Contrastive Learning Intros
CL
I. Introduction
根据个人粗浅的了解,有监督的简单图像分类在高一些奇怪的东西,比如我觉得Inception就很奇怪,强行变宽,更不要说它的改进了。新的网络结构感觉就是,没什么理论道理,全是 empirical xxxx的,让人看得一头雾水,做这样的浅层次理解或者是复现也没有什么太大意思,只能让Pytorch技术更加熟练罢了,没有别的作用。为了寻找新的有趣理论,我入门了一下无监督学习(入门水准),这个领域里面有些很有趣的理论以及思想值得借鉴。本文在回顾了一下一些概率论理论之后,内容主要有:
- Contrastive Predictive Coding (CPC) 论文的理解
- 何恺明大神(同样姓何为何我这么菜)Momentum Contrast (MoCo) 论文的理解
- MoCo实现以及与基于ResNet思想的baseline模型比较(实现见:🔗Enigmatisms/MoCo)
II. 两个曾经的SOTA
2.1 NCE?
在之前我们已经介绍了CL的工作原理:对输入数据进行encode,在某一个高维metric space下对两个输入encode后的特征向量进行相似度比较。给定正负样本(正负样本的获得是无监督的)后,我们需要通过训练集来优化我们的encoder,使得经过encode之后,原空间下就相似的样本能在变换后也十分相似(表现在内积上)。那么这就要求我们使用一个loss来优化encoder,论文中使用的是InfoNCE。
注意,NCE不是 negative cross entropy!(这是开始时本人认为的东西)。但是既然那么有缘,还是复习一下NCE相关的知识。
首先简单地回忆一下交叉熵与KL散度(长时间不用就容易忘),首先是信息熵(与最小编码有关) \[ \begin{equation}\label{ent} H(x)=-\sum p(x)\log\left(p(x)\right) \end{equation} \] 而KL散度的定义是: \[ \begin{equation}\label{kl} D_{KL}(P||Q)=\sum P(x)\log\frac{P(x)}{Q(x)} \end{equation} \] 在之前的一些博文中我们分析过,KL散度是用来衡量两个分布的近似程度的。
原始的信息论问题是:对于两个不同概率分布的字母表P, Q,如果已经在Q上计算出了最优编码,那么只要字母表P的分布越接近Q,那么编码整个字母表P所需的平均信息就越接近Q的理论最小值。显然,这个问题的推广就是衡量两个分布的近似性。
而交叉熵可以用KL散度来定义(Wiki上说的): \[ \begin{equation}\label{ce} \text{CE}(x)=H(p)+D_{KL}(p||q)=-\sum P(x)\log{Q(x)} \end{equation} \] 那么请问此式的意义应该如何解读?由于\(P(x),Q(x)\)都是概率分布,越接近1则\(-\log f(x)\)越小,那么以下两种极端情况可以定性解释这个loss的正确性:
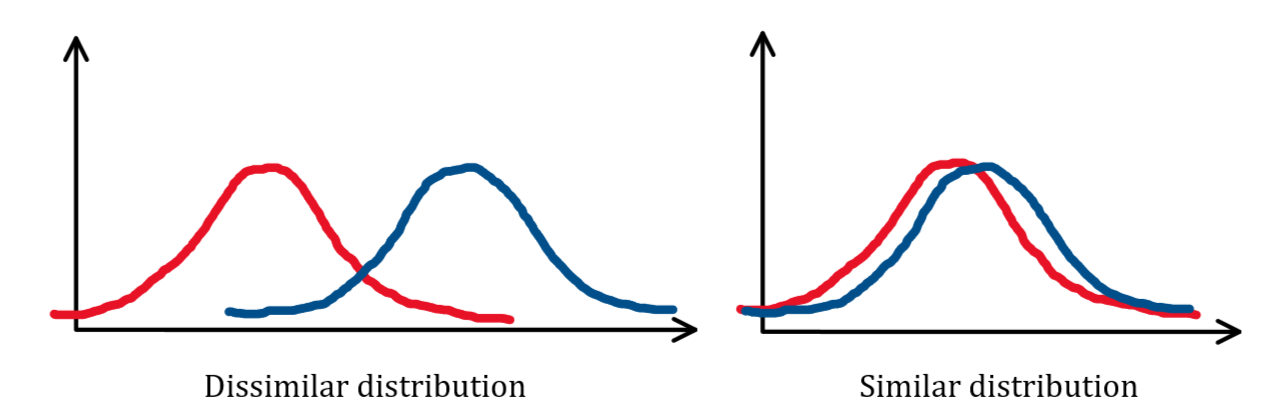
如果如上左图,两个分布相差较大,那么会有这样的情况:\(-\log Q(x)\)较大时(也就是\(Q(x)\)较小),\(P(x)\)恰好较大,相当于对大值,加大权重。那么最后的loss很大。如果分布较为相似,那么则相反,对大值加小权,对小值加大权,这样得到的loss很小,也就直观上说明了Cross Entropy的作用方式。而二分类中,交叉熵的写法如下: \[ \begin{equation}\label{cel} \text{CEL}(x)=-(y\log(p)+(1-y)\log(1-p)) \end{equation} \] 为什么会是这样的呢?显然,二分类情况下,只有错分才会有loss。根据交叉熵表达式\(\eqref{ce}\),假定\(P(x)\)是真实分布,\(Q(x)\)是估计分布。
讲完了CE,要来讲讲真正的NCE与InfoNCE是什么了,在这里我只简要说说,因为我也是查出来的(精力有限,不能过分地递归学习),知乎上有篇文章讲得还行[1]。在这个文章中,作者开始就从NLP切入,我觉得这个切入点还不错,因为NLP中很多问题都是和序列有关的,于是存在这种:context,通过context来进行推断的语言模型之类的东西。那么InfoNCE的作用原理是什么?首先给出公式: \[ \begin{equation}\label{infonce} L_q=-\log\frac{\exp(q\cdot k_{+}/\tau)}{\sum_{i=0}^K\exp{(q\cdot k_i/\tau})} \end{equation} \] 其中,\(k_+\)是与query \(q\) 能够match的正sample key。其余的都是负sample key。可以发现这种 Q K V 设计还是非常普遍的,对每一个需要使用的value,都存在一个对应的key,以应对不同query,虽然在CL问题中没有显式的value,因为value就是key。
那么上式就是一个负对数表达,因为概率越小 loss越大。在MoCo中,个人的理解是:由于MoCo的queue以及momentum update设计,使得key dictionary相对不变,提供的key相对稳定,在假设key正确的情况下,需要找到一个好的encoder参数\(f_q\)使得产生的\(q\)能够与其中一个key完成匹配。不过这个\(k_{+}\)的选取倒是没有说过。
2.2 InfoNCE in CPC
CPC[3]论文中明确定义了InfoNCE(应该是首次出现)。这篇文章的理论部分更加清楚,并且用到了一些概率论知识,我重点理解和推导一下。首先需要搞清楚的是:什么是context,关于context,CPC论文中说了它具体的产生:
Next, an autoregressive model gar summarizes all z≤t in the latent space and produces a context latent representation ct = gar(z≤t).
那么可以认为,context实际上就是对一个序列信息(或者有顺序关联性的信息),前述信息的一个提炼,相当于提供了一个背景。CPC后文中提到的使用上下文指导的prediction,可以佐证这样的理解:context信息就是生成对应prediction的背景信息,只有给定背景,predict才不会漫无目的地乱猜。于是才会有两种不同的概率:
- 条件概率\(P(x_{t+k}|c_t)\),\(c_t\)可以认为是截止到t时刻的上下文信息,\(x_{t+k}\)是一个正样本(为什么?等会儿说)(prediction),或者就如论文自己说的:理解成一个生成式模型,根据latent vector \(c_t\)来生成prediction的一个分布模型
- 直接概率\(P(x_{t+k})\)则是被预测量的分布,是我们想知道的那个分布吗?并不是这样理解的,论文中自己说到了:
N-1 negative samples from the ’proposal’ distribution \(p(x_{t+k})\)
这个\(P(x_{t+k})\)就是我们随机采样的 噪声建议分布。
当时觉得,诶有点似曾相识。当我看到论文中写到importance sampling以及"proposal distribution"的时候我感觉,坏了,开始有点像粒子滤波了。那么可以结合起来理解,只需要简单回顾一下重要性采样即可。
回顾一下重要性采样,也就是“建议分布 (proposal) ”如何转向“目标分布”
假设我们需要计算关于\(f(x)\)的某个积分(比如期望),但是要么\(f(x)\) 是高维复杂分布,要么\(f(x)\)难以积分,总之就是不方便从此分布中直接采样,而同时我们又有另一个简单的分布\(g(x)\),那么有: \[ \begin{equation}\label{imp} \int f(x)dx=\int\frac{f(x)}{g(x)}g(x)dx \end{equation} \] 相当于是:我们在求\(g(x)\)的某个积分,对应的随机变量函数是\(f(x)/g(x)\),在粒子滤波中是有相应应用的。那么\(f(x)/g(x)\)看起来还是和\(f(x)\)有关,是不是也很难求呢?在粒子滤波里面我们已经说明了,这个值并不难求,\(f(x)/g(x)\)相当于对建议分布\(g(x)\)的一个加权因子,这个加权因子由建议分布和目标分布的一致性决定,在localization问题中,我们通过粒子在对应位置模拟的scan与实际scan的相似度估计出了这个值,粒子滤波妙就妙在这里。我不需要知道任何与\(f(x)\)有关的计算公式,我也可以巧妙地设计加权因子求出与\(f(x)\)相关的值。
而在CPC论文中,作者希望的应该是最大化\(x_{t+k}\)与上下文\(c_t\)的互信息: \[ \begin{equation}\label{info} I(x,c)=\sum_{x,c}p(x,c)\log\frac{p(x|c)}{p(x)} \end{equation} \] 作者显式地去建模\(p(x|c)/p(x)\),并且作者使用的这个比值不一定需要有归一化属性,只需要建模一个函数\(f(x)\)与\(p(x|c)/p(x)\)成正比即可。关于公式\(\eqref{info}\),作者自己是这么说的:
By using a density ratio \(f(x_{t+k},c)\) and inferring $ {z_{t+k}}$ with an encoder, we relieve the model from modeling the high dimensional distribution \(x_{t+k}\). Although we cannot evaluate p(x) or p(x|c) directly, we can use samples from these distributions, allowing us to use techniques such as Noise-Contrastive Estimation and Importance Sampling that are based on comparing the target value with randomly sampled negative values.
确实,作者没有用生成式模型去直接建模概率分布,而是使用类似重要性采样的方式去保证互信息可以得到尽可能大的值。
2.3 CPC/MoCo的基本思想
是啊,理论很妙,是啊。。。但是?他们用这些理论在干什么来着?推了那么久公式,我们仿佛忘记了他们的目标究竟是什么。注意CPC中使用了NCE(Noise Contrastive Estimation),并且也要记住,这种无监督的对比学习方法核心就在于【对比】。那么和谁对比?噪声分布的数据对比,所以会有NCE。
- \(P(x_{t+k}|c_t)\)是根据上下文进行的采样,采样得到的结果就是正样本
- \(P(x_{t+k})\)是负样本的来源分布
最大化正样本和负样本之间的互信息(衡量两个随机变量的独立性,或者说观察其中一个变量可以得到另一个变量的信息)。这里是在最大化\(x_{t+k}\)与\(c_t\)这两个随机变量的互信息,我们希望,根据上下文信息\(c_t\)就能很好地对\(x_{t+k}\)进行预测。但是在对比学习里面,预测并不是我们的目的。个人认为,对比学习的目的应该是:
为了更好地区分正负样本,需要一个特征向量提取器,将所有输入映射为某个metric space中的一些向量。将这些向量用在下游任务上,比如用一个简单的MLP接受CL输出的向量的输出进行分类。(我在写这个的时候,我还完全没有实现过,并且也没有看到两篇论文的实验部分)。
为了实现以上目的,两篇论文使用了不同的方法。
2.3.1 CPC总体思想
CPC最后希望生成encoder或者autoregressive model,来接收一个数据或者是一个数据序列,生成高维表征。CPC对于InfoNCE的优化,实际上是在优化一个交叉熵函数(二分类),由于二分类的交叉熵函数可以被写为:
\[ \begin{equation}\label{infonce2} p(d=i|X,c_t)=\frac{p(x_i|c_t)\prod_{l\neq i}p(x_l)}{\sum_{j=1}^N p(x_j|c_t)\prod_{l\neq j}p(x_l)} \end{equation} \] \(p(x_i|c_t)\prod_{l\neq i}p(x_l)\)表示了当\(x_i\)是从正样本的上下文条件分布中采样得到,而其他的\(x_j\)都是噪声采样时的概率。上式的所有连乘中均缺少本\(p(x_i)\),于是可以很容易写成\({p(x|c)}/{p(x)}\)的形式。写成这个形式就可以使用CPC中对这个比值的建模了。总之也是构建encoder,encoder最终输出\(f(x_{t+k},c_t)\)而中间产生的变量\(z_t\)(隐变量)可以拿去用。
2.3.2 MoCo总体思想
对于CPC而言,其encoder每个minibatch都会更新,变化很快,可能就是属于MoCo论文中三种分类的第一种。
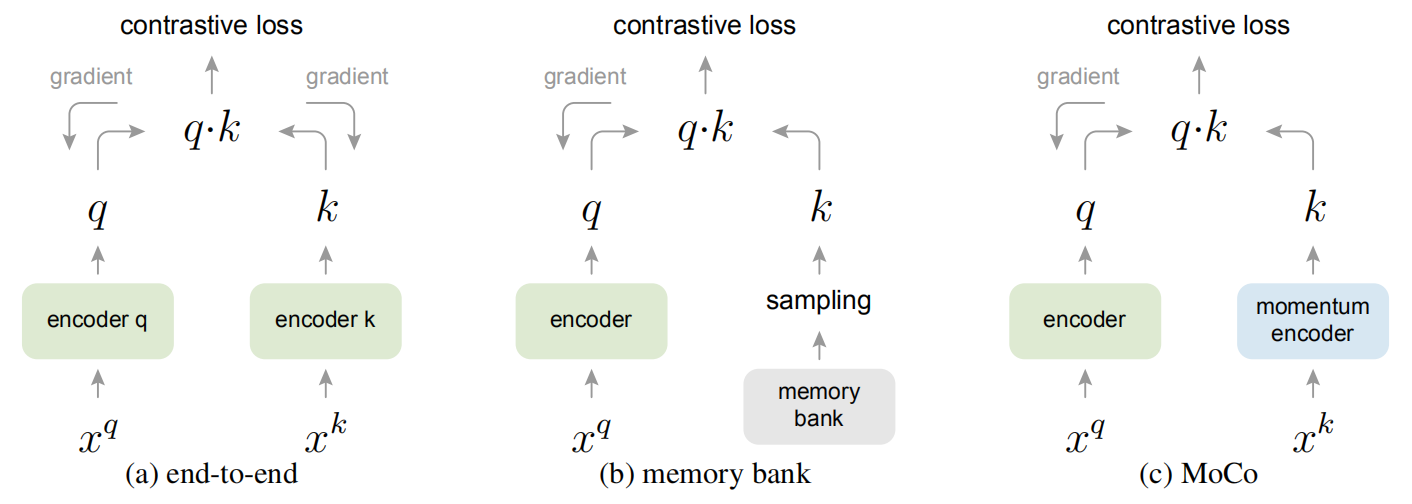
为了避免end2end造成的不稳定性(没有一致性),MoCo的key encoder相当于是在query encoder上做了一个指数平均(低通滤波),使得key encoder的参数变化很平滑。使得更新具有一致性。MoCo其他方面的基本思想与CPC也类似:
- 对一个batch中的每一张图片,自身的增强为正样本,其他图片的增强为负样本
- 优化InfoNCE定义的函数:使得正样本最能被正确区分出来
- 使用query encoder的参数缓慢更新key encoder,并且key encoder不参与反向传播
III. 实现 - MoCo
Momentum contrast 的实现非常简单,论文中也提供了pseudo code,所以在实现过程中并没有遇到什么十分困难的问题。我倒是在训练过程中遇上了一些问题。首先,我实现了一个Encoder(轻量级的具有一些Residual Blocks的网络),结构大概是这样的:

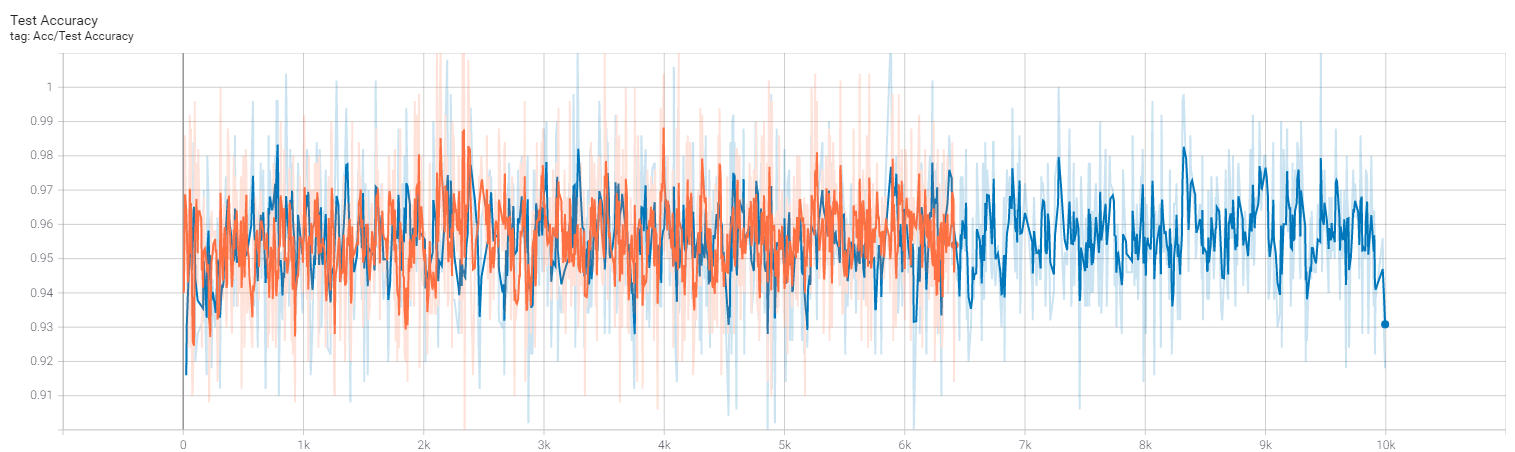
因为我料到我可能跑不动论文里说的ResNet50以及ImageNet的巨大数据集,所以我针对CIFAR10设计了一个无监督pretext task。本来就是打算用这个网络结构当encoder来跑MoCo,但是发现,这个网络会使得loss一直卡在一个值上不动(极其长的时间,长到我没有耐心等待)并且波动很小。我怀疑这不能成功地训练,所以用这个网络直接做了一个Baseline训练了一下,emmm,结果很不错:大约96%的测试集准确率,虽然我不知道这是怎么算出超过1来的。不过训练集的准确率有时甚至可以达到1.00,说明这个网络还是有能力做好分类的。
我最后因为受不了垃圾MX150显卡,跑去租了一个云电脑。很爽啊,推荐【智星云】✨。租了一个这玩意:

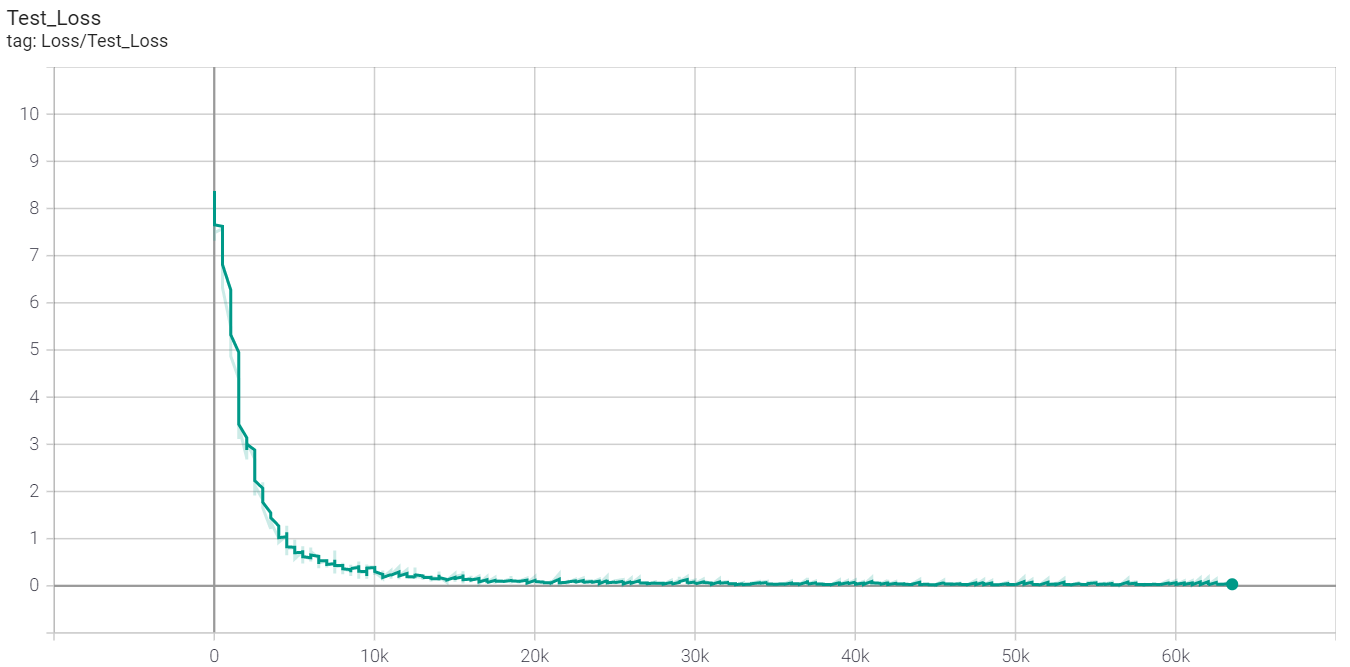
3.5元1h,不知道算不算便宜。我知道这个设备肯定能跑更强的网络,于是用torchvision内置的ResNet18(没有预训练)+一个从1000到128的ReLU FC层,训练了200个epochs,batch size为100。确实还挺快的,1秒多一个batch,要我的渣机跑可能得10s一个batch。训练的Loss结果如下。这个loss就比较符合预期了。
随后,使用这个训练好的Encoder,固定参数进行下游任务:有监督的MLP分类训练。MLP结构是128->64->64->32->10。结果挺 拉的💢,完全比不上Baseline,不知道为什么,个人觉得可能有几个tricks没用:
- loss是单向的,也就是说,生成出的q就当q用,k就当k用,只存k不存q,虽然q,k是不同的两次transform,但是没有做反向的loss
- Shuffle BN,整个resnet内部都使用了BN,作者说直接使用BN是不好的
- 反正最后的结果也就是50%的样子,太拉了。
