1 - p_1)(1 - p_2)p_3 T_3 + p_m\prod_{i=1}^3(1 - p_i)T_m \]
首先需要回顾虚拟内存这个概念。一句话概括就是:虚拟内存使用了外存以扩大可表示的内存范围,通过 swap 机制实现了缺页中断时的内存访问请求。
- 一般来说,分页机制会将每个进程的虚拟内存地址划分为多个页(通常4KB,取决于操作系统),对应的物理地址会划分为一个个页框,一般来说,页框和页大小是一样的。
- 之后,维护一个页表,用于虚拟地址到实际地址的映射。
干巴巴的,不好理解,来看一个例子吧。
1 | 虚拟页号 物理页框号 |
每个页框对应的才是真正的物理地址。这个页表首先将虚拟地址映射到物理地址,映射的过程中,如果出现了缺页:也即页表中并没有对应的虚拟地址,这时会引发一个异常(page fault),之后立刻对这个异常进行处理:
- 到外存或者其他存储介质中调取对应的页
- 更新页表,建立缺页的虚拟地址到实际地址的映射
- 重新执行缺页的指令,使得程序可以正常执行
所以虚拟内存为什么可以更大?假设我们的物理地址是 32 位的,虚拟地址也是 32 位的,那么按道理来说,由于一页大小为 4KB,也即一个虚拟地址可跨 12 位地址(\(2^{12}\)),则可以对应 16 TB 虚拟内存?并不是这个意思。虚拟地址被拆分为了两部分:(1) 页地址(2)页内 offset。比如 32位 地址,低12位是页内地址(没有页内地址怎么随机访问啊,傻)。所以 32 位实际能表示的地址大小仍然是 \(2^{32}\) = 4GB 的范围。那么实际是怎么使用的呢?
- 每个进程有一个页表(映射表),就以32位地址为例。这个页表决定了此进程最多可以被分配到 4GB 内存。但注意,页表中 目前 可能只有几页,比如,1024页:那也才 4MB 啊,假设此时,此进程需要调取某个为 X 的虚拟地址,一查页表发现缺页了:立刻触发缺页中断,只到取到对应的页,再重新执行。取到对应的页的过程可能涉及到实际物理内存的换入换出:另一个进程的某块闲置内存被换出到外存上,转而换入本进程 request 的内存。这样,本进程可以“无缝”(几乎吧,缺页中断也还是比较快的,如果缺页的频率比较低)使用对应内存。那么,假设一个物理内存只有 4GB 的设备,上面运行了 4 个进程:我可以用虚拟内存技术,每个进程都分配 4GB 虚拟内存,之后就靠缺页中断不停换入换出。
所以好处很显然:可以摆脱物理内存的限制,利用外存或者其他设备获得更大的可用内存。开销:虚拟内存的访问实际上是两步:(1)假设不考虑 cache,那么我第一步要去主存先查一波页表,本地完成内存映射之后,还需要再去主存取真正的数据,从访存方面可见已经两倍了(2)假设发生缺页中断,这就更慢了,外存和内存之间通信,即便有 DMA,速度还会比内存通信慢。
解决方案:TLB(translation lookaside buffer,转译后备缓冲区,或称页表缓存),如果某个虚拟地址存在于 TLB 中,我们就不用去主存查页表,可以直接从 TLB 中取出映射后的实际物理地址,通过对应物理地址直接去取页,这样也很快。另外,如果页表太大了,则也可以设置多级页表,虽然会降低访问的速度(多次映射),但是可以避免由于内存碎片化而导致的无法分配的问题。
讲到分页,我这里还有两个需要讲的:
- 分段:简单理解就是:段是变长的页。页大小一般固定,但段可变,所以段表不仅需要基地址以及映射方式,还需要长度这一信息。
- CUDA 与分页机制最有关的是 pinned memory
(
cudaMallocHost),此部分内存分配后,页即被锁定(不用担心被换出),消除了缺页中断的可能。另一方面,这部分内存与GPU交互时是不需要走 PCIe 总线的,DMA 可以直接让 GPU 设备访问对应主存区(厉害啊)。走 PCIe 总线的基本都是 CPU 参与的传输(因为CPU要发出读写请求)。
GPU 内存层级架构 - Cornell Virtual Workshop: https://cvw.cac.cornell.edu/gpu-architecture/gpu-memory/memory_types [^ 2]: https://cvw.cac.cornell.edu/gpu-architecture↩︎
https://cvw.cac.cornell.edu/gpu-architecture/gpu-characteristics/threadcore↩︎
https://developer.nvidia.com/blog/using-cuda-warp-level-primitives/↩︎
https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#warp-matrix-functions↩︎