GAN原理与实现
GAN 生成对抗网络
编码器原理
自动编码器
自动编码器,简单地说就是以下结构:
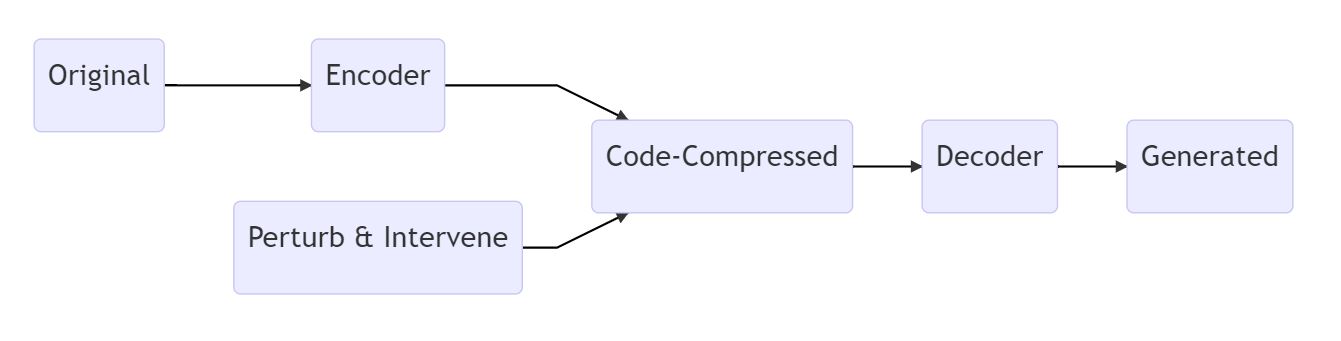
从原始输入,对其进行编码(编码过程可以使用感知机(前馈,无BP操作)或者神经网络(现在的架构一般是BP式的优化)),生成 压缩后的编码数据。再想办法从编码中(必然存在信息损失)恢复原来的图片。但是一般而言,自动编码器(AE)都是确定输入输出的,每一种编码会由训练得到唯一的输出。
我们希望生成更多的数据或者达到人工智能创作 / 想象的目的,需要随机的输出。我们希望可以加入编码的扰动(Perturbance)或者人工的干预(Intervention),让编码更加多样化 / 随机化,而且Decoder可以对这种加入的噪声鲁棒。这就得到了VAE(Variational Auto Encoder)变分自动编码器。
变分自动编码器
一个想法:首先一个随机的编码器在数学上的表现应该是给定一个向量(比如编码)Z,从Z中恢复X(训练集的分布)。那么就是从\(P_Z(x)\)到\(P_X(x)\)的映射(编码分布空间到样本空间的映射),得到新的分布\(P_{\hat X}(x)\)。那么根据贝叶斯的想法,可以表示分布\(P_X(x)\)为: \[ \begin{equation} P_X(x)=\sum_kP(X|Z_k)P(Z_k)\label{YY} \end{equation} \] 意思是:不同编码的分布 与 给定编码下,输出数据为对应类型X 两者的条件概率结合。那么数据生成和分布之间的关系又是什么呢?直观地理解一下:
世界上有几乎无数种猫,猫产生的后代也不是和其父母一致的。那么我们如果想从数据层面【生成猫】,应该首先知道 不同表现型的猫的【总体分布】,如果知道这个分布,显然只需要从这个分布中随机采样就可以得到任意新性状的猫。但是这个分布基本是不可知的,即使存在海量数据我们也没办法得到这个分布的表达式。所以我们希望通过别的方式来近似表达这个分布,比如使用式(1)。
假设Z不是编码而是不同的形状,那么可以建立一个性状以及含有对应组合表现型的猫的概率映射,通过贝叶斯全概率公式获得。而把Z换为编码(更加抽象的形状表示),也是一样的,编码存在分布(正如不同性状如黑白存在一定分布),而给定编码(给定形状)时也存在其他的分布(Z=公猫,公猫中的白猫 / 花猫分布等等)。
VAE中,\(P(Z)\)被建模成了标准正态分布(其他分布也可),原因有以下两点:
- 标准正态分布常见,并且方便进行熵计算(或者说,KL散度计算时不会出现问题(比如均匀分布会存在概率密度为0导致奇异性的现象))
- 天然的exp性质,并且表示容易,只需要对\(\mu,\sigma\)进行建模表示即可。
GAN原理
- GAN需要构建一个生成器和一个判别器,生成器需要生成能够以假乱真的数据。生成出的数据需要输入到判别器中,由判别器进行判定:此数据是真的(非生成的)还是假的(生成的)。固定判别器的参数,训练生成器参数,使得生成器生成的结果输入到判别器中,二分类(真假判定)得到结果尽可能接近1.
- 判别器的训练:我们希望我们的判别网络尽可能强大,能够区分真假数据,这样再进行生成器训练时,生成器训练会有更加严格的监督。判别器训练时,固定生成器网络参数,生成器生成的数据需要使label尽可能为false。
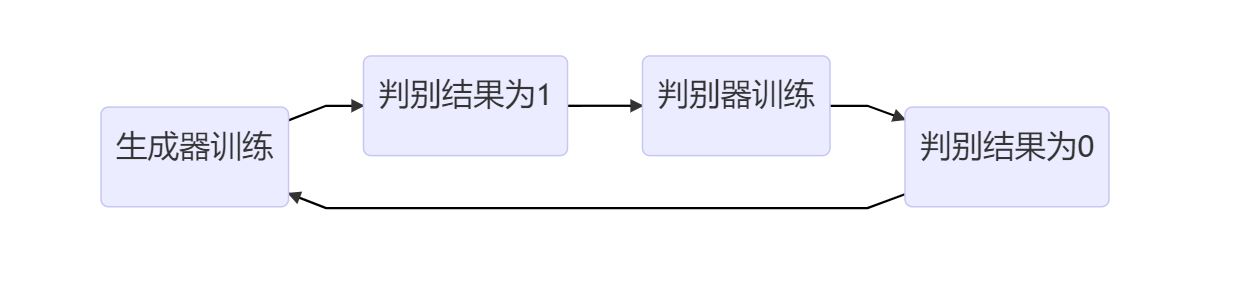
- 并且,分类器不仅能正确处理生成器生成的数据(正确地label成false类)(True Positive),还需要有处理True Negative的能力,对于真实的数据,需要正确分类为真。
GAN的数学原理
KL散度
需要回忆一下KL散度的定义,KL散度描述的是两个概率分布的相似程度,又称为相对熵。既然是“熵”,那么相对熵就与绝对熵(信息熵)存在关系。信息熵是信息不确定程度的度量。而信息量的度量是: \[ I(x_i)=-log(p(x_i)) \] 也就是说:事件发生的概率越小,若发生,携带的信息量是越大的。对于一个具有一定不确定度的信息源,一个事件\(x_i\)发生的概率若是\(P(x_i)\),那么信息熵为: \[ H(x_i)=-p(x_i)log(p(x_i)) \] 如果信息源发送的“事件”存在n个不同的取值,每个事件的概率为\(p(x_i)\),那么,信息源熵为: \[ H(U)=-\sum_{i=1}^np(x_i)log(p(x_i)) \] 可以看出,信息熵是系统信息量根据概率分布的加权,是一个系统的平均(期望)信息量。
KL散度的由来
对于一个字符集(比如26字母,需要进行不等长编码),假设每个字符X出现的概率是\(P(x)\),那么可以知道,一个字符需要编码的字节数(或者位数)会对等于信息量\(I(x)\),那么一个字符集编码的平均字节数等于信息熵\(H(U)\)。假设,这个字符集的真实概率分布为\(P(x_i)\),那么其平均编码数为 \[ H(X)=\sum_{i=1}^n p(x_i)log(\frac{1}{p(x_i)}) \] 由于,\(P(x_i)\)是字符集X的真实概率分布,对于X是最优的(对应的编码方式是最优的)。如果需要以这种编码方式对字符集Y(对应的概率分布为\(Q(x_i)\))进行编码,编码平均字节数必然是更多的(因为不是最优的),那么这种编码下存在的差异是: \[ D_{KL}(P||Q)=\sum P(x)log(\frac{1}{Q(x)}) - \sum P(x)log(\frac{1}{P(x)})=\sum P(x)\frac{P(x)}{Q(x)} \] 理解了编码的物理意义就知道,为什么是\(\frac {P(x)}{Q(x)}\)了,因为\(Q(x)\)并非最优分布,需要的编码量更大。而我们不喜欢负数,为了让KL散度为正,故这样定义。
穿插一点优化原理的知识:为什么使用交叉熵作为很多网络的损失函数?
交叉熵与KL散度的关系
交叉熵的定义: \[ H_c(x)=-\sum_{i=1}^np(x_i)log(q(x_i))=\sum P(x)log(\frac{1}{Q(x)}) \] 与KL散度的公式进行对比,可以发现: \[ D_{KL}(P||Q)=H_c(x)-\sum P(x)log(P(x)) \] 其中:\(\sum P(x)log(P(x))\)表征的是原始分布。在训练过程中(比如典型的分类器训练),\(P(x)\)一般是给定的:比如我们给定数据的原始label就是给定了一个原始分布,我们希望网络学习到的分布参数能够尽可能与原始分布接近。而由于\(\sum P(x)log(P(x))\)是常数(给定的原始分布是常的),优化交叉熵就相当于优化训练集与输出的KL散度。
GAN在优化什么
GAN的训练过程本质上就是构造一个近似的原始分布。由于我们只有原始分布的采样(比如MNIST手写数据集,是手写数字的采样),我们希望得到采样外的数据,那就需要原始分布。那么构建原始分布,可以看作是:构建一个带有参数集合\(\{\theta\}\)的分布\(P_G\),使得,从\(P_G\)中采样得到的原始分布的采样(给定的数据集)的概率尽可能大(个人理解)。
什么意思?我们认为:在极大似然的思想下,参数应该尽可能反映采样的结果,也就是给定真实分布\(P_R\)的抽样集合\(d = \{x_1, x_2, ... x_n\}\),应该使下式最大(极大似然)。 \[ \begin{align} &L(\theta)=\prod_{i=1}^n P_G(x_i|\theta) \\ &\theta^*=\mathop{argmax}_{\theta}\prod_{i=1}^n P_G(x_i|\theta) \end{align} \] 接下来我们对公式(10)进行一些数学上的变换:
- log化:由于log是严格增的,加log将不影响结果
\[ \theta^*=\mathop{argmax}_{\theta}\;log(\prod_{i=1}^n P_G(x_i|\theta))=\mathop{argmax}_{\theta}\;\sum_{i=1}^nlog(P_G(x_i|\theta)) \]
- 与真实分布进行关联:在生成器对应的生成分布近似于原始分布的情况下,生成分布下讨论最优参数\(\theta^*\)对应的似然,就等价于讨论原始分布采样得到结果概率。
\[ \theta^* \approx \mathop{argmax}_{\theta}\;S_x\{P_R|log(P_G(x|\theta))\} \]
上式的意义是:\(\sum_{i=1}^nlog(P_G(x_i|\theta))\)->中的\(x_i\)相当于从真实分布\(P_R\)中抽样得到,隐含了抽样概率(得到\(x_i\)的概率被隐含了),如果抽样次数接近无穷大,相当于对全空间进行抽样,可以连续化为: \[ \theta^*=\mathop{argmax}_{\theta}\;\int_x P_R(x)log(P_G(x|\theta))dx \]
- 转化为KL散度:实际上(13)已经有KL散度的影子了,KL散度的连续形式为:
\[ D_{KL}(P||Q)=\int_x P(x)log(\frac{P(x)}{Q(x)})dx \]
则,由于在argmax过程中引入与\(\theta\)无关的常数因子,不影响结果,那么(13)可以写为: \[ \theta^*=\mathop{argmax}_{\theta}\;\int_x P_R(x)log(P_G(x|\theta))dx-\int_x P_R(x)log(P_R(x))dx \] 与(14)对比,发现,后端需要优化的式子就是对应的KL散度: \[ \int_x P_R(x)log(P_G(x|\theta))dx-\int_x P_R(x)log(P_R(x))=\int_x P_R(x)log(\frac{P_G(x)}{P_R(x)})dx=D_{KL}(P_R||P_G) \] 也就是说:得到最优生成分布的参数\(\theta\)的过程就是在优化原始分布(未知,但是采样已知)与最优生成分布的KL散度。
生成分布的计算
那么,为什么GAN要在高斯中采样?原来的latent vector(z)又是如何一步步变到生成数据的?我们已经通过近似证明了(其中一个巧妙的思想就是:采样得到的样本隐含了其概率分布)优化GAN生成器与优化生成分布/原始分布KL散度的等价性。
在公式(16)中,存在\(P_G(x|\theta)\),这是之前从未出现过的。我们通过latent vector z(从多维高斯中采样的随机向量)构造了一个从多维高斯分布经非线性映射得到的生成分布。那么\(P_G(x|\theta)\)自然与高斯分布有关。那么\(P_G(x|\theta)\)可以被表示为:
\[ P_G(x|\theta)=\int_zP_{prior}(z)I_G(z)dz \\ I_G(z)= \left\{ \begin{array}{**lr**} 1,\;if\;G(z)=x,\\ 0,\;if\;G(z)\neq x \end{array} \right. \]
也就是说此处使用了一个类似边缘分布的求取的方法,将所有可以生成x的z找到,求取其概率。其中\(P_{prior}\)是先验分布,在此处是多维高斯。以上只是理论推导,实际上,指示函数\(I_G(z)\)是不可知的,那么使用公式(17)是无法计算\(P_G(x|\theta)\)的。此时我们引入了判别器 Discriminator,用以取代MLE的指示函数处理。
判别器与JS散度的导出
每次生成器G训练时,我们都希望,在给定的判别器D较优时,生成器G仍然能骗过D。首先,根据简单的BCELoss,我们定义需要优化的score(最大化): \[ S(G, D)=S_{x\{P_R\}}\;log(D(x))+S_{x\{P_G\}}\;log(1-D(X)) \] 上式也就是D训练时,希望能最优地区分原始数据与生成数据所定义的Score。那么采样\(S_{x\{dist\}}\)可以展开为定积分: \[ S(G,D)=\int_xP_R(x)log(D(x))dx+\int_x P_G(x) log(1-D(x))dx \] 判别器训练时,G的参数不变,原始分布参数也不变,那么公式(19)中的可变量就是D的参数。我们需要求到一个最优的D(\(D^*\))以最终求得G:也即最优判别器下对应的最优生成器。 \[ G^*=\mathop{argmin}_{G}\;\mathop{argmax}_{D}\;S(G,D) \] 可以将(19)式合并积分内式子,并且进行求导(对D): \[ \begin{align} &S_n(D)=P_R(x)log(D(x))+P_G(x) log(1-D(x))\\ let:\;&\frac{\partial S_n}{\partial D}=\frac{P_R(x)}{D}-\frac{P_G(x)}{1-D}=0 \end{align} \]
可以得到最优判别器的参数D为: \[ D(x)=\frac{P_R(x)}{P_R(x) + P_G(x)} \]
那么公式(19)的D(X)表达式已经知道了,带入得到: \[ S(G,D)=\int_x \left\{ P_R(x)log(\frac{P_R(x)}{P_R(x) + P_G(x)}) + P_G(x) log(\frac{P_G(x)}{P_R(x) + P_G(x)}) \right\} dx \]
单独讨论(24)积分内部的式子,可以发现,当我们进行如下处理后: \[ \begin{equation} \int_x P_R(x) log(\frac{P_R(x)}{\frac{P_R(x) + P_G(x)}{2}})dx + \int_x P_G(x) log(\frac{P_G(x)}{\frac{P_R(x) + P_G(x)}{2}})dx-2log2\\ =D_{KL}(P_R|{\frac{P_R(x) + P_G(x)}{2}})+D_{KL}(P_G|{\frac{P_R(x) + P_G(x)}{2}})-2log2\\ =2D_{JS}(P_R|P_G)-2log2 \end{equation} \] 我们将式(25)化简结果的部分进行定义: \[ D_{JS}(P|Q)\overset{\Delta}{=}{\frac12}D_{KL}(P|M)+{\frac12}D_{KL}(Q|M),\\ where\;\;M=\frac{P+Q}2 \] 可以看出,JS散度相比于KL散度而言,其是对称的。我们优化的是关于 {生成分布}{原始分布}的JS散度,其中借助了判别器,判别器将复杂的MLE指示函数(形式不负责,但是难算)转化为了易于计算的JS散度,以优化两个分布的差异。
原始GAN为什么难以训练
原始GAN实际在优化(25)式对应的JS散度。\(P_G\)与\(P_R\)可以互相接近(\(P_G\)通过梯度来调整)。而如果,这两个分布本身就几乎不重合(什么叫不重合?),会怎么样?
不重合的定义很简单,概率密度不为0的位置错开了(或概率密度较大的位置错开了)。那么假设\(P_G\)与\(P_R\)的关系是任意的,那么会有如下四种关系:
- \(P_G(x)\approx 0,P_R(x)>>0\)
- \(P_G(x)>> 0,P_R(x)\approx 0\)
- \(P_G(x)>> 0,P_R(x)>>0\)
- \(P_G(x)\approx 0,P_R(x)\approx 0\)
在前两种情况成立时,不重合(一个分布有值的地方,另一个分布基本上没有值)。那么在不重合情况下,我们重新看一下公式(25): \[ 2D_{JS}(P_R|P_G)=\int_xP_R(x)log(\frac{P_R(x)}{\frac{P_R(x) + P_G(x)}{2}})dx + \int_xP_G(x) log(\frac{P_G(x)}{\frac{P_R(x) + P_G(x)}{2}})dx \] 当\(P_G\)不为0的位置,\(P_R\)接近0,那么可以知道,(27)的计算结果为log2,对于第二种情况,计算结果也是log2(或与x有关,但是x的影响极其小)。可以知道,在这种情况下,需要优化的\(D_{JS}\)已经不具备指导意义了,梯度已经消失了。生成器无法得到有用的信息。
\(P_R\)与\(P_G\)不重叠或重叠部分可忽略的可能性有多大?不严谨的答案是:非常大。比较严谨的答案是:当\(P_R\)与\(P_G\)的支撑集(support)是高维空间中的低维流形(manifold)时,\(P_R\)与\(P_G\)重叠部分测度(measure)为0的概率为1。
- 其中,支撑集就是(1)函数的非零部分集合(2)概率分布的非0部分集合。
- 流形:就是高维空间中的,拥有实质更低自由度的形体。
那么可知:\(P_G\)的支撑集恰好就是高维空间中的低维流形。由于我们使用的latent vector比原图片flatten之后的大小小得多:比如196 dims的z,全连接至56 * 56 * 2 再卷积到56 * 56,\(P_G\)就是低维空间的流形。
介绍Wasserstein距离的一些数学准备
Lipschitz 条件
这个是高等数学中没有要求掌握的部分,但是在此处又提到了。
若x为有界空间\(\mathbb R^n\)中的一个向量,定义在\(\mathbb R\)上的函数\(f(x)\)有界的充分条件是:\(f(x)\)满足Lipschitz连续性条件: \[ f:D \subset \mathbb R^n\rightarrow \mathbb R,\;\exists K,\;|f(a)-f(b)|\leq K|a-b|,\; a,b \in D \] 函数值的距离与函数变量的距离存在一个上界关系。所以\(f\)又称为收缩映射,K(若<1)称为Lipschitz常数。而Lipschitz连续性如果存在,训练时将将不会出现梯度爆炸的情况,由于Lipschitz连续性可以限制梯度,防止梯度爆炸。而WGAN使用的是剪裁的方法,权值剪裁可以保证1-Lipschitz连续性,但是效果不太好。权值剪裁可能导致权值的集中化。
GAN实现过程中的一些问题
- 分类器过强导致gan_v2在无法判断终止的情况下,分类器一直进行训练,导致分类器的loss减到0.0001左右,而生成器的loss上涨到10左右。这样导致了生成器生成的图片完全为黑色图。
- 之前WGAN的训练效果并不好,没有直接GAN的训练效果好。
- 原因是:使用的网络结构根本不需要那么复杂。之前使用了奇怪的:卷积 + upsample结构。最后一层输出还使用了并联两个大小卷积核输出结果的方法,导致训练慢。
- 将网络全部替换成全连接层,训练600个Batch之后就已经可以看出数字的形状了,但训练batch增加并没有显著导致外围的高斯噪声减少,个人认为这是由于全连接层特性决定的。
- 于是我尝试将全连接层的输出层替换为3 * 3的卷积网络。卷积输出会导致模糊,3 * 3卷积网络模糊减退十分慢。在参考了GAN training tricks之后,将3 * 3 kernel替换为 5 * 5 kernel,最后得到了平滑结果,外围噪声可以完全消除,网络输出具有平滑度。
- WGAN 的 clipping parameter对输出的影响也比较大,当clipping parameter比较大的时候输出直接变成了奇怪的浮雕。